
Package Management
dpkg
管理软件包
dpkg 意即 Debian 包管理器(Debian PacKaGe manager)。dpkg 是一个可以安装、构建、删除及管理 Debian 软件包的命令行工具。
其它的一些工具如 dpkg-deb 和 dpkg-query 等使用 dpkg 作为执行某些操作的前端。
现在大多数系统管理员使用 Apt、Apt-Get 及 Aptitude 等工具,不用费心就可以轻松地管理软件。
尽管如此,必要的时候还是需要用 dpkg 来安装某些软件。
常见命令及文件位置
dpkg 命令的语法:
dpkg [<option> ...] <command>
dpkg 相关文件的位置在 /var/lib/dpkg
/var/lib/dpkg/status 包含了被 dpkg 命令(install、remove 等)所修改的包的信息
/var/lib/dpkg/status 包含了可用包的列表
安装/升级软件
在基于 Debian 的系统里,用以下命令来安装 .deb 软件包。要是已经安装了软件包,就会升级它。
sudo dpkg -i package.deb
从文件夹里安装软件
在基于 Debian 的系统里,用下列命令从目录中逐个安装软件。这会安装 /opt/software 目录下的所有以 .deb 为后缀的软件。
sudo dpkg -iR /opt/software
显示已安装软件列表
以下命令可以列出 Debian 系的系统中所有已安装的软件,同时会显示软件版本和描述信息。
dpkg -l
查看指定的已安装软件
用以下命令列出指定的一个已安装软件,同时会显示软件版本和描述信息。
dpkg -l package
查看软件安装目录
以下命令可以在基于 Debian 的系统上查看软件的安装路径。
dpkg -L package
查看 deb 包内容
下列命令可以查看 deb 包内容。它会显示 .deb 包中的一系列文件。
dpkg -c package.deb
显示软件的详细信息
以下命令可以显示软件的详细信息,如软件名、软件类别、版本、维护者、软件架构、依赖的软件、软件描述等等。
dpkg -s package
查看文件属于哪个软件
用以下命令来查看文件属于哪个软件。
dpkg -S /path/file
移除/删除软件
以下命令可以用来移除/删除一个已经安装的软件,但不删除配置文件。
sudo dpkg -r package
清除软件
以下命令可以用来移除/删除包括配置文件在内的所有文件。
sudo dpkg -P package
Debian 打包入门
deb包本身有三部分组成:
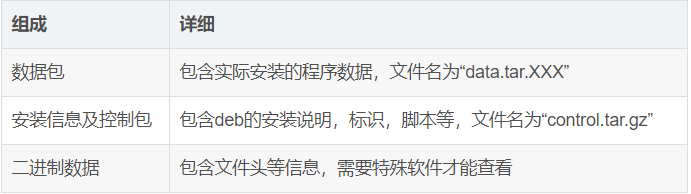
注:原文写的不是很好,具体学习还是看官方的 Debian 新维护者手册
Cardbook 是用于管理基于 CardDav 和 vCard 标准的联系人的Thunderbird扩展。
使用 dh_make 在当前目录下创建一个 debian 目录。
$ dh_make\
--native \
--single \
--packagename cardbook_1.0.0 \
--email minkush@example.com
一些重要的文件,比如 control、rules、changelog、copyright 等文件被初始化其中。所创建的文件的完整列表如下:
$ find debian
debian
debian/manpage.sgml.ex
debian/cardbook.doc-base.EX
debian/changelog
debian/control
debian/postrm.ex
debian/postinst.ex
debian/source
debian/source/format
debian/README.Debian
debian/manpage.1.ex
debian/salsa-ci.yml.ex
debian/rules
debian/cardbook.cron.d.ex
debian/README.source
debian/preinst.ex
debian/prerm.ex
debian/copyright
debian/cardbook-docs.docs
debian/README
debian/manpage.xml.ex
在当前目录执行 dpkg-buildpackage -us -uc -ui 将会在上层目录创建一个空的包文件以及四个名为 .changes、.deb、 .dsc、 .tar.gz 的文件。
.dsc文件包含了所发生的修改和签名.deb文件是用于安装的主要包文件。.tar.gz(tarball)包含了源代码。
这个过程也在 debian/cardbook/usr/share/doc/cardbook 目录下创建了 README 和 changelog 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
检查这个包安装的内容:
$ dpkg -c cardbook_1.0.0_amd64.deb
/usr
/usr/share
/usr/share/doc
/usr/share/doc/cardbook
/usr/share/doc/cardbook/README.Debian
/usr/share/doc/cardbook/changelog.gz
/usr/share/doc/cardbook/copyright
build-essential
在 Ubuntu 中安装构建基础包(build-essential),只需要在终端中简单输入这个命令:
sudo apt update && sudo apt install build-essential
构建基础包(build-essential)实际上是属于 Debian 的。在它里面其实并不是一个软件。它包含了创建一个 Debian 包(.deb)所需的软件包列表。这些软件包包括 libc、gcc、g++、make、dpkg-dev 等。构建基础包包含这些所需的软件包作为依赖,所以当你安装它时,你只需一个命令就能安装所有这些软件包。
请不要认为构建基础包是一个可以在一个命令中神奇地安装从 Ruby 到 Go 的所有开发工具的超级软件包。它包含一些开发工具,但不是全部。
Package converter
- alien:Alien is really designed to be used to convert from alien file formats to the packaging format used by the distribution you run it on.
- gentoo-zh:gentoo 本质是通过 bash 安装软件,因此,可以参考此仓库尝试手动安装软件。
Is linux binary universal to all kinds of distributions?
This is two questions:
Is a Linux binary universal to all distributions?
It depends:
- If the program is using nothing outside the Linux kernel, it will be universal except for the 32- or 64-bit question. A Linux “hello world” (a minimalistic program that just prints “hello world” to a terminal window) could probably be independent of the distribution.
- If the program is using any non-kernel library or service (which is most of Linux, the kernel is fairly small), there are differences in which libraries are included, which versions these libraries are and where they are located. So in this (most common) case distributions are not equal.
Why do many commercial programs say that they only work on one or a few distributions?
Because there is a very large number of Linux distributions, and nobody wants to test their program on all of them.
A commercial vendor will normally say that they support only the distributions they have tested their software on. It may or may not work on other distributions, from the vendor’s perspective the point is just that you can’t complain if it does not work on a distribution they don’t support.
Which distributions are selected for testing depends on what the vendor expects their customers to be using. Commercial/professional programs commonly pick enterprise distributions, possibly through a reasoning similar to “people who paid for their OS are more likely to pay for our software”, possibly simply by counting the distributions used by their existing customers.
See also Mark Shuttleworth (the guy that is the reason we have an Ubuntu in the first place) on [binary compatibility between Ubuntu and Debian](https://wiki.ubuntu.com/MarkShuttleworth#What about binary compatibility) - Debian is the closest distribution relative of Ubuntu.
APT
Debian 使用一套名为 Advanced Packaging Tool(APT)的工具来管理包系统。在基于 Debian 的 Linux 发行版中,有各种工具可以与 APT 进行交互,以方便用户安装、删除和管理的软件包。apt-get 便是其中一款广受欢迎的命令行工具,但是最常用的命令都被分散在了 apt-get、apt-cache 和 apt-config 这三条命令当中,apt 命令的引入就是为了解决命令过于分散的问题。(简单来说就是:apt = apt-get、apt-cache 和 apt-config 中最常用命令选项的集合)
| apt 命令 | 取代的命令 | 命令的功能 |
|---|---|---|
| apt install | apt-get install | 安装软件包 |
| apt remove | apt-get remove | 移除软件包 |
| apt purge | apt-get purge | 移除软件包及配置文件 |
| apt update | apt-get update | 刷新存储库索引 |
| apt upgrade | apt-get upgrade | 升级所有可升级的软件包 |
| apt autoremove | apt-get autoremove | 自动删除不需要的包 |
| apt full-upgrade | apt-get dist-upgrade | 在升级软件包时自动处理依赖关系 |
| apt search | apt-cache search | 搜索应用程序 |
| apt show | apt-cache show | 显示装细节 |
| apt list | 列出包含条件的包(已安装,可升级等) | |
| apt edit-sources | 编辑源列表 |
列出所有手动安装软件
apt-mark showmanual
查看软件包依赖
当你在 Linux 中安装一个软件包,有时这个软件包还需要其他的软件包来使它工作正常。这些额外的软件包就叫作这个包的依赖。假如这些软件包之前没有在系统中被安装,那么这些依赖在安装这个软件包的同时会被自动安装上。
使用 apt show 来查看依赖
你可以使用 apt show 命令 来展示一个包的详细信息。其中依赖信息就是其中一部分,你可以在以 “Depends” 打头的那些行中看到它们。
例如,下面展示的是使用 apt show 展示 ubuntu-restricted-extras 这个包的详细信息:
$ apt show ubuntu-restricted-extras
Package: ubuntu-restricted-extras
Version: 67
...
Depends: ubuntu-restricted-addons
Recommends: libavcodec-extra, ttf-mscorefonts-installer, unrar
...
如你所见,ubuntu-restricted-extras 包依赖于 ubuntu-restricted-addons 这个软件包。
但你得小心的是依赖包还可能依赖于其他包,这样一直循环往复直到尽头。但幸好 APT 包管理器可以为你处理这些复杂的依赖关系,自动地安装所有的依赖(大多数情况下)。
什么是推荐包?
你注意到了上面结果输出中以 “Recommends” 开头的那些行了吗?
推荐包不是软件包的直接依赖,但它们可以开启软件包的一些额外功能。
正如你上面看到的那样, ubuntu-restricted-extras 包有 ttf-mscorefonts-installer 这个推荐包,用来在 Ubuntu 上安装 Microsoft 的字体。
这些推荐包也会默认被一同安装上,假如你想显式地禁止这些推荐包的安装,你可以像下面这样使用 –-no-install-recommends 选项。
sudo apt install --no-install-recommends package_name
使用 apt-cache 来直接获取依赖信息
上面通过 apt show 的方式会获取到大量信息,假如你想在脚本中获取到依赖信息,那么 apt-cache 命令将会给你一个更好且更简洁的输出结果。
apt-cache depends package_name
使用 dpkg 来查看一个 DEB 文件的依赖
apt 和 apt-cache 都作用于软件仓库中的软件包,但假如你下载了一个 DEB 文件,那么这两个命令就不起作用了。
在这种情形下,你可以使用 dpkg 命令的 -I 或 --info 选项。
dpkg -I path_to_deb_file
依赖信息就可以在以 “Depends” 开头的那些行中找到。
使用 apt-rdepends 来查看依赖及依赖的依赖
假如你想查看更多关于依赖的信息,那么你可以使用 apt-rdepends 工具。这个工具可以创建完整的依赖树。这样你就可以得到一个软件包的依赖以及这些依赖的依赖。
它不是一个常规的 apt 命令,所以你需要从 universe 软件仓库中安装上它:
sudo apt install apt-rdepends
这个命令的输出通常很多,取决于依赖树的大小。
eading package lists... Done
Building dependency tree
Reading state information... Done
shutter
Depends: procps
Depends: xdg-utils
imagemagick
Depends: imagemagick-6.q16 (>= 8:6.9.2.10+dfsg-2~)
imagemagick-6.q16
Depends: hicolor-icon-theme
Depends: libc6 (>= 2.4)
Depends: libmagickcore-6.q16-6 (>= 8:6.9.10.2)
Depends: libmagickwand-6.q16-6 (>= 8:6.9.10.2)
hicolor-icon-theme
libc6
Depends: libcrypt1 (>= 1:4.4.10-10ubuntu4)
Depends: libgcc-s1
libcrypt1
Depends: libc6 (>= 2.25)
apt-rdepends 工具的功能非常多样,它还可以用来计算反向依赖。这意味着你可以查看某个特定的包被哪些软件包依赖。
apt-rdepends -r package_name
输出可能会非常多,因为它将打印出反向依赖树。
$ apt-rdepends -r ffmpeg
Reading package lists... Done
Building dependency tree
Reading state information... Done
ffmpeg
Reverse Depends: ardour-video-timeline (>= 1:5.12.0-3ubuntu4)
Reverse Depends: deepin-screen-recorder (5.0.0-1build2)
Reverse Depends: devede (4.15.0-2)
Reverse Depends: dvd-slideshow (0.8.6.1-1)
Reverse Depends: green-recorder (>= 3.2.3)
Repository Mirror
You can use deb mirror to have the best mirror picked for you automatically.
apt-get now supports a ‘mirror’ method that will automatically select a good mirror based on your location. Putting:
deb mirror://mirrors.ubuntu.com/mirrors.txt precise main restricted universe multiverse
deb mirror://mirrors.ubuntu.com/mirrors.txt precise-updates main restricted universe multiverse
deb mirror://mirrors.ubuntu.com/mirrors.txt precise-backports main restricted universe multiverse
deb mirror://mirrors.ubuntu.com/mirrors.txt precise-security main restricted universe multiverse
on the top in your /etc/apt/sources.list file should be all that is needed to make it automatically pick a mirror for you based on your geographical location.
There are many command line tools available to find the best APT mirrors based on download speed. I have tested the following tools and they are working just fine in my Ubuntu 20.04 LTS desktop.
- Apt-select
- Apt-smart
apt-fast
apt-fast: A shellscript wrapper for apt that speeds up downloading of packages.
$ sudo apt-get install aria2
$ sudo add-apt-repository ppa:apt-fast/stable
$ sudo apt-get update
$ sudo apt-get -y install apt-fast
$ sudo nano /etc/apt-fast.conf
MIRRORS=('https://mirrors.bfsu.edu.cn/ubuntu/,https://mirrors.tuna.tsinghua.edu.cn/ubuntu/')
apt-aria2
#!/bin/bash
## apt-aria2: To help download packages faster via aria2, instead of wget.
## Author: Anjishnu Sarkar
## Version: 0.5
## Acknowledgement: This script is a rewrite of the apt-fast script by
## Matt Parnell (admin@mattparnell.com) (http://www.mattparnell.com)
## Usage: Same as apt-get. Using the option "-y" always.
## BUG:
## *) If this script is interuppted, then next time aria2 starts downloading
## the same from the begining. Can be solved - something to do with .st file.
## TODO:
## *) Start installing via apt-get as soon as first package is downloaded
## and also keep downloading at the same time. This however might lead
## to dependencies not being satisfied.
## Initialization(s):
Download="False"
Install="True"
Confirm="True"
UniqueName="$RANDOM"
Options="$@"
## Checking for commands which requires download
while test -n "${1}"
do
case "${1}" in
install|upgrade|dist-upgrade|source|build-dep)
## Download
Download="True"
;;
update|remove|autoremove|purge|dselect-upgrade|clean|autoclean|check)
## Anything other than download
Download="False"
;;
-d) ## Download only (don't install)
Install="False"
;;
-y) ## No need to ask for confirmation
Confirm="False"
;;
*)
## Nothing to be done. If any wrong options/commands are given then
## let apt-get handle it.
;;
esac
shift
done
## In case download is true
if [ "$Download" == "True" ];then
## Installing pre-requisite(s): aria2
if ! which aria2c > /dev/null; then
echo "Aria2 not installed. Installing aria2 first via apt-get"
apt-get -y --force-yes install aria2
fi
ArchiveDir=/var/cache/apt/archives/
cd ${ArchiveDir}/partial
PrintUris=$(apt-get --yes --print-uris ${Options})
if [ $? -ne 0 ];then
echo "Aborting."
exit 1
fi
PackageInfo=$(echo "$PrintUris" | awk '/Reading package/,/After this operation/')
# echo "$PrintUris" | grep ^\' | cut -d\' -f2 > "$UniqueName"-uris.txt
echo "$PrintUris" | grep "http:" | cut -d\' -f2 > "$UniqueName"-uris.txt
NumberOfPackages=$(wc -l "$UniqueName"-uris.txt | awk '{print $1}')
## Print info
echo "$PackageInfo"
echo "Number of packages to be downloaded: $NumberOfPackages"
## Check whether package has already been installed or not
InstallUpgradeMsg=$(echo "$PackageInfo" | grep \
-e "The following NEW packages will be installed:" \
-e "The following packages will be upgraded:")
if [ -z "$InstallUpgradeMsg" ];then
rm -f "$UniqueName"-uris.txt
exit 0
fi
## In $InstallUpgradeMsg is not null, then proceed...
## If confirm is true
if [ "$Confirm" == "True" ];then
echo -n "Do you want to continue [y|n]? "
read Ans
case "$Ans" in
y|yes|"") ;;
n|no|*) echo "Abort."
rm -f "$UniqueName"-uris.txt
exit 1 ;;
esac
fi
if [ $NumberOfPackages -ne 0 ];then
## Downloading the packages
echo "Proceeding with downloading ..."
while read DebUrl
do
DebName=$(basename "$DebUrl")
echo "$DebName"
AptConf="/etc/apt/apt.conf"
if [ -f "$AptConf" ];then
http_proxy=$(grep -i "http::proxy" "$AptConf" | cut -d \" -f2)
fi
if [ -n "$http_proxy" ];then
echo "Using proxy..."
aria2c -c -s 10 -j 10 --http-proxy=$http_proxy "$DebUrl"
else
echo "Not using proxy..."
aria2c -c -s 10 -j 10 "$DebUrl"
fi
if [ $? -eq 0 ];then
mv $DebName ${ArchiveDir}
fi
done < "$UniqueName"-uris.txt
fi
rm -f "$UniqueName"-uris.txt
# echo "Installing..."
if [ "$Install" == "True" ];then
apt-get -y --force-yes ${Options}
fi
else
## Cases when download is false
apt-get ${Options}
fi
PPA
软件仓库是一组文件,其中包含各种软件及其版本的信息,以及校验和等其他一些详细信息。每个版本的 Ubuntu 都有自己的四个官方软件仓库:
- Main - Canonical 支持的自由开源软件。
- Universe - 社区维护的自由开源软件。
- Restricted - 设备的专有驱动程序。
- Multiverse - 受版权或法律问题限制的软件。
你可以在 这里 看到所有版本的 Ubuntu 的软件仓库。你可以浏览并转到各个仓库。
这些信息存储在系统的 /etc/apt/sources.list 文件中。如果查看此文件的内容,你就会看到里面有软件仓库的网址。# 开头的行将被忽略。
Ubuntu 不会在官方仓库中立即提供新版本的软件。他们需要一个步骤来检查此新版本的软件是否与系统兼容,从而可以确保系统的稳定性。这意味着它需要经过几周才能在 Ubuntu 上可用,在某些情况下,这可能需要几个月的时间。
为获取最新版本的软件,需要使用 PPA,PPA (Personal Package Archives) 允许开发者上传要构建的 Ubuntu 源包,并通过 Launchpad 作为 apt 的软件仓库发布。
通过如下命令添加 PPA 软件仓库并获取最新版本软件:
sudo add-apt-repository <PPA_info>
sudo apt-get update
sudo apt-get install <package_in_PPA>
当你使用 PPA 时,它不会更改原始的 sources.list 文件。相反,它在 /etc/apt/sources.d 目录中创建了两个文件,一个 .list 文件和一个带有 .save 后缀的备份文件。这是一种安全措施,可以确保添加的 PPA 不会和原始的 sources.list 文件弄混,它还有助于移除 PPA。
开发人员为他们的软件创建的 PPA 称为官方 PPA。但有时,个人会创建由其他开发人员所创建的项目的 PPA。为什么会有人这样做? 因为许多开发人员只提供软件的源代码。
如果 PPA 不适用于你的系统版本,你可以点击应用程序 PPA 页面的 View package details,在这里,你可以单击软件包以显示更多详细信息,还可以在此处找到包的源代码和 DEB 文件。建议 使用 Gdebi 安装这些 DEB 文件 而不是通过软件中心,因为 Gdebi 在处理依赖项方面要好得多。
就安全性而言,很少见到因为使用 PPA 之后你的 Linux 系统被黑客攻击或注入恶意软件。到目前为止,我不记得发生过这样的事件。官方 PPA 可以不加考虑的使用,使用非官方 PPA 完全是你自己的决定。根据经验,如果程序需要 sudo 权限,则应避免通过第三方 PPA 进行安装。
APT Proxy
-
Create a new configuration file named proxy.conf.
sudo touch /etc/apt/apt.conf.d/proxy.conf -
Open the proxy.conf file in a text editor.
sudo vi /etc/apt/apt.conf.d/proxy.conf -
Add the following line to set your HTTP proxy.
Acquire::http::Proxy "http://user:password@proxy.server:port/"; -
Add the following line to set your HTTPS proxy.
Acquire::https::Proxy "http://user:password@proxy.server:port/"; -
Save your changes and exit the text editor. Your proxy settings will be applied the next time you run Apt.
OR create a new file under the /etc/apt/apt.conf.d directory, and then add the following lines.
Acquire {
HTTP::proxy "http://127.0.0.1:8080";
HTTPS::proxy "http://127.0.0.1:8080";
}
OR
sudo -E apt install
OR …
Snap & Flatpak
什么是Snap应用
如果你在使用Ubuntu 18.04/20.04 LTS版本的Ubuntu系统,会发现系统里面多了一个应用格式包——.snap包。Snap包是Ubuntu 16.04 LTS发布时引入的新应用格式包。
当你在安装完snap后,你会发现在在根目录下会出现如/dev/loop0的挂载点,这些挂载点正是snap软件包的目录。Snap使用了squashFS文件系统,一种开源的压缩,只读文件系统,基于GPL协议发行。一旦snap被安装后,其就有一个只读的文件系统和一个可写入的区域。应用自身的执行文件、库、依赖包都被放在这个只读目录,意味着该目录不能被随意篡改和写入。
squashFS文件系统的引入,使得snap的安全性要优于传统的Linux软件包。同时,每个snap默认都被严格限制(confined),即限制系统权限和资源访问。但是,可通过授予权限策略来获得对系统资源的访问。这也是安全性更好的表现。
Snap可包含一个或多个服务,支持cli(命令行)应用,GUI图形应用以及无单进程限制。因此,你可以单个snap下调用一个或多个服务。对于某些多服务的应用来说,非常方便。前面说到snap间相互隔离,那么怎么交换资源呢?答案是可以通过interface(接口)定义来做资源交换。interface被用于让snap可访问OpenGL加速,声卡播放、录制,网络和HOME目录。Interface由slot和plug组成即提供者和消费者。
目前,Ubuntu的相关产品已以snap包的形式发布,例如Ubuntu MAAS,Juju,Multipass,MicroK8s,MicroStack等等。
snap “canonical-livepatch” has “install-snap” change in progress
Snap 包是 Ubuntu 16.04 LTS 发布时引入的新应用格式包。目前已流行在很多 Linux 发行版上。并且可以很方便地安装常用软件,如 VLC、Sublime Text、VSCode、Node、WPS等
当你在安装完 Snap 后,你会发现在在根目录下会出现如 /dev/loop0 的挂载点,这些挂载点正是 Snap 软件包的目录。
-
原因是软件之前安装了一次,只是安装失败。
snap changessnap abort 5 ## 5 为安装失败软件的 ID -
现在重新安装
一些软件最好在官网下载或在 Snap 中下载,官方 Repository 可能并不新,比如 VLC。
Is just a way to indicate that supplementary material is being downloaded.
If one keeps Ubuntu’s system monitor open at the same time, it’s quite evident that “Automatically connect eligible plugs and slots …” means a download is in progress.
所以,解决办法是用 proxychains。
Speed Up Downloading
This simple tutorial shows how to speed up the downloading process of snap application package by associating IP address with the snapcraft server in Ubuntu.
1.) Open terminal either via Ctrl+Alt+T keyboard shortcut or by searching for ‘terminal’ from application menu. When terminal opens, run command:
dig fastly.cdn.snapcraft.io
fastly.cdn.snapcraft.io is deprecated. Get more Snapcraft Download CDNs
In the terminal output, copy the IP address under ‘ANSWER SECTION’.
2.) Then run commands to edit the hosts file:
sudo gedit /etc/hosts
Type user password (no asterisk) when it prompts and hit Enter.
When the files opens in gedit text editor, paste following line:
151.101.42.217 fastly.cdn.snapcraft.io
Replace the IP address with which you got in step 1, and finally save the file.
为Snapd设置代理
Snap,全称SnapCraft,是一个全新的应用软件环境。在Snap中,软件被封装在类似于Docker的容器中,即开即用,可随时获取,这一切由其后台服务snapd提供支持。Ubuntu从18.04开始,就引入它作为系统的一部分,而其他的Linux发行版(如Deepin)也可以通过软件管理工具进行安装(如sudo apt install snapd)。
SnapCraft将软件包分发在自己的服务器上。然而,因为众所周知的原因,访问位于海外的Snap服务器异常缓慢,不加代理的情况下,下载速度会持续降到十几KB每秒。这使得我们不得不想办法通过代理服务器进行加速。
一般地,Linux上的一些应用程序会通过读取环境变量http_proxy和https_proxy来应用代理服务器设置,典型的有Chrome。然而,Snap比较特别,它不会从环境变量中上述环境变量中读取代理服务器设置,因此直接使用export http_proxy=[代理服务器地址]或export https_proxy=[代理服务器地址]是不起作用的。
那么,有何正确的方法?
/etc/environment是一个Shell脚本,snapd会读取它,应用其中指定的配置信息。因此,设置代理服务器的正确目标,实际上就是这里。
在/etc/environment中加入:
http_proxy=http://[服务器地址]:[端口号]
https_proxy=http://[服务器地址]:[端口号]
然后重启snapd服务:
sudo systemctl restart snapd
A system option was added in snap 2.28 to specify the proxy server.
sudo snap set system proxy.http="http://<proxy_addr>:<proxy_port>"
sudo snap set system proxy.https="http://<proxy_addr>:<proxy_port>"
除了修改environment文件,也可以修改snapd服务的配置文件,在其加入Environment信息,信息内容实际上就是“方法一”中设置代理服务器的语句。
运行以下命令,打开snapd的配置文件:
sudo systemctl edit snapd.service
在打开的文本编辑器中,加入以下语句:
[Service]
Environment=http_proxy=http://proxy:port
Environment=https_proxy=http://proxy:port
最后重新加载snapd服务:
sudo systemctl daemon-reload
sudo systemctl restart snapd.service
注意事项
一般的本地代理都不支持HTTPS,所以https_proxy的值也只能是http地址,否则会出现如下错误:
cannot install "conjure-up": Post https://api.snapcraft.io/v2/snaps/refresh: proxyconnect tcp: EOF
Snap 深远意义
近日,Ubuntu推出了Snap应用包格式,受到各主流发行版和软件基金会欢迎.这有何深远意义?
-
farseerfc
首先「受到各主流发行版和软件基金会欢迎」這句可是 Ubuntu 的人說給媒體人的,別的發行版都還沒表態,見我另一個回答
Flatpak 和 Snap package 技术上有何区别?各有何优劣?如何看待两者的发展前景? - fc farseer 的回答
然後,容器技術的重要性和 Linux 上第三方軟件開發商打包困難的問題很多人都提到了,都說得不錯,不再複述。
我就提一下爲什麼 Ubuntu 要做這個,爲什麼 Ubuntu 要在這個時候大張旗鼓推這個。
在操作系統領域幾十年來經久未變的一點是,操作系統本身不重要,重要的是能跑在其上的應用程序,現在的話說是生態環境。而應用程序不是針對操作系統本身撰寫,應用程序是針對操作系統提供的API/SDK撰寫,換句話說,掌握了API/SDK的控制權,就掌握了最寶貴的應用程序開發者,操作系統本身就得以長久發展。這就是爲什麼 Windows 遠比 Mac 賣得好的道理,Windows 掌握着桌面操作系統裏最穩定的SDK,幾十年來保持兼容性未曾變過,而 Mac 時常破壞 API 兼容性使得老程序不能再跑在新系統上。這個道理
How Microsoft Lost the API War
這篇文章闡述得非常明白。
GNU/Linux 乃至整個 FOSS 社區,在這一點上,其實非常另類。 GNU 系統從來沒有把「保持程序兼容性以吸引用戶和開發者」放在首要目標,GNU 的首要目標是「給用戶以自由」。那麼 GNU/Linux 的應用程序兼容性不好麼?並不見得,幾十年前的 ed/vi/xterm 程序現在還好好得跑在 各大發行版上,一些程序比 Windows 上的軟件還要古老很多。但是這並不是 GNU/Linux 和各大發行版致力於保護兼容性的結果,而是這些軟件「自由」的結果。因爲他們自由且開源,發行版維護者們可以拿他們的源代碼重新編譯以利用新的軟件庫新的 ABI ;因爲他們自由而且開源,上游維護者可以不斷更新他們的代碼讓他們適應新的技術新的框架新的 API ;因爲他們自由而且開源,當上游開發者放棄項目不再開發的時候,還會有有志之士挺身而出接替開發維護的職責。換句話說,在 Linux 發行版上,軟件的兼容性好是軟件自由的直接結果。
這就是現在 GNU/Linux 發行版們打包軟件發佈軟件的模式,大家努力的目標是給予用戶自由。這一模式在自由開源軟件上非常有效,但是面對閉源軟件就不那麼有效了。閉源軟件的源代碼在開發者手上,沒有發行版打包者做銜接工作,所以閉源軟件在 GNU/Linux 上發佈起來非常困難。軟件的自由,除了乾淨放心保證隱私外對普通用戶來說沒有立竿見影的優勢,只對軟件開發者們有意義,所以 GNU/Linux 發行版一直是程序員的天堂,用戶的地獄。
而 Ubuntu 作爲一個發行版,並沒有共享傳統發行版的自由精神。從一開始,Ubuntu努力的首要目標就不是給用戶自由,而是擴大普通用戶的基數。Ubuntu看到,對普通用戶而言,閉源軟件尤其是商業軟件同等重要甚至可能更重要,普通用戶寧願忍受不自由,寧願放棄隱私放棄控制權,也不願使用那些表面粗質功能匱乏的開源替代。所以 Ubuntu 需要打破傳統發行版的發佈方式,讓商業閉源軟件也能在 GNU/Linux 上輕鬆發佈。
而且這條路的可行性早就驗證過了。Google 通過給 Linux 內核上包裝一層 Apache 協議的「自由性中立」的 userland 層,禁錮住了 GPL 的病毒傳播性,開發出 Android 系統,發展出 Android 之上的生態環境,吸引到了無數開發者爲其平臺寫(大部分閉源)軟件。另一點 Valve 通過 Steam 作爲兼容層,附帶大量依賴庫並保持 API 足夠穩定,同時充當遊戲開發者和 Steam 兼容層之間的橋樑,也順利地招攬到不少遊戲開發商爲 Steam 移植 Linux 平臺遊戲。這兩個先例都啓迪 Ubuntu ,這件事可以做並且可以做好。
並且現在做 Snap 對 Ubuntu 有一個重大的好處,在於壟斷 SDK 控制權。Snap 架空了發行版提供的包管理器,甚至架空了發行版本身(提供的依賴庫),從而對開發者而言,針對 Snap 提供軟件包就不需要考慮發行版(這是好事)。如果 Snap 受到足夠多的開發者支持,發展出成熟的生態,那麼 Ubuntu 也就不再發愁今後的推廣之路了,因爲 Ubuntu 上的 Snap 支持必然比別的發行版要好。目前 Snap 上發佈或者安裝軟件包需要 Ubuntu One 身份認證,屬於中央化的 App Store 模式,這給予 Ubuntu 最直接的控制權(而不是 Ubuntu 宣稱的把控制權從發行版交還給開發者),到時候 Ubuntu 攜應用以令用戶,用戶並沒有選擇的權利和自由。另一點,Ubuntu要做手機系統做IoT系統,面向的用戶群就是 Android/iOS 的用戶群,這樣的用戶群下,用自由開源的生態在短期內顯然難以抗衡,所以必須引入商業生態,從而提供類似的軟件商店也是 Ubuntu 的必由之路。
最開始的時候,Ubuntu 最大的敵人是微軟,這是它的 launchpad 上第一個 bug
Bug #1 (liberation) “Microsoft has a majority market share†: Bugs : Ubuntu(Ubuntu第一个BUG:微软在新的桌面 PC 市场中占有多数市场份额。这是 Ubuntu 和其他项目旨在修复的错误。)
現在 Ubuntu 和微軟成爲了合作關係,然後矛頭調轉直指一衆發行版,司馬昭之心可以想象。
问题
那用snap不需要依赖了吗?还是自带依赖?
回答
snap沒看懂它準備怎麼搞, flatpak的做法似乎是分成「框架包」和「軟件包」,框架包是類似 gtk3 、qt5 這種非常大的東西,整個作爲一個框架,軟件包依賴框架包,然後自帶一些小的不屬於框架的依賴。
问题
“因爲他們自由而且開源”
请问这里的“自由”的精确含义是什么?
回答
「用户可以自由地运行,拷贝,分发,学习,修改并改进该软件」(什么是自由软件?) 注意自由和開源並不是等價的,有些軟件,比如 kindle 的系統,是完全用 GPL 協議開源的,可以隨意獲取,但是很難修改它的軟件裝到 kindle 上去用。有另一些軟件,雖然沒有用開源協議開源,但是相對能很容易地獲取到源碼並且修改使用,比如很多大學的研究項目可以直接問負責人要到源碼。
-
梦断代码
并不受欢迎啊,基于ubuntu的一大堆发行版,比如mint,zorin,直接不管snap,反而使用flatpak。
说实话,snap挺作死的,当初unity桌面做的好好的,非要砍掉,snap应用却不砍,很迷惑,unity想统一桌面和手机,snap就是新的应用商店,还可以跨电脑和手机,可以说野心很大。可是unity没了,snap留着干嘛?
说是跨发行版,其实它太致命了,它同时支持桌面应用和命令行应用,然而都做的不行,比如neovim,装了snap版的,然而neovim这货又是远程通信支持语言的。比如node.js,同时用snap版的nvim和nodejs会发现nvim根本用不了node.js,因为snap这容器直接把这俩货隔离了。这只是其中一个。桌面应用简直群魔乱舞,wps好几个版本,都是不同人上传的,这不像flathub,flathub有点像github,可以直接像提pr一样给作者提交新版本,而snap,只要某软件作者不维护,你想用新的只能另开一个。
重点是snap还闭源,所以没法搭建镜像,其他厂商想接入也不好接入。
Difference between Snap and Flatpak
Flatpak is designed to install and update “apps”; user-facing software such as video editors, chat programs and more.
snaps can install anything which contains a kernel, printer drivers, audio subsystems and more.
Snap and Flatpak are the software behind two universal Linux app stores: the Snap Store and Flathub.
AppImage Wiki 做得对比图表。
群讨论
openSUSE 群
Flatpak使用bubblewrap来隔离应用程序,bwrap是非常轻量化的沙箱程序,因此攻击面极小。但bwrap需要用户对Linux程序工作方式有准确的了解(使用哪些syscall),Flatpak相当于充当了一个bwrap的前端帮助控制bwrap权限。
目前Flatpak的问题在于seccomp权限太过广泛,但目前Flatpak维护者已经意识到了这个问题(注释:在他们踩了一次坑之后),已经计划打算解决了。
另一个问题是程序请求的权限过于广泛,但这更多是一个决策问题而不是技术问题,而且你可以用Flatseal手动调整权限。
Flatpak你不能用常规程序方式来理解,每个程序都是一个完全独立的空间,只有给予了权限才有对应访问权,也可以用Portals调用文件选择器来获得单独一个文件的完全访问权,Flatpak版的Steam是把所有程序配置文件放在~/.var/app里面了,类似安卓下面的分区存储做法。
AppImage就只是个自挂载程序,自带的文件透明挂载到它自己的根文件系统下面,所以依然依赖主机的一部分库。所以是的,跟打包者用的系统有关系。
Flatpak不是这种机制,每个Flatpak空间是完全空白的,需要打包者自己选择加入哪些东西,所以Flatpak跨发行版的兼容性也更好。
良好打包的AppImage可以有很好的跨发行版兼容性,但是代价就是需要手工测试每个发行版下面的效果。在跨发行版兼容性这点上我更看好Flatpak。
最后,不要跟我提Snap,我不想碰那个东西,也对它没有研究的兴趣。
Flatpak确实有很多可取之处,或者不能说是Flatpak可取,而是Linux桌面软件生态现状决定了,只有更激进的手段才能改变现状。
AppImage那种策略还是过于不痛不痒了,结果就是程序仅仅是被打包成一个个单文件,但背后的库依赖地狱、权限隔离问题一个都没解决。
但AppImage作者的想法本来也不是靠AppImage颠覆,他是希望Linux能够重新恢复LSB,确保发行版之间的兼容性本身可靠而不是依赖Flatpak这些技术,就类似于Windows上的软件不需要什么沙箱模拟器,你几乎可以保证旧版本的软件能在新版本运行。
其实也可以说明,微软那种在桌面上采取的策略,很可能难以在Linux社区里推广开来,微软那种做法,确保绝对的向下兼容性,不是谁都有精力来做的。
比如说如果让微软来做Wayland,那微软根本就不会把Wayland做出来,而是把X11一直迭代、削减臃肿功能直到性能和现代化图形技术栈的性能相匹敌,同时确保向下兼容性。而最新一代的X11很可能和最早的X11已经彻底不一样了,甚至会有“检测程序版本然后自动匹配对应的X11功能”这些奇怪的兼容性策略出来。或许有一天微软会把新项目叫做Wayland,但这个改名也仅仅是营销目的而不是技术目的。
毕竟LSB已经没了,Ubuntu甚至砍掉32位兼容性,也可以说明其实Linux这边并没有太多人在乎这问题。
毕竟“反正源代码都在那,重新编译一遍不就好了吗”
Fedora 群
空のあお, [2/28/22 8:25 PM] 软件有不同版本的依赖 这些依赖很难共存 有些旧版依赖还有更旧的依赖 不说二进制兼容,有些连源码兼容都搞不定 就算搞定了,一段时间过后依赖升级了,还是得坏 flatpak的做法是维护abi稳定的qt和gtk两大ui库和必要桌面库的runtime,用来公用 通过容器隔离app,让每个app自己构建所需的特定依赖到容器里
竹林里有冰, [2/28/22 8:33 PM] sandbox他是用bubblewrap实现的吧,你可以直接使用bubblewrap,应该一样可以做到他的沙盒化,更小巧一点 bubblewrap的缺点就是需要针对每个程序写上配置,除了有点麻烦其他倒还不错
Neomonk Zen, [2/28/22 8:36 PM] 也不知flatpak的软件仓库,有没什么审核机制来防止恶意软件,如果没有的话,那还蛮可怕的,想想Chrome和Android的软件市场,都有很多恶意软件
Robin Lee, [2/28/22 8:39 PM] 没有深入的审核,跟各大发行版的官方包差不多,但flatpak可以限制应用权限
使用 Flatpak
The official Flatpak PPA is the recommended way to install Flatpak. To install it, run the following in a terminal:
sudo add-apt-repository ppa:flatpak/stable
sudo apt update
sudo apt install flatpak
Flathub is the best place to get Flatpak apps. To enable it, run:
sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
To complete setup, restart your system. Now all you have to do is install some apps!
sudo flatpak remote-modify flathub --url=https://mirror.sjtu.edu.cn/flathub
Flathub 中部分软件由于重分发授权问题,需要从官方服务器下载,无法使用镜像站加速。比如 NVIDIA 驱动、JetBrains 系列软件等。
如果您中断了某次安装,重新下载可能会出现找不到文件的问题。您可以使用 flatpak repair 解决相关的问题。
Asian Font Problems with Flatpak
如果你遇到了游戏中无法显示亚洲字体的问题,这是因为 org.freedesktop.Platform 并没有包含合适的字体文件进去。首先尝试挂载你的本地字体:
flatpak run --filesystem=~/.local/share/fonts --filesystem=~/.config/fontconfig com.valvesoftware.Steam
如果上述命令不起作用,考虑动手 hack 一下:直接将字体文件复制进 org.freedesktop.Platform 的目录下以启用字体,例如
# replace ? with your version and hash
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/etc/fonts/conf.avail
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/etc/fonts/conf.d
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/share/fonts
tasksel: Install Group Software
安装
sudo apt install tasksel
list tasks
tasksel --list-tasks
displays description
tasksel --task-desc dns-server
install
sudo apt install dns-server
pacstall
An AUR-inspired package manager for Ubuntu
AppImage
Linux apps that run anywhere
Extract files from an AppImage
unpack: your.AppImage --appimage-extract
Re-package: appimagetool-x86_64.AppImage -v AppDir
解包 AppImage 文件,将 libfcitxplatforminputcontextplugin.so 或 libfcitx5platforminputcontextplugin.so 拷贝到 squashfs-root/usr/plugins/platforminputcontexts 目录下,重新打包。
strings libQt5Core.so.5 | grep "5\."
strings libfcitx5platforminputcontextplugin.so | grep "5\."
包管理器的进化](https://linux.cn/article-9931-1.html)
今天,每个可计算设备都会使用某种软件来完成预定的任务。在软件开发的上古时期,为了找出软件中的 bug 和其它缺陷,软件会被严格的测试。在近十年间,软件被通过互联网来频繁分发,以试图通过持续不断的安装新版本的软件来解决软件的缺陷问题。在很多情况下,每个独立的应用软件都有其自带的更新器。而其它一些软件则让用户自己去搞明白如何获取和升级软件。
Linux 较早采用了维护一个中心化的软件仓库来发布软件更新这种做法,用户可以在这个软件仓库里查找并安装软件。在这篇文章里, 笔者将回顾在 Linux 上的如何进行软件安装的历史,以及现代操作系统如何保持更新以应对软件安全漏洞(CVE)不断的曝光。
手动安装软件
曾几何时,软件都是通过 FTP 或邮件列表(LCTT 译注:即通过邮件列表发布源代码的补丁包)来分发的(最终这些发布方式在互联网的迅猛发展下都演化成为一个个现今常见的软件发布网站)。(一般在一个 tar 文件中)只有一个非常小的文件包含了创建二进制的说明。你需要做的是先解压这个包,然后仔细阅读当中的 README 文件, 如果你的系统上恰好有 GCC(LCTT 译注:GNU C Compiler)或者其它厂商的 C 编译器的话,你得首先运行 ./configure 脚本,并在脚本后添加相应的参数,如库函数的路径、创建可执行文件的路径等等。除此之外,这个配置过程也会检查你操作系统上的软件依赖是否满足安装要求。如果缺失了任何主要的依赖,该配置脚本会退出不再继续安装,直到你满足了该依赖。如果该配置脚本正常执行完毕,将会创建一个 Makefile 文件。
当有了一个 Makefile 文件时, 你就可以接下去执行 make 命令(该命令由你所使用的编译器提供)。make 命令也有很多参数,被称为 make 标识flag,这些标识能为你的系统优化最终生成出来的二进制可执行文件。在计算机世界的早期,这些优化是非常重要的,因为彼时的计算机硬件正在为了跟上软件迅速的发展而疲于奔命。今日今时,编译标识变得更加通用而不是为了优化哪些具体的硬件型号,这得益于现代硬件和现代软件相比已经变得成本低廉,唾手可得。
最后,在 make 完成之后, 你需要运行 make install (或 sudo make install)(LCTT 译注:依赖于你的用户权限) 来“真正”将这个软件安装到你的系统上。可以想象,为你系统上的每一个软件都执行上述的流程将是多么无聊费时,更不用说如果更新一个已经安装的软件将会多复杂,多么需要精力投入。(LCTT 译注:上述流程也称 CMMI 安装, 即Configure、Make、Make Install)
软件包
package(LCTT 译注:下文简称“包”)这个概念是用来解决在软件安装、升级过程中的复杂性的。包将软件安装升级中需要的多个数据文件合并成一个单独的文件,这将便于传输和(通过压缩文件来)减小存储空间(LCTT 译注:减少存储空间这一点在现在已经不再重要),包中的二进制可执行文件已根据开发者所选择的编译标识预编译。包本身包括了所有需要的元数据,如软件的名字、软件的说明、版本号,以及要运行这个软件所需要的依赖包等等。
不同流派的 Linux 发行版都创造了它们自己的包格式,其中最常用的包格式有:
- .deb:这种包格式由 Debian、Ubuntu、Linux Mint 以及其它的变种使用。这是最早被发明的包类型。
- .rpm:这种包格式最初被称作红帽包管理器Red Hat Package Manager(LCTT 译注: 取自英文的首字母)。使用这种包的 Linux 发行版有 Red Hat、Fedora、SUSE 以及其它一些较小的发行版。
- .tar.xz:这种包格式只是一个软件压缩包而已,这是 Arch Linux 所使用的格式。
尽管上述的包格式自身并不能直接管理软件的依赖问题,但是它们的出现将 Linux 软件包管理向前推进了一大步。
软件仓库
多年以前(当智能电话还没有像现在这样流行时),非 Linux 世界的用户是很难理解软件仓库的概念的。甚至今时今日,大多数完全工作在 Windows 下的用户还是习惯于打开浏览器,搜索要安装的软件(或升级包),下载然后安装。但是,智能电话传播了软件“商店”(LCTT 译注: 对应 Linux 里的软件仓库)这样一个概念。智能电话用户获取软件的方式和包管理器的工作方式已经非常相近了。些许不同的是,尽管大多数软件商店还在费力美化它的图形界面来吸引用户,大多数 Linux 用户还是愿意使用命令行来安装软件。总而言之,软件仓库是一个中心化的可安装软件列表,上面列举了在当前系统中预先配置好的软件仓库里所有可以安装的软件。
包管理器
包管理器用来和相应的软件仓库交互,获取软件的相应信息。下面对流行做一个简短介绍。
基于 PRM 包格式的包管理器
更新基于 RPM 的系统,特别是那些基于 Red Hat 技术的系统,有着非常有趣而又详实的历史。实际上,现在的 YUM 版本(用于 企业级发行版)和 DNF(用于社区版)就融合了好几个开源项目来提供它们现在的功能。
Red Hat 最初使用的包管理器,被称为 RPM(红帽包管理器Red Hat Package Manager),时至今日还在使用着。不过,它的主要作用是安装本地的 RPM 包,而不是去在软件仓库搜索软件。后来开发了一个叫 up2date 的包管理器,它被用来通知用户包的最新更新,还能让用户在远程仓库里搜索软件并便捷的安装软件的依赖。尽管这个包管理器尽职尽责,但一些社区成员还是感觉 up2date 有着明显的不足。
现在的 YUM 来自于好几个不同社区的努力。1999-2001 年一群在 Terra Soft Solution 的伙计们开发了Yellowdog Updater(YUP),将其作为 Yellow Dog Linux 图形安装器的后端。杜克大学Duke University喜欢这个主意就决定去增强它的功能,它们开发了Yellowdog Updater, Modified(YUM),这最终被用来帮助管理杜克大学的 Red Hat 系统。Yum 壮大的很快,到 2005 年,它已经被超过一半的 Linux 市场所采用。今日,几乎所有的使用 RPM 的的 Linux 都会使用 YUM 来进行包管理(当然也有一些例外)。
Dandified Yum(DNF)是 YUM 的下一代接班人。从 Fedora 18 开始被作为包管理器引入系统,不过它并没有被企业版所采用,所以它只在 Fedora(以及变种)上占据了主导地位。DNF 的用法和 YUM 几乎一模一样,它主要是用来解决性能问题、晦涩无说明的API、缓慢/不可靠的依赖解析,以及偶尔的高内存占用。DNF 是作为 YUM 的直接替代品来开发的,因此这里笔者就不重复它的用法了,你只用简单的将 yum 替换为 dnf 就行了。
Zypper 是用来管理 RPM 包的另外一个包管理器。这个包管理器主要用于 SUSE(和 openSUSE),在MeeGo、Sailfish OS、Tizen 上也有使用。它最初开发于 2006 年,已经经过了多次迭代。除了作为系统管理工具 YaST 的后端和有些用户认为它比 YUM 要快之外也没有什么好多说的。
基于 Debian 的包管理器
作为一个现今仍在被积极维护的最古老的 Linux 发行版之一,Debian 的包管理系统和基于 RPM 的系统的包管理系统非常类似。它使用扩展名为 “.deb” 的包,这种文件能被一个叫做 dpkg 的工具所管理。dpgk 同 rpm 非常相似,它被设计成用来管理在存在于本地(硬盘)的包。它不会去做包依赖关系解析(它会做依赖关系检查,不过仅此而已),而且在同远程软件仓库交互上也并无可靠的途径。为了提高用户体验并便于使用,Debian 项目开始了一个软件项目:Deity,最终这个代号被丢弃并改成了现在的 Advanced Pack Tool(APT)。
在 1998 年,APT 测试版本发布(甚至早于 1999 年的 Debian 2.1 发布),许多用户认为 APT 是基于 Debian 系统标配功能之一。APT 使用了和 RPM 一样的风格来管理仓库,不过和 YUM 使用单独的 .repo 文件不同,APT 曾经使用 /etc/apt/sources.list 文件来管理软件仓库,后来的变成也可以使用 /etc/apt/sources.d 目录来管理。如同基于 RPM 的系统一样,你也有很多很多选项配置来完成同样的事情。你可以编辑和创建前述的文件,或者使用图形界面来完成上述工作(如 Ubuntu 的“Software & Updates”)。
现今大多数的 Ubuntu 教程里都径直使用了 apt。 单独一个 apt 设计用来实现那些最常用的 APT 命令的。apt 命令看上去是用来整合那些被分散在 apt-get、apt-cache 以及其它一些命令的的功能的。它还加上了一些额外的改进,如色彩、进度条以及其它一些小功能。
基于 Arch 的包管理器
Arch Linux 使用称为 packman 的包管理器。和 .deb 以及 .rpm 不同,它使用更为传统的 LZMA2 压缩包形式 .tar.xz 。这可以使 Arch Linux 包能够比其它形式的压缩包(如 gzip)有更小的尺寸。自从 2002 年首次发布以来, pacman 一直在稳定发布和改善。使用它最大的好处之一是它支持 Arch Build System,这是一个从源代码级别构建包的构建系统。该构建系统借助一个叫 PKGBUILD 的文件,这个文件包含了如版本号、发布号、依赖等等的元数据,以及一个为编译遵守 Arch Linux 需求的包所需要的带有必要的编译选项的脚本。而编译的结果就是前文所提的被 pacman 所使用的 .tar.xz 的文件。
上述的这套系统技术上导致了 Arch User Respository(AUR)的产生,这是一个社区驱动的软件仓库,仓库里包括有 PKGBUILD 文件以及支持补丁或脚本。这给 Arch Linux 带了无穷无尽的软件资源。最为明显的好处是如果一个用户(或开发者)希望他开发的软件能被广大公众所使用,他不必通过官方途径去在主流软件仓库获得许可。而不利之处则是它必须将依赖社区的流程,类似于 Docker Hub、 Canonical 的 Snap Packages(LCTT 译注: Canonical 是 Ubuntu 的发行公司),或者其它类似的机制。
有很多特定于 AUR 的包管理器能被用来从 AUR 里的 PGKBUILD 文件下载、编译、安装。其中 yaourt 和 pacaur 颇为流行。不过,这两个项目已经被 Arch Wiki 列为“不继续开发以及有已知的问题未解决”。因为这个原因,这里直接讨论 aurman,除了会搜索 AUR 以及包含几个有帮助的(其实很危险)的选项之外,它的工作机制和 pacman 极其类似。
conda
简介
Conda 是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 Conda 是为 Python 程序创建的,适用于 Linux,OS X 和 Windows,也可以打包和分发其他软件。
安装
conda分为anaconda和miniconda。anaconda是包含一些常用包的版本(这里的常用不代表你常用),miniconda则是精简版,需要啥装啥,所以推荐使用miniconda。
miniconda官网:https://conda.io/miniconda.html
选择适合自己的版本下载:
wget -c https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
这里选择的是latest-Linux版本,所以下载的程序会随着python的版本更新而更新。
安装:
chmod 777 Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
加不加入环境变量都可以。所谓的会污染环境等等问题可能都是将大量的软件直接安装在conda的base环境中引起的,只要养成好的使用习惯,灵活使用conda create 命令将不同的软件安装到自己单独的虚拟环境中就可以了。把conda这条蟒蛇关进一个一个的笼子里,才能更好的为我们的科研服务~
添加频道
这个道理跟家里的电视机是一样一样的,安装conda就相当于买了一台电视机,但是有电视了不意味着你就能看节目了,你要手动添加频道才能看你想看的电视节目。
添加清华的镜像channels:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
为了分担清华源镜像的压力,北京外国语大学也开启了镜像站点,同样是由清华TUNA团队维护的,如果有小伙伴遇到清华源速度很慢的情况的话,可以考虑换成北外的镜像。
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/main/
显示安装的频道
conda config --set show_channel_urls yes
查看已经添加的channels
conda config --get channels
已添加的channel在哪里查看
vim ~/.condarc
软件包管理
conda install gatk
搜索安装包
conda search gatk
安装完成后,可以用“which 软件名”来查看该软件安装的位置:
which gatk
安装特定版本
conda install 软件名=版本号
conda install gatk=3.7
这时conda会先卸载已安装版本,然后重新安装指定版本。
查看已安装软件
conda list
更新指定软件
conda update gatk
卸载指定软件
conda remove gatk
环境管理
退出conda环境
退出也很简单,之前我们是. ./activate 或者 (. ~/miniconda3/bin/activate)现在退出只要:
$ . ./deactivate
# 或者用
$ conda deactivate
就退出当前的环境了
创建conda环境
之前创建的时候显示的是(base)这是conda的基本环境,有些软件依赖的是python2的版本,当你还是使用你的base的时候你的base里的python会被自动降级,有可能会引发别的软件的报错,所以,可以给一些特别的软件一些特别的关照,比如创建一个单独的环境。
在conda环境下,输入conda env list(或者输入conda info --envs也是一样滴)查看当前存在的环境:
conda env list
创建一个新的环境
conda create -n python2 python=2
- -n: 设置新的环境的名字
- python=2 指定新环境的python的版本,非必须参数
- 这里也可以用一个-y参数,可以直接跳过安装的确认过程。
conda会创建一个新的python2的环境,并且会很温馨的提示你只要输入conda activate python2就可以启动这个环境了。
删除环境
conda remove -n myenv --all
重命名环境
实际上conda并没有提供这样的功能,但是可以曲线救国,原理是先克隆一个原来的环境,命名成想要的名字,再把原来的环境删掉即可
接下来演示把一个原来叫做py2的环境重新命名成python2:
conda create -n python2 --clone py2
conda remove -n py2 --all
自动更新
Ubuntu 默认的配置会每天自动安装安全更新而忽略其它包的更新。
更新机制
Ubuntu 默认定义了 4 个 systemd unit 执行更新任务,它们分别是:
/lib/systemd/system/apt-daily-upgrade.service
/lib/systemd/system/apt-daily-upgrade.timer
/lib/systemd/system/apt-daily.service
/lib/systemd/system/apt-daily.timer
中的 apt-daily.timer 和 apt-daily-upgrade.timer 是两个触发器,分别在每天指定的时间触发 apt-daily.service 和 apt-daily-upgrade.service。这两个 service 的类型都是 oneshot,意思是当任务完成后 service 进程退出。这两个 service 其实调用的是同一个脚本: /usr/lib/apt/apt.systemd.daily。apt-daily.service 为脚本传入参数 “update”,其功能为检查系统的更新并下载对应的更新包。apt-daily-upgrade.service 为脚本传入参数 “install”,其功能为安装更新并删除缓存在本地的更新包。
apt-daily.timer 默认每天触发两次,分别为 6 点和 18 点,主要是为了缓解服务器端的下载压力。我们可以根据自身业务的特点设置合适的触发时间。
apt-daily-upgrade.service 默认每天在 6 点触发一次,我们也可以设置为其它时间,比如午夜。
apt.systemd.daily
/usr/lib/apt/apt.systemd.daily 脚本负责完成与更新相关的一系列工作,这些工作主要分为两大块:
- 检查更新并下载更新包
- 安装更新并清理更新包
apt.systemd.daily 脚本中调用 apt-config 命令从 /etc/apt/apt.conf.d/10periodic 文件和 /etc/apt/apt.conf.d/20auto-upgrades 读中取配变量,并根据这些变量的值来控制系统的更新策略。下面我们介绍几个比较重要的配置项。
隔多少天执行一次 apt-get update,默认是 1 天,0 表示不执行该操作:
APT::Periodic::Update-Package-Lists "1";
隔多少天执行一次 apt-get upgrade –download-only 下载更新包,0 表示不执行该操作:
APT::Periodic::Download-Upgradeable-Packages "0";
下载的更新版被缓存在目录 /var/cache/apt/archives/ 中,执行升级操作时直接从缓存目录中读取包文件而不是从网络上下载。
隔多少天执行一次 apt-get autoclean 清除无用的更新包,0 表示不执行该操作:
APT::Periodic::AutocleanInterval "0";
隔多少天执行一次 Unattended-Upgrade 执行系统安全更新(或者所有包的更新),0 表示不执行该操作:
APT::Periodic::Unattended-Upgrade "1";
通过这些配置,我们可以控制自动更新的频率和行为。注意,到目前为止的配置还只能安装系统的安全更新,如果要想安装所有包的更新还需要其它的配置。
在继续介绍后面的内容前,让我们先来了解一下 apt.systemd.daily 脚本中用到的 apt-config 命令和 apt.systemd.daily 脚本依赖的配置文件。
apt-config 命令
apt-config 是一个被 APT 套件使用的内部命令,使用它可以在脚本中提取 /etc/apt/apt.conf 目录下配置文件中的信息。
比如,如果要在脚本中获取 APT::Periodic::Update-Package-Lists 的设置,可以使用下面的代码:
#!/bin/bash
ABC=0
eval $(apt-config shell ABC APT::Periodic::Update-Package-Lists)
echo ${ABC}
此时脚本变量 ABC 中保存的就是 APT::Periodic::Update-Package-Lists 的值。
10periodic 和 20auto-upgrades
/etc/apt/apt.conf.d/10periodic 是 update-notifier-common 的配置文件:
$ dpkg-query -S /etc/apt/apt.conf.d/10periodic
update-notifier-common: /etc/apt/apt.conf.d/10periodic
在 ubuntu 16.04 和 18.04 中,这两个文件的默认内容是一样的。apt.systemd.daily 脚本在注释中说我们可以通过 /etc/apt/apt.conf.d/10periodic 文件自定义相关的变量值,它通过 get-config 命令来获得这些变量的值。但是测试的结果是 /etc/apt/apt.conf.d/20auto-upgrades 文件中的变量会覆盖 /etc/apt/apt.conf.d/10periodic 文件中的变量。看来是 get-config 命令根据文件名称的顺序,排在后面的文件中的变量会覆盖前面文件中的变量。
在 desktop 版本中,通过 GUI 程序修改相关的变量,这两个文件都会被修改并保持一致,所以在 server 版中我们最好也同时修改这两个文件并保持其内容一致。
unattended-upgrades
Ubuntu 实际上是通过 unattended-upgrades 命令来自动安装更新的。Ubuntu 16.04/18.04 默认安装了这个包,如果碰到没有安装的情况你还可以通过下面的命令自行安装:
sudo apt install unattended-upgrades
unattended-upgrades 的配置文件为 /etc/apt/apt.conf.d/50unattended-upgrades。
注意,unattended-upgrades 不仅能够安装系统的安全更新,还可以安装所有包的更新。但是默认的配置只安装安全更新,我们可以通过配置项让 unattended-upgrades 安装所有的包更新或者只安装安全更新。
unattended-upgrades 命令被设计为通过 cron 定时执行系统更新,但在 Ubuntu 16.04/18.04 中是通过 systemd 的 timer unit 定时触发 service unit 执行的。
unattended-upgrades 命令的日志文件存放在 /var/log/unattended-upgrades 目录下。
unattended-upgrade 命令常见的用法之一是检查系统是否有更新:
sudo unattended-upgrade --dry-run
另一种用法是安装更新:
sudo unattended-upgrade
在 apt.systemd.daily 脚本中执行 unattended-upgrade 命令时,由于更新包已经提前下载到缓存目录了(/var/cache/apt/archives),所以直接它直接使用缓存中的更新包。
配置文件 50unattended-upgrades
50unattended-upgrades 文件中的默认配置只是安装安全更新:
Unattended-Upgrade::Allowed-Origins {
"${distro_id}:${distro_codename}";
"${distro_id}:${distro_codename}-security";
"${distro_id}ESM:${distro_codename}";
// "${distro_id}:${distro_codename}-updates";
// "${distro_id}:${distro_codename}-proposed";
// "${distro_id}:${distro_codename}-backports";
};
如果要自动安装所有包的更新,只要取消下面行的注释就行了:
"${distro_id}:${distro_codename}-updates";
我们还可以通过黑名单的方式指定不更新哪些包:
Unattended-Upgrade::Package-Blacklist {
"vim";
"libc6";
"libc6-dev";
"libc6-i686";
};
下面的配置项指定在更新后移除无用的包:
Unattended-Upgrade::Remove-Unused-Kernel-Packages "true";
Unattended-Upgrade::Remove-Unused-Dependencies "true";
有些更新需要重启系统,而默认的配置是不重启系统的。下面的配置允许重启系统(更新完成后,如果需要重启,立即重启系统):
Unattended-Upgrade::Automatic-Reboot "true";
但是多数情况下我们更期望指定一个时间让系统重启(如果需要重启,在下面配置中指定的时间重启系统):
Unattended-Upgrade::Automatic-Reboot-Time "02:38";
在系统更新的过程中发生了错误怎么办?当然是通知管理员啦!下面的配置在发生错误时给管理员发送邮件:
Unattended-Upgrade::Mail "user@example.com";
Unattended-Upgrade::MailOnlyOnError "true";
注意:如果要向外网发送邮件,需要安装 mailx 等工具。
关闭自动更新
如果你的主机运行在封闭的环境中,并且无法连接到有效的更新源,此时可以选择关闭自动更新功能。首选的方法是停止相关的服务:
sudo systemctl stop apt-daily.service
sudo systemctl stop apt-daily.timer
sudo systemctl stop apt-daily-upgrade.service
sudo systemctl stop apt-daily-upgrade.timer
sudo systemctl disable apt-daily.service
sudo systemctl disable apt-daily.timer
sudo systemctl disable apt-daily-upgrade.service
sudo systemctl disable apt-daily-upgrade.timer
或者修改自动更新程序的配置文件也可以,同时更新 /etc/apt/apt.conf.d/10periodic 和 /etc/apt/apt.conf.d/20auto-upgrades:
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "1";
改为
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
文件系统
fstab
/etc/fstab是用来存放文件系统的静态信息的文件。当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂载到指定的目录。
查看/etc/fstab
# cat /etc/fstab
<file system> <dir> <type> <options> <dump> <pass>
tmpfs /tmp tmpfs nodev,nosuid 0 0
/dev/sda1 / ext4 defaults,noatime 0 1
/dev/sda2 none swap defaults,nodelalloc 0 0
/dev/sda3 /home ext4 defaults,noatime 0 2
分别解释一下各字段的用处:
<file system>要挂载的分区或存储设备<dir>挂载的目录位置<type>挂载分区的文件系统类型,比如:ext3、ext4、xfs、swap<options>挂载使用的参数有哪些。举例如下:- auto - 在启动时或键入了 mount -a 命令时自动挂载。
- noauto - 只在你的命令下被挂载。
- exec - 允许执行此分区的二进制文件。
- noexec - 不允许执行此文件系统上的二进制文件。
- ro - 以只读模式挂载文件系统。
- rw - 以读写模式挂载文件系统。
- user - 允许任意用户挂载此文件系统,若无显示定义,隐含启用 noexec, nosuid, nodev 参数。
- users - 允许所有 users 组中的用户挂载文件系统.
- nouser - 只能被 root 挂载。
- owner - 允许设备所有者挂载。
- sync - I/O 同步进行。
- async - I/O 异步进行。
- dev - 解析文件系统上的块特殊设备。
- nodev - 不解析文件系统上的块特殊设备。
- suid - 允许 suid 操作和设定 sgid 位。这一参数通常用于一些特殊任务,使一般用户运行程序时临时提升权限。
- nosuid - 禁止 suid 操作和设定 sgid 位。
- noatime - 不更新文件系统上 inode 访问记录,可以提升性能。
- nodiratime - 不更新文件系统上的目录 inode 访问记录,可以提升性能(参见 atime 参数)。
- relatime - 实时更新 inode access 记录。只有在记录中的访问时间早于当前访问才会被更新。(与
- noatime 相似,但不会打断如 mutt 或其它程序探测文件在上次访问后是否被修改的进程。),可以提升性能。
- flush - vfat 的选项,更频繁的刷新数据,复制对话框或进度条在全部数据都写入后才消失。
- defaults - 使用文件系统的默认挂载参数,例如 ext4 的默认参数为:rw, suid, dev, exec, auto, nouser, async.
<dump>dump 工具通过它决定何时作备份。dump 会检查其内容,并用数字来决定是否对这个文件系统进行备份。 允许的数字是 0 和 1 。0 表示忽略, 1 则进行备份。大部分的用户是没有安装 dump 的 ,对他们而言<dump>应设为 0。<pass>fsck 读取<pass>的数值来决定需要检查的文件系统的检查顺序。允许的数字是0, 1, 和2。 根目录应当获得最高的优先权 1, 其它所有需要被检查的设备设置为 2。 0 表示设备不会被 fsck 所检查。
示例:
/dev/sda1 /mnt/LinuxOSBuckup ext4 defaults 0 2
UUID of Storage Devices
Finding UUID with blkid
sudo blkid
Finding UUID with ls
ls -l /dev/disk/by-uuid
Finding UUID with lsblk
sudo lsblk -f
LVM
在对磁盘分区的大小进行规划时,往往不能确定这个分区要使用的空间的大小。而使用 fdisk、gdisk 等工具对磁盘分区后,每个分区的大小就固定了。如果分区设置的过大,就白白浪费了磁盘空间;如果分区设置的过小,就会导致空间不够用的情况出现。对于分区过小的问题,可以从新划分磁盘的分区,或者通过软连接的方式将此分区的目录链接到另外一个分区。这样虽然能够临时解决问题,但是给管理带来了麻烦。类似的问题可以通过 LVM 来解决。
LVM 是什么
LVM 是 Logical Volume Manager 的缩写,中文一般翻译为 “逻辑卷管理”,它是 Linux 下对磁盘分区进行管理的一种机制。LVM 是建立在磁盘分区和文件系统之间的一个逻辑层,系统管理员可以利用 LVM 在不重新对磁盘分区的情况下动态的调整分区的大小。如果系统新增了一块硬盘,通过 LVM 就可以将新增的硬盘空间直接扩展到原来的磁盘分区上。
LVM 的优点如下:
- 文件系统可以跨多个磁盘,因此大小不再受物理磁盘的限制。
- 可以在系统运行状态下动态地扩展文件系统大小。
- 可以以镜像的方式冗余重要数据到多个物理磁盘上。
- 可以很方便地导出整个卷组,并导入到另外一台机器上。
LVM 也有一些缺点:
- 在从卷组中移除一个磁盘的时候必须使用 reducevg 命令(这个命令要求root权限,并且不允许在快照卷组中使用)。
- 当卷组中的一个磁盘损坏时,整个卷组都会受影响。
- 因为增加了一个逻辑层,存储的性能会受影响。
LVM 的优点对服务器的管理非常有用,但对于桌面系统的帮助则没有那么显著,所以需要我们根据使用的场景来决定是否应用 LVM。
LVM 中的基本概念
通过 LVM 技术,可以屏蔽掉磁盘分区的底层差异,在逻辑上给文件系统提供了一个卷的概念,然后在这些卷上建立相应的文件系统。下面是 LVM 中主要涉及的一些概念。
- **物理存储设备(Physical Media):**指系统的存储设备文件,比如 /dev/sda、/dev/sdb 等。
- **PV(物理卷 Physical Volume):**指硬盘分区或者从逻辑上看起来和硬盘分区类似的设备(比如 RAID 设备)。
- **VG(卷组 Volume Group):**类似于非 LVM 系统中的物理硬盘,一个 LVM 卷组由一个或者多个 PV(物理卷)组成。
- **LV(逻辑卷 Logical Volume):**类似于非 LVM 系统上的磁盘分区,LV 建立在 VG 上,可以在 LV 上建立文件系统。
- **PE(Physical Extent):**PV(物理卷)中可以分配的最小存储单元称为 PE,PE 的大小是可以指定的。
- **LE(Logical Extent):**LV(逻辑卷)中可以分配的最小存储单元称为 LE,在同一个卷组中,LE 的大小和 PE 的大小是一样的,并且一一对应。
可以这么理解,LVM 是把硬盘的分区分成了更小的单位(PE),再用这些单元拼成更大的看上去像分区的东西(PV),进而用 PV 拼成看上去像硬盘的东西(VG),最后在这个新的硬盘上创建分区(LV)。文件系统则建立在 LV 之上,这样就在物理硬盘和文件系统中间添加了一层抽象(LVM)。下图大致描述了这些概念之间的关系:
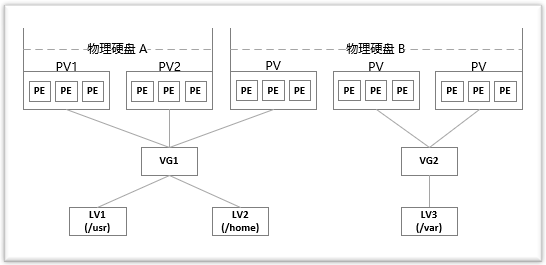
对上图中的结构做个简单的介绍:
两块物理硬盘 A 和 B 组成了 LVM 的底层结构,这两块硬盘的大小、型号可以不同。PV 可以看做是硬盘上的分区,因此可以说物理硬盘 A 划分了两个分区,物理硬盘 B 划分了三个分区。然后将前三个 PV 组成一个卷组 VG1,后两个 PV 组成一个卷组 VG2。接着在卷组 VG1 上划分了两个逻辑卷 LV1 和 LV2,在卷组 VG2 上划分了一个逻辑卷 LV3。最后,在逻辑卷 LV1、LV2 和 LV3 上创建文件系统,分别挂载在 /usr、/home 和 /var 目录。
LVM 工具
在安装 Linux 时,如果选择使用 LVM 创建分区,就会安装 LVM 相关的工具。当前这个软件包的名称为 lvm2,其中包含了大量 LVM 工具。比如单是查看 LVM 相关实体状态的命令就有如下一些:
sudo pvscan
sudo pvs
sudo pvdisplay
sudo vgscan
sudo vgs
sudo vgdisplay
sudo lvscan
sudo lvs
sudo lvdisplay
如果安装系统时没有默认安装 LVM 工具包,可以通过下面的命令安装它们:
sudo apt update
sudo apt install lvm2
接下来我们通过例子来演示如何使用 LVM 来一步步的创建出逻辑卷(LV),然后在 LV 上创建文件系统并挂载到 Linux 系统中。
使用 gdisk 对物理磁盘进行分区
目前常见的磁盘分区格式有两种,MBR 分区和 GPT 分区。
MBR 分区,MBR 的意思是 “主引导记录”。MBR 最大支持 2TB 容量,在容量方面存在着极大的瓶颈。
GPT 分区,GPT 意为 GUID 分区表,它支持的磁盘容量比 MBR 大得多。这是一个正逐渐取代 MBR 的新标准,它是由 UEFI 辅住而形成的,将来 UEFI 用于取代老旧的 BIOS,而 GPT 则取代老旧的 MBR。
使用 fdisk 工具创建 MBR 磁盘分区,而 gdisk 是 Linux 系统中 GPT 格式的磁盘分区管理工具。
假设我们的 Linux 系统中增加了一块新的磁盘,系统对应的设备名为 /dev/sdb,下面我们通过 gdisk 命令对这个磁盘进行分区。
在用 gdisk 命令对磁盘分区前,我们先用 parted 命令查看 /dev/sdb 当前的分区情况:
sudo parted /dev/sdb print
下面通过 gdisk 命令创建分区:
sudo gdisk /dev/sdb
通过 p 命令可以查看磁盘当前的状态:输出中的前几行是磁盘的基本信息,比如总大小,一共有多少个扇区(sector),每个扇区的大小,当前剩余的空间等等。
然后是已经存在的分区信息:
- 第一列 Number 显示了分区的编号,比如 1 号指 /dev/sdb1。
- 第二列 Start 表示磁盘分区的起始位置。
- 第三列 End 表示磁盘分区的结束位置。
- 第四列 Size 显示分区的容量。
- 第五列 Code 和第六列 Name 显示分区类型的 ID和名称,比如 Linux filesystem 为 8300,Linux swap 为 8200,Linux LVM 为 8e00。
通过 n 命令来创建新分区:
分区编号和开始/结束的扇区都直接通过回车选择默认值,这样所有的磁盘空间都划分到了一个分区中,然后输入 8e00 说明我们要创建的分区类型为 Linux LVM。最后输入 w 命令并确认执行分区操作。分区成功后可通过 p 命令查看我们创建的分区的信息。
创建物理卷 PV
# pvcreate DEVICE
现在我们可以基于磁盘分区 /dev/sdb1 来创建 LVM 物理卷(LV),可以通过 pvcreate 命令来完成:
sudo pvcreate /dev/sdb1
此时 /dev/sdb1 已经完成了从磁盘分区到 PV 的华丽转身!注意上面的命令,磁盘分区被直接转换成了 PV,连名称都没有变化!我们可以通过 pvs 命令查看 /dev/sdb1,目前它还没有被加入到 VG 中。
创建卷组 VG
# vgcreate <volume_group> <physical_volume1> <physical_volume2> ...
基于一个或多个 PV,可以创建 VG。我们使用刚才创建的 PV /dev/sdb1 来创建一个名称为 nickvg 的 VG:
sudo vgcreate -s 32G nickvg /dev/sdb1
注意 vgcreate 命令中的 -s 选项,它指定了 PE(Physical Extent) 的大小。可以通 vgs 命令观察 VG 的信息:
sudo vgs nickvg
如果目标 VG 已经存在,则使用 vgextend 把 PV 加入到 VG 中即可。
# vgextend <卷组名> <物理卷>
创建逻辑卷 LV
# lvcreate -L <卷大小> <卷组名> -n <卷名>
有了 VG 就可以创建逻辑卷 LV 了,lvcreate 命令用来创建 LV,让我们在前面创建的 nickvg 上创建名称为 nicklv00 的 LV:
sudo lvcreate -L 15G -n nicklv00 nickvg
选项 -L 指定新建 LV 的容量,这里是 15G;选项 -n 则指定新建 LV 的名称,这里为 nicklv00。可以通过 lvs 命令观察 LV 的信息,注意需要同时指出 LV 所在的 VG:
sudo lvs nickvg/nicklv00
如果你想让要创建的逻辑卷拥有卷组(VG)的所有未使用空间,请使用以下命令:
# lvcreate -l +100%FREE <volume_group> -n <logical_volume>
格式化逻辑卷(创建文件系统)
# mkfs.<类型> /dev/mapper/<卷组名>-<卷名>
# mount /dev/mapper/<卷组名>-<卷名> <挂载点>
当我们创建 LV nickvg/nicklv00 时,其实是创建了名称为 /dev/nickvg/nicklv00 的设备文件。
现在你的逻辑卷应该已经在/dev/mapper/和/dev/YourVolumeGroupName中了。
现在我们来格式化这个逻辑卷(在该 LV 上创建文件系统),目标为比较常见的 ext4 格式:
sudo mkfs.ext4 /dev/nickvg/nicklv00
然后创建个目录,比如 /home/doc,并把新建的文件系统挂载到这个目录上:
sudo mkdir /home/doc
sudo mount /dev/nickvg/nicklv00 /home/doc
最后可以通过 df 命令查看这个文件系统的使用情况。
开机自动挂载
编辑 /etc/fstab 文件:
sudo vim /etc/fstab
把下面的行添加的文件末尾并保存文件:
/dev/mapper/nickvg-nicklv00 /home/doc ext4 defaults 0 2
调整逻辑卷
同时缩小逻辑卷和其文件系统
注意: 只有ext2,ext3,ext4,ReiserFS和 XFS 文件系统支持以下操作。
将MyVolGroup组中的逻辑卷mediavol扩大10GiB,并同时扩大其文件系统:
# lvresize -L +10G --resizefs MyVolGroup/mediavol
将MyVolGroup组中的逻辑卷mediavol大小调整为15GiB,并同时调整其文件系统:
# lvresize -L 15G --resizefs MyVolGroup/mediavol
将卷组中的所有剩余空间分配给mediavol:
# lvresize -l +100%FREE --resizefs MyVolGroup/mediavol
重命名卷
重命名卷组
要重命名一个卷组,请使用vgrename(8)命令。
可使用下面的任意一条命令将卷组vg02重命名为my_volume_group
# vgrename /dev/vg02 /dev/my_volume_group
# vgrename vg02 my_volume_group
重命名逻辑卷
要重命名一个逻辑卷,请使用lvrename(8)命令。
可使用下面的任意一条命令将vg02组中的逻辑卷lvold重命名为lvnew.
# lvrename /dev/vg02/lvold /dev/vg02/lvnew
# lvrename vg02 lvold lvnew
移除逻辑卷
警告: 在移除逻辑卷之前,请先备份好数据以免丢失!
首先,找到你所要移除的逻辑卷的名称。你可以使用以下命令来查看系统的所有逻辑卷:
# lvs
接下来,找到你所要移除的逻辑卷的挂载点
lsblk
并卸载它:
# umount /<mountpoint>
最后,使用以下命令来移除逻辑卷:
# lvremove <volume_group>/<logical_volume>
例如:
# lvremove VolGroup00/lvolhome
请输入y来确定你要执行移除逻辑卷操作。
此外,请不要忘了更新/etc/fstab。
你可以再次使用lvs命令来确认你的逻辑卷已被移除。
LVM 快照
LVM 机制还提供了对 LV 做快照的功能,也就是说可以给文件系统做一个备份,这也是设计 LVM 快照的主要目的。LVM 的快照功能采用写时复制技术(Copy-On-Write,COW),这比传统的备份技术的效率要高很多。创建快照时不用停止服务,就可以对数据进行备份。说明:LVM 还支持 thin 类型的快照,但是本文中的快照都是指 COW 类型的快照。
LVM 采用的写时复制,是指当 LVM 快照创建的时候,仅创建到实际数据的 inode 的硬链接(hark-link)而已。只要实际的数据没有改变,快照就只包含指向数据的 inode 的指针,而非数据本身。快照会跟踪原始卷中块的改变,一旦你更改了快照对应的文件或目录,这个时候原始卷上将要改变的数据会在改变之前拷贝到快照预留的空间。
LVM 快照的原理
创建快照实际上也是创建了一个逻辑卷,只不过该卷的属性与普通逻辑卷的属性有些不一样。我们可以通过下图来理解快照数据卷(图中的实线框表示快照区域,虚线框表示文件系统):
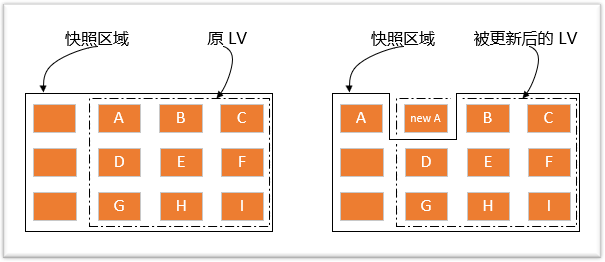
左图为最初创建的快照数据卷状况,LVM 会预留一个区域 (比如左图的左侧三个 PE 区块) 作为数据存放处。 此时快照数据卷内并没有任何数据,而快照数据卷与源数据卷共享所有的 PE 数据, 因此你会看到快照数据卷的内容与源数据卷中的内容是一模一样的。 等到系统运行一阵子后,假设 A 区域的数据被更新了(上面右图所示),则更新前系统会将该区域的数据移动到快照数据卷中, 所以在右图的快照数据卷中被占用了一块 PE 成为 A,而其他 B 到 I 的区块则还是与源数据卷共享!
由於快照区与原本的 LV 共享很多 PE 区块,因此快照区与被快照的 LV 必须要在同一个 VG 上头,下面两点非常重要:
- VG中需要预留存放快照本身的空间,不能全部被占满。
- 快照所在的 VG 必须与被备份的 LV 的 VG 相同,否则创建快照会失败。
创建 LVM 快照
其实快照就是一个特殊类型的数据卷,所以创建快照的命令和创建数据卷的命令相同,也是 lvcreate:
# lvcreate --size 100M --snapshot --name snap01 /dev/vg0/lv
此时如果把 LV snap01 挂载到系统中,里面的内容和 LV /dev/vg0/lv 中的内容是一样的。
创建的快照的大小可以比源数据卷小,但是当源数据卷中的数据更新过多时会导致快照容量不足而引起的错误并丢失数据。如上你可以修改少于100M的数据,直到该快照逻辑卷空间不足为止。
创建快照后,如果源数据卷中的文件被更新了,快照系统中则保存着其创建快照时的版本。
还原部分数据
如果我们明确的知道需要还原某个文件,可以挂载快照数据卷,直接拷贝其中旧版本的文件即可。
合并快照(merge snapshot)
要将逻辑卷卷’lv' 恢复到创建快照’snap01’时的状态,即还原整个数据卷上的数据,请使用:
# lvconvert --merge /dev/vg0/snap01
如果逻辑卷处于活动状态,则在下次重新启动时将进行合并(merging)(合并(merging)甚至可在LiveCD中进行)。
注意: 合并后快照将被删除。
可以拍摄多个快照,每个快照都可以任意与对应的逻辑卷合并。
快照可以被挂载,并可用dd或者tar备份。使用dd备份的快照的大小为拍摄快照后对应逻辑卷中变更过文件的大小。 要使用备份,只需创建并挂载一个快照,并将备份写入或解压到其中。再将快照合并到对应逻辑卷即可。
快照主要用于提供一个文件系统的拷贝,以用来备份; 比起直接备份分区,使用快照备份可以提供一个更符合原文件系统的镜像。
ZFS
历史
ZFS 是由 Matthew Ahrens 和 Jeff Bonwick 在 2001 年开发的。ZFS 是作为 Sun MicroSystem 公司的 OpenSolaris 的下一代文件系统而设计的。在 2008 年,ZFS 被移植到了 FreeBSD 。同一年,一个移植 ZFS on Linux 的项目也启动了。然而,由于 ZFS 是CDDL 许可的,它和 GPL 不兼容,因此不能将它迁移到 Linux 内核中。为了解决这个问题,绝大多数 Linux 发行版提供了一些方法来安装 ZFS 。
在甲骨文公司收购太阳微系统公司之后不久,OpenSolaris 就闭源了,这使得 ZFS 的之后的开发也变成闭源的了。许多 ZFS 开发者对这件事情非常不满。三分之二的 ZFS 核心开发者,包括 Ahrens 和 Bonwick,因为这个决定而离开了甲骨文公司。他们加入了其它公司,并于 2013 年 9 月创立了 OpenZFS 这一项目。该项目引领着 ZFS 的开源开发。
让我们回到上面提到的许可证问题上。既然 OpenZFS 项目已经和 Oracle 公司分离开了,有人可能好奇他们为什么不使用和 GPL 兼容的许可证,这样就可以把它加入到 Linux 内核中了。根据 OpenZFS 官网 的介绍,更改许可证需要联系所有为当前 OpenZFS 实现贡献过代码的人(包括初始的公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才行。这几乎是不可能的(因为一些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
特性
正如前面所说过的,ZFS 是一个先进的文件系统。因此,它有一些有趣的特性。
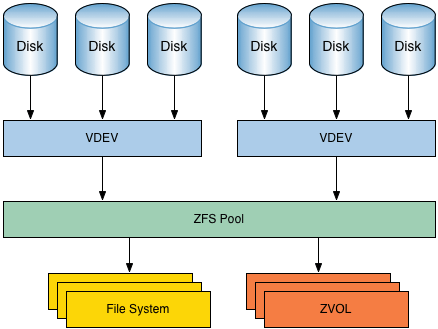
存储池
与大多数文件系统不同,ZFS 结合了文件系统和卷管理器的特性。这意味着,它与其他文件系统不同,ZFS 可以创建跨越一系列硬盘或池的文件系统。不仅如此,你还可以通过添加硬盘来增大池的存储容量。ZFS 可以进行分区和格式化。
写时拷贝
Copy-on-write 是另一个有趣并且很酷的特性。在大多数文件系统上,当数据被重写时,它将永久丢失。而在 ZFS 中,新数据会写到不同的块。写完成之后,更新文件系统元数据信息,使之指向新的数据块(LCTT 译注:更新之后,原数据块成为磁盘上的垃圾,需要有对应的垃圾回收机制)。这确保了如果在写新数据的时候系统崩溃(或者发生其它事,比如突然断电),那么原数据将会保存下来。这也意味着,在系统发生崩溃之后,不需要运行 fsck 来检查和修复文件系统。
快照
写时拷贝使得 ZFS 有了另一个特性:snapshots。ZFS 使用快照来跟踪文件系统中的更改。快照包含文件系统的原始版本(文件系统的一个只读版本),实时文件系统则包含了自从快照创建之后的任何更改。没有使用额外的空间。因为新数据将会写到实时文件系统新分配的块上。如果一个文件被删除了,那么它在快照中的索引也会被删除。所以,快照主要是用来跟踪文件的更改,而不是文件的增加和创建。
快照可以挂载成只读的,以用来恢复一个文件的过去版本。实时文件系统也可以回滚到之前的快照。回滚之后,自从快照创建之后的所有更改将会丢失。
数据完整性验证和自动修复
当向 ZFS 写入新数据时,会创建该数据的校验和。在读取数据的时候,使用校验和进行验证。如果前后校验和不匹配,那么就说明检测到了错误,然后,ZFS 会尝试自动修正错误。
RAID-Z
ZFS 不需要任何额外软件或硬件就可以处理 RAID(磁盘阵列)。毫不奇怪,因为 ZFS 有自己的 RAID 实现:RAID-Z 。RAID-Z 是 RAID-5 的一个变种,不过它克服了 RAID-5 的写漏洞:意外重启之后,数据和校验信息会变得不同步(LCTT 译注:RAID-5 的条带在正写入数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z 用了 “可变宽的 RAID 条带” 技术,因此所有的写都是全条带写入)。为了使用基本级别的 RAID-Z(RAID-Z1),你需要至少三块磁盘,其中两块用来存储数据,另外一块用来存储奇偶校验信息。而 RAID-Z2 需要至少两块磁盘存储数据以及两块磁盘存储校验信息。RAID-Z3 需要至少两块磁盘存储数据以及三块磁盘存储校验信息。另外,只能向 RAID-Z 池中加入偶数倍的磁盘,而不能是奇数倍的。
巨大的存储潜力
创建 ZFS 的时候,它是作为最后一个文件系统而设计的 。那时候,大多数文件系统都是 64 位的,ZFS 的创建者决定直接跳到 128 位,等到将来再来证明这是对的。这意味着 ZFS 的容量大小是 32 位或 64 位文件系统的 1600 亿亿倍。事实上,Jeff Bonwick(其中一个创建者)说:“完全填满一个 128 位的存储池所需要的能量,从字面上讲,比煮沸海洋需要的还多。”
如何安装 ZFS?
如果你想立刻使用 ZFS(开箱即用),那么你需要安装 FreeBSD 或一个使用 illumos 内核的操作系统。illumos 是 OpenSolaris 内核的一个克隆版本。
事实上,支持 ZFS 是一些有经验的 Linux 用户选择 BSD 的主要原因。
如果你想在 Linux 上尝试 ZFS,那么只能在存储文件系统上使用。据我所知,没有任何 Linux 发行版可以在根目录上安装 ZFS,实现开箱即用。如果你对在 Linux 上尝试 ZFS 感兴趣,那么 ZFS on Linux 项目 上有大量的教程可以指导你怎么做。
在 Ubuntu 上使用 ZFS
如果您正在考虑将 ZFS 用于您的超高速 NVMe SSD,这可能不是一个最佳选择。 它比别的文件系统要慢,不过,这完全没有问题, 它旨在存储大量的数据并保持安全。
sudo apt-get install zfsutils-linux
创建池
在 ZFS 中,池大致相当于 RAID 。 它们很灵活且易于操作。
RAID0
RAID0 只是把你的硬盘集中到一个池子里面,就像一个巨大的驱动器一样。 它可以提高你的驱动器速度,(LCTT 译注:数据条带化后,并行访问,可以提高文件读取速度)但是如果你的驱动器有损坏,你可能会失丢失数据。
在计算机数据存储中,数据条带化是一种对逻辑顺序数据(例如文件)进行分段的技术,以便将连续的段存储在不同的物理存储设备上。
要使用 ZFS 实现 RAID0,只需创建一个普通的池。
sudo zpool create your-pool /dev/sdc /dev/sdd
RAID1(镜像)
您可以在 ZFS 中使用 mirror 关键字来实现 RAID1 功能。 RAID1 会创建一个一对一的驱动器副本。 这意味着您的数据一直在备份。 它也提高了性能。 当然,你将一半的存储空间用于了复制。
sudo zpool create your-pool mirror /dev/sdc /dev/sdd
RAID5/RAIDZ1
ZFS 将 RAID5 功能实现为 RAIDZ1。 RAID5 要求驱动器至少是 3 个。并允许您通过将备份奇偶校验数据写入驱动器空间的 1/n(n 是驱动器数),留下的是可用的存储空间。 如果一个驱动器发生故障,阵列仍将保持联机状态,但应尽快更换发生故障的驱动器(LCTT 译注:与原文翻译略有不同,原文是驱动器的数目是三的倍数,根据 wiki, RAID5 至少需要 3 块驱动器,也可以从下面的命令中猜测)。
sudo zpool create your-pool raidz1 /dev/sdc /dev/sdd /dev/sde
RAID6/RAIDZ2
RAID6 与 RAID5 几乎完全相同,但它至少需要四个驱动器。 它将奇偶校验数据加倍,最多允许两个驱动器损坏,而不会导致阵列关闭(LCTT 译注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki ,RAID6 至少需要四个驱动器)。
sudo zpool create your-pool raidz2 /dev/sdc /dev/sdd /dev/sde /dev/sdf
RAID10(条带化镜像)
RAID10 旨在通过数据条带化提高存取速度和数据冗余来成为一个两全其美的解决方案。 你至少需要四个驱动器,但只能使用一半的空间。 您可以通过在同一个池中创建两个镜像来创建 RAID10 中的池(LCTT 译注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki, RAID10 至少需要四个驱动器)。
sudo zpool create your-pool mirror /dev/sdc /dev/sdd mirror /dev/sde /dev/sdf
池的操作
还有一些管理工具,一旦你创建了你的池,你就必须使用它们来操作。 首先,检查你的池的状态。
sudo zpool status
更新
当你更新 ZFS 时,你也需要更新你的池。 当您检查它们的状态时,您的池会通知您任何更新。 要更新池,请运行以下命令。
sudo zpool upgrade your-pool
你也可以更新全部池。
sudo zpool upgrade -a
添加驱动器
您也可以随时将驱动器添加到池中。 告诉 zpool 池的名称和驱动器的位置,它会处理好一切。
sudo zpool add your-pool /dev/sdx
实例
使用两块硬盘上的等容量分区建立 raid 1。
$ ls -l /dev/disk/by-id
usb-JMicron_Generic_DISK00_0123456789ABCDEF-0:0-part1 -> ../../sdb1
usb-JMicron_Generic_DISK01_0123456789ABCDEF-0:1-part2 -> ../../sdc2
$ sudo zpool create -f -o ashift=12 -o cachefile=/etc/zfs/zpool.cache -O compression=lz4 -O xattr=sa -O relatime=on -O acltype=posixacl -O dedup=off -m none dpool mirror usb-JMicron_Generic_DISK00_0123456789ABCDEF-0:0-part1 usb-JMicron_Generic_DISK01_0123456789ABCDEF-0:1-part2
$ sudo zfs create -o mountpoint=none -o canmount=off dpool/DATA
$ sudo zfs create -o mountpoint=/home/kurome/DataPool dpool/DATA/important
$ sudo zpool export dpool
$ sudo zpool import dpool
udev
如果你使用Linux比较长时间了,那你就知道,在对待设备文件这块,Linux改变了几次策略。在Linux早期,设备文件仅仅是是一些带有适当的属性集的普通文件,它由mknod命令创建,文件存放在/dev目录下。后来,采用了devfs, 一个基于内核的动态设备文件系统,他首次出现在2.3.46内核中。Mandrake,Gentoo等Linux分发版本采用了这种方式。devfs创建 的设备文件是动态的。但是devfs有一些严重的限制,从2.6.13版本后移走了。目前取代他的便是文本要提到的udev--一个用户空间程序。
目前很多的Linux分发版本采纳了udev的方式,因为它在Linux设备访问,特别是那些对设备有极端需求的站点(比如需要控制上千个硬盘)和热插拔设备(比如USB摄像头和MP3播放器)上解决了几个问题。下面我我们来看看如何管理udev设备。
实际上,对于那些为磁盘,终端设备等准备的标准配置文件而言,你不需要修改什么。但是,你需要了解udev配置来使用新的或者外来设备,如果不修改配置, 这些设备可能无法访问,或者说Linux可能会采用不恰当的名字,属组或权限来创建这些设备文件。你可能也想知道如何修改RS-232串口,音频设备等文件的属组或者权限。这点在实际的Linux实施中是会遇到的。
为什么使用udev
在此之前的设备文件管理方法(静态文件和devfs)有几个缺点:
- 不确定的设备映射。特别是那些动态设备,比如USB设备,设备文件到实际设备的映射并不可靠和确定。举一个例子:如果你有两个USB打印机。一个可能称 为/dev/usb/lp0,另外一个便是/dev/usb/lp1。但是到底哪个是哪个并不清楚,lp0,lp1和实际的设备没有一一对应的关系,因为 他可能因为发现设备的顺序,打印机本身关闭等原因而导致这种映射并不确定。理想的方式应该是:两个打印机应该采用基于他们的序列号或者其他标识信息的唯一 设备文件来映射。但是静态文件和devfs都无法做到这点。
- 没有足够的主/辅设备号。我们知道,每一个设备文件是有两个8位的数字:一个是主设备号 ,另外一个是辅设备号来分配的。这两个8位的数字加上设备类型(块设备或者字符设备)来唯一标识一个设备。不幸的是,关联这些身边的的数字并不足够。
- /dev目录下文件太多。一个系统采用静态设备文件关联的方式,那么这个目录下的文件必然是足够多。而同时你又不知道在你的系统上到底有那些设备文件是激活的。
- 命名不够灵活。尽管devfs解决了以前的一些问题,但是它自身又带来了一些问题。其中一个就是命名不够灵活;你别想非常简单的就能修改设备文件的名字。缺省的devfs命令机制本身也很奇怪,他需要修改大量的配置文件和程序。
- 内核内存使用,devfs特有的另外一个问题是,作为内核驱动模块,devfs需要消耗大量的内存,特别当系统上有大量的设备时(比如上面我们提到的系统一个上有好几千磁盘时)
udev的目标是想解决上面提到的这些问题,他通采用用户空间(user-space)工具来管理/dev/目录树,他和文件系统分开。知道如何改变缺省配置能让你之大如何定制自己的系统,比如创建设备字符连接,改变设备文件属组,权限等。
udev配置文件
主要的udev配置文件是/etc/udev/udev.conf。这个文件通常很短,他可能只是包含几行#开头的注释,然后有几行选项:
udev_root=“/dev/”
udev_rules=“/etc/udev/rules.d/”
udev_log=“err“
上面的第二行非常重要,因为他表示udev规则存储的目录,这个目录存储的是以.rules结束的文件。每一个文件处理一系列规则来帮助udev分配名字给设备文件以保证能被内核识别。
你的/etc/udev/rules.d下面可能有好几个udev规则文件,这些文件一部分是udev包安装的,另外一部分则是可能是别的硬件或者软件包 生成的。比如在Fedora Core 5系统上,sane-backends包就会安装60-libsane.rules文件,另外initscripts包会安装60-net.rules文 件。这些规则文件的文件名通常是两个数字开头,它表示系统应用该规则的顺序。
规则文件里的规则有一系列的键/值对组成,键/值对之间用逗号(,)分割。每一个键或者是用户匹配键,或者是一个赋值键。匹配键确定规则是否被应用,而赋 值键表示分配某值给该键。这些值将影响udev创建的设备文件。匹配键和赋值键操作符解释见下表:
| 操作符 | 匹配或赋值 | 解释 |
|---|---|---|
| == | 匹配 | 相等比较 |
| != | 匹配 | 不等比较 |
| = | 赋值 | 分配一个特定的值给该键,他可以覆盖之前的赋值。 |
| += | 赋值 | 追加特定的值给已经存在的键 |
| := | 赋值 | 分配一个特定的值给该键,后面的规则不可能覆盖它。 |
这有点类似我们常见的编程语言,比如C语言。只是这里的键一次可以处理多个值。有一些键在udev规则文件里经常出现,这些键的值可以使用通配符(*,?,甚至范围,比如[0-9]),这些常用键列举如下:
| 键 | 含义 |
|---|---|
| ACTION | 一个时间活动的名字,比如add,当设备增加的时候 |
| KERNEL | 在内核里看到的设备名字,比如sd*表示任意SCSI磁盘设备 |
| DEVPATH | 内核设备路径,比如/devices/* |
| SUBSYSTEM | 子系统名字,比如sound,net |
| BUS | 总线的名字,比如IDE,USB |
| DRIVER | 设备驱动的名字,比如ide-cdromID 独立于内核名字的设备名字 |
| SYSFS{ value} | sysfs属性值,他可以表示任意 |
| ENV{ key} | 环境变量,可以表示任意 |
| PROGRAM | 可执行的外部程序,如果程序返回0值,该键则认为为真(true) |
| RESULT | 上一个PROGRAM调用返回的标准输出。 |
| NAME | 根据这个规则创建的设备文件的文件名。注意:仅仅第一行的NAME描述是有效的,后面的均忽略。 如果你想使用使用两个以上的名字来访问一个设备的话,可以考虑SYMLINK键。 |
| SYMLINK | 根据规则创建的字符连接名 |
| OWNER | 设备文件的属组 |
| GROUP | 设备文件所在的组。 |
| MODE | 设备文件的权限,采用8进制 |
| RUN | 为设备而执行的程序列表 |
| LABEL | 在配置文件里为内部控制而采用的名字标签(下下面的GOTO服务) |
| GOTO | 跳到匹配的规则(通过LABEL来标识),有点类似程序语言中的GOTO |
| IMPORT{ type} | 导入一个文件或者一个程序执行后而生成的规则集到当前文件 |
| WAIT_FOR_SYSFS | 等待一个特定的设备文件的创建。主要是用作时序和依赖问题。 |
| PTIONS | 特定的选项: last_rule 对这类设备终端规则执行; ignore_device 忽略当前规则; ignore_remove 忽略接下来的并移走请求。all_partitions 为所有的磁盘分区创建设备文件。 |
我们给出一个列子来解释如何使用这些键。下面的例子来自Fedora Core 5系统的标准配置文件。
KERNEL=="*", OWNER="root" GROUP="root", MODE="0600"
KERNEL=="tty", NAME="%k", GROUP="tty", MODE="0666", OPTIONS="last_rule"
KERNEL=="scd[0-9]*", SYMLINK+="cdrom cdrom-%k"
KERNEL=="hd[a-z]", BUS=="ide", SYSFS{removable}=="1", SYSFS{device/media}=="cdrom", SYMLINK+="cdrom cdrom-%k"
ACTION=="add", SUBSYSTEM=="scsi_device", RUN+="/sbin/modprobe sg"
上面的例子给出了5个规则,每一个都是KERNEL或者ACTION键开头:
- 第一个规则是缺省的,他匹配任意被内核识别到的设备,然后设定这些设备的属组是root,组是root,访问权限模式是0600(-rw——-)。这也是一个安全的缺省设置保证所有的设备在默认情况下只有root可以读写
- 第二个规则也是比较典型的规则了。它匹配终端设备(tty),然后设置新的权限为0600,所在的组是tty。它也设置了一个特别的设备文件名:%K。在这里例子里,%k代表设备的内核名字。那也就意味着内核识别出这些设备是什么名字,就创建什么样的设备文件名。
- 第三行开始的KERNEL==”scd[0-9]*”,表示 SCSI CD-ROM 驱动. 它创建一对设备符号连接:cdrom和cdrom-%k。
- 第四行,开始的 KERNEL==”hd[a-z]“, 表示ATA CDROM驱动器。这个规则创建和上面的规则相同的符号连接。ATA CDROM驱动器需要sysfs值以来区别别的ATA设备,因为SCSI CDROM可以被内核唯一识别。.
- 第五行以 ACTION==”add”开始,它告诉udev增加 /sbin/modprobe sg 到命令列表,当任意SCSI设备增加到系统后,这些命令将执行。其效果就是计算机应该会增加sg内核模块来侦测新的SCSI设备。
当然,上面仅仅是一小部分例子,如果你的系统采用了udev方式,那你应该可以看到更多的规则。如果你想修改设备的权限或者创建信的符号连接,那么你需要熟读这些规则,特别是要仔细注意你修改的那些与之相关的设备。
修改你的udev配置
在修改udev配置之前,我们一定要仔细,通常的考虑是:你最好不要修改系统预置的那些规则,特别不要指定影响非常广泛的配置,比如上面例子中的第一行。不正确的配置可能会导致严重的系统问题或者系统根本就无法这个正确的访问设备。
而我们正确的做法应该是在/etc/udev/rules.d/下创建一个新的规则文件。确定你给出的文件的后缀是rules文件名给出的数字序列应该比标准配置文件高。比如,你可以创建一个名为99-my-udev.rules的规则文件。在你的规则文件中,你可以指定任何你想修改的配置,比如,假设你 修改修改floppy设备的所在组,还准备创建一个新的符号连接/dev/floppy,那你可以这么写:
KERNEL==”fd[0-9]*“, GROUP=“users“, SYMLINK+=“floppy“
有些发行版本,比如Fedora,采用了外部脚本来修改某些特定设备的属组,组关系和权限。因此上面的改动可能并不见得生效。如果你遇到了这个问题,你就需要跟踪和修改这个脚本来达到你的目的。或者你可以修改PROGRAM或RUN键的值来做到这点。
某些规则的修改可能需要更深的挖掘。比如,你可能想在一个设备上使用sysfs信息来唯一标识一个设备。这些信息最好通过udevinfo命令来获取。
udevinfo –a –p $(udevinfo –q path –n /dev/hda)
上面的命令两次使用udevinfo:一次是返回sysfs设备路径(他通常和我们看到的Linux设备文件名所在路径--/dev/hda--不同);第 二次才是查询这个设备路径,结果将是非常常的syfs信息汇总。你可以找到最够的信息来唯一标志你的设备,你可以采用适当的替换udev配置文件中的 SYSFS选项。下面的结果就是上面的命令输出
[root@localhost rules.d]# udevinfo -a -p $(udevinfo -q path -n /dev/hda1)
Udevinfo starts with the device specified by the devpath and then walks up the chain of
parent devices. It prints for every device found,all possible attributes in the udev rules
key format. A rule to match, can be composed by the attributes of the device and the
attributes from one single parent device.
looking at device '/block/hda/hda1':
KERNEL=="hda1" SUBSYSTEM=="block" DRIVER==""
ATTR{stat}==" 1133 2268 2 4" ATTR{size}=="208782"
ATTR{start}=="63" ATTR{dev}=="3:1" looking at parent device '/block/hda':
KERNELS=="hda" SUBSYSTEMS=="block" DRIVERS==""
ATTRS{stat}=="28905 18814 1234781 302540 34087 133247 849708 981336 0 218340 1283968"
ATTRS{size}=="117210240" ATTRS{removable}=="0"
ATTRS{range}=="64" ATTRS{dev}=="3:0"
looking at parent device '/devices/pci0000:00/0000:00:1f.1/ide0/0.0':
KERNELS=="0.0" SUBSYSTEMS=="ide" DRIVERS=="ide-disk"
ATTRS{modalias}=="ide:m-disk" ATTRS{drivename}=="hda"
ATTRS{media}=="disk"
looking at parent device '/devices/pci0000:00/0000:00:1f.1/ide0':
KERNELS=="ide0" SUBSYSTEMS=="" DRIVERS==""
looking at parent device '/devices/pci0000:00/0000:00:1f.1':
KERNELS=="0000:00:1f.1" SUBSYSTEMS=="pci" DRIVERS=="PIIX_IDE"
ATTRS{broken_parity_status}=="0" ATTRS{enable}=="1"
ATTRS{modalias}=="pci:v00008086d000024CAsv0000144Dsd0000C009bc01sc01i8a"
ATTRS{local_cpus}=="1" ATTRS{irq}=="11" ATTRS{class}=="0x01018a"
ATTRS{subsystem_device}=="0xc009" ATTRS{subsystem_vendor}=="0x144d"
ATTRS{device}=="0x24ca" ATTRS{vendor}=="0x8086"
looking at parent device '/devices/pci0000:00':
KERNELS=="pci0000:00" SUBSYSTEMS=="" DRIVERS==""
举一个例子:假设你想修改USB扫描仪的配置。通过一系列的尝试,你已经为这个扫描仪标识了Linux设备文件(每次打开扫描仪时,名字都会变)。你可以使 用上面的命令替换这个正确的Linux设备文件名,然后定位输出的采用SYSFS{idVendor}行和SYSFS{idProduct}行。最后你可 以使用这些信息来为这个扫描仪创建新的选项。
SYSFS{idVendor}=="0686", SYSFS{idProduct}=="400e", SYMLINK+="scanner", MODE="0664", group="scanner"
上面的例子表示将扫描仪的组设置为scanner,访问权限设置为0664,同时创建一个/dev/scanner的符号连接。
Tips
Mounting usb automatically & having usb’s label as mountpoint
How to automatically mount USB drives with custom mount point
Systemd
LINUX PID 1 和 SYSTEMD
要说清 Systemd,得先从Linux操作系统的启动说起。Linux 操作系统的启动首先从 BIOS 开始,然后由 Boot Loader 载入内核,并初始化内核。内核初始化的最后一步就是启动 init 进程。这个进程是系统的第一个进程,PID 为 1,又叫超级进程,也叫根进程。它负责产生其他所有用户进程。所有的进程都会被挂在这个进程下,如果这个进程退出了,那么所有的进程都被 kill 。如果一个子进程的父进程退了,那么这个子进程会被挂到 PID 1 下面。(注:PID 0 是内核的一部分,主要用于内进换页,参看:Process identifier)
SysV Init
PID 1 这个进程非常特殊,其主要就任务是把整个操作系统带入可操作的状态。比如:启动 UI – Shell 以便进行人机交互,或者进入 X 图形窗口。传统上,PID 1 和传统的 Unix System V 相兼容的,所以也叫 sysvinit,这是使用得最悠久的 init 实现。Unix System V 于1983年 release。
在 sysvint 下,有好几个运行模式,又叫 runlevel。比如:常见的 3 级别指定启动到多用户的字符命令行界面,5 级别指定启起到图形界面,0 表示关机,6 表示重启。其配置在 /etc/inittab 文件中。
与此配套的还有 /etc/init.d/ 和 /etc/rc[X].d,前者存放各种进程的启停脚本(需要按照规范支持 start,stop子命令),后者的 X 表示不同的 runlevel 下相应的后台进程服务,如:/etc/rc3.d 是 runlevel=3 的。 里面的文件主要是 link 到 /etc/init.d/ 里的启停脚本。其中也有一定的命名规范:S 或 K 打头的,后面跟一个数字,然后再跟一个自定义的名字,如:S01rsyslog,S02ssh。S 表示启动,K表示停止,数字表示执行的顺序。
UpStart
Unix 和 Linux 在 sysvint 运作多年后,大约到了2006年的时候,Linux内核进入2.6时代,Linux有了很多更新。并且,Linux开始进入桌面系统,而桌面系统和服务器系统不一样的是,桌面系统面临频繁重启,而且,用户会非常频繁的使用硬件的热插拔技术。于是,这些新的场景,让 sysvint 受到了很多挑战。
比如,打印机需要CUPS等服务进程,但是如果用户没有打机印,启动这个服务完全是一种浪费,而如果不启动,如果要用打印机了,就无法使用,因为sysvint 没有自动检测的机制,它只能一次性启动所有的服务。另外,还有网络盘挂载的问题。在 /etc/fstab 中,负责硬盘挂载,有时候还有网络硬盘(NFS 或 iSCSI)在其中,但是在桌面机上,有很可能开机的时候是没有网络的, 于是网络硬盘都不可以访问,也无法挂载,这会极大的影响启动速度。sysvinit 采用 netdev 的方式来解决这个问题,也就是说,需要用户自己在 /etc/fstab 中给相应的硬盘配置上 netdev 属性,于是 sysvint 启动时不会挂载它,只有在网络可用后,由专门的 netfs 服务进程来挂载。这种管理方式比较难以管理,也很容易让人掉坑。
所以,Ubuntu 开发人员在评估了当时几个可选的 init 系统后,决定重新设计这个系统,于是,这就是我们后面看到的 upstart 。 upstart 基于事件驱动的机制,把之前的完全串行的同步启动服务的方式改成了由事件驱动的异步的方式。比如:如果有U盘插入,udev 得到通知,upstart 感知到这个事件后触发相应的服务程序,比如挂载文件系统等等。因为使用一个事件驱动的玩法,所以,启动操作系统时,很多不必要的服务可以不用启动,而是等待通知,lazy 启动。而且事件驱动的好处是,可以并行启动服务,他们之间的依赖关系,由相应的事件通知完成。
upstart 有着很不错的设计,其中最重要的两个概念是 Job 和 Event。
Job 有一般的Job,也有service的Job,并且,upstart 管理了整个 Job 的生命周期,比如:Waiting, Starting, pre-Start, Spawned, post-Start, Running, pre-Stop, Stopping, Killed, post-Stop等等,并维护着这个生命周期的状态机。
Event 分成三类,signal, method 和 hooks。signal 就是异步消息,method 是同步阻塞的。hooks 也是同步的,但介于前面两者之间,发出hook事件的进程必须等到事件完成,但不检查是否成功。
但是,upstart 的事件非常复杂,也非常纷乱,各种各样的事件(事件没有归好类)导致有点凌乱。不过因为整个事件驱动的设计比之前的 sysvinit 来说好太多,所以,也深得欢迎。
Systemd
直到2010的有一天,一个在 RedHat工作的工程师 Lennart Poettering 和 Kay Sievers ,开始引入了一个新的 init 系统—— systemd。这是一个非常非常有野心的项目,这个项目几乎改变了所有的东西,systemd 不但想取代已有的 init 系统,而且还想干更多的东西。
Lennart 同意 upstart 干的不错,代码质量很好,基于事件的设计也很好。但是他觉得 upstart 也有问题,其中最大的问题还是不够快,虽然 upstart 用事件可以达到一定的启动并行度,但是,本质上来说,这些事件还是会让启动过程串行在一起。 如:NetworkManager 在等 D-Bus 的启动事件,而 D-Bus 在等 syslog 的启动事件。
Lennart 认为,实现上来说,upstart 其实是在管理一个逻辑上的服务依赖树,但是这个服务依赖树在表现形式上比较简单,你只需要配置——“启动 B好了就启动A”或是“停止了A后就停止B”这样的规则。但是,Lennart 说,这种简单其实是有害的(this simplification is actually detrimental)。他认为,
-
从一个系统管理的角度出来,他一开始会设定好整个系统启动的服务依赖树,但是这个系统管理员要人肉的把这个本来就非常干净的服务依整树给翻译成计算机看的懂的 Event/Action 形式,而且 Event/Action 这种配置方式是运行时的,所以,你需要运行起来才知道是什么样的。
-
Event逻辑从头到脚到处都是,这个事件扩大了运维的复杂度,还不如之前的
sysvint。 也就是说,当用户配置了 “启动D-Bus后请启动NetworkManager”, 这个upstart可以干,但是反过来,如果,用户启动NetworkManager,我们应该先去启动他的前置依赖D-Bus,然而你还要配置相应的反向 Event。本来,我只需要配置一条依赖的,结果现在我要配置很多很多情况下的Event。 -
最后,
upstart里的 Event 的并不标准,很混乱,没有良好的定义。比如:既有,进程启动,运行,停止的事件,也有USB设备插入、可用、拔出的事件,还有文件系统设备being mounted、 mounted 和 umounted 的事件,还有AC电源线连接和断开的事件。你会发现,这进程启停的、USB的、文件系统的、电源线的事件,看上去长得很像, 但是没有被标准化抽像出来掉,因为绝大多数的事件都是三元组:start, condition, stop 。这种概念设计模型并没有在upstart中出现。因为upstart被设计为单一的事件,而忽略了逻辑依赖。
当然,如果 systemd 只是解决 upstart 的问题,他就改造 upstart 就好了,但是 Lennart 的野心不只是想干个这样的事,他想干的更多。
首先,systemd 清醒的认识到了 init 进程的首要目标是要让用户快速的进入可以操作OS的环境,所以,这个速度一定要快,越快越好,所以,systemd 的设计理念就是两条:
- To start less.
- And to start more in parallel.
也就是说,按需启动,能不启动就不启动,如果要启动,能并行启动就并行启动,包括你们之间有依赖,我也并行启动。按需启动还好理解,那么,有依赖关系的并行启动,它是怎么做到的?这里,systemd 借鉴了 MacOS 的 Launchd 的玩法(在Youtube上有一个分享——Launchd: One Program to Rule them All,在苹果的开源网站上也有相关的设计文档——About Daemons and Services)
要解决这些依赖性,systemd 需要解决好三种底层依赖—— Socket, D-Bus ,文件系统。
-
Socket依赖。如果服务C依赖于服务S的socket,那么就要先启动S,然后再启动C,因为如果C启动时找不到S的Socket,那么C就会失败。
systemd可以帮你在S还没有启动好的时候,建立一个socket,用来接收所有的C的请求和数据,并缓存之,一旦S全部启动完成,把systemd替换好的这个缓存的数据和Socket描述符替换过去。 -
D-Bus依赖。
D-Bus全称 Desktop Bus,是一个用来在进程间通信的服务。除了用于用户态进程和内核态进程通信,也用于用户态的进程之前。现在,很多的现在的服务进程都用D-Bus而不是Socket来通信。比如:NetworkManager就是通过D-Bus和其它服务进程通讯的,也就是说,如果一个进程需要知道网络的状态,那么就必需要通过D-Bus通信。D-Bus支持 “Bus Activation”的特性。也就是说,A要通过D-Bus服务和B通讯,但是B没有启动,那么D-Bus可以把B起来,在B启动的过程中,D-Bus帮你缓存数据。systemd可以帮你利用好这个特性来并行启动 A 和 B。 -
文件系统依赖。系统启动过程中,文件系统相关的活动是最耗时的,比如挂载文件系统,对文件系统进行磁盘检查(fsck),磁盘配额检查等都是非常耗时的操作。在等待这些工作完成的同时,系统处于空闲状态。那些想使用文件系统的服务似乎必须等待文件系统初始化完成才可以启动。
systemd参考了autofs的设计思路,使得依赖文件系统的服务和文件系统本身初始化两者可以并发工作。autofs可以监测到某个文件系统挂载点真正被访问到的时候才触发挂载操作,这是通过内核automounter模块的支持而实现的。比如一个open()系统调用作用在某个文件系统上的时候,而这个文件系统尚未执行挂载,此时open()调用被内核挂起等待,等到挂载完成后,控制权返回给open()系统调用,并正常打开文件。这个过程和autofs是相似的。
下图来自 Lennart 的演讲里的一页PPT,展示了不同 init 系统的启动。
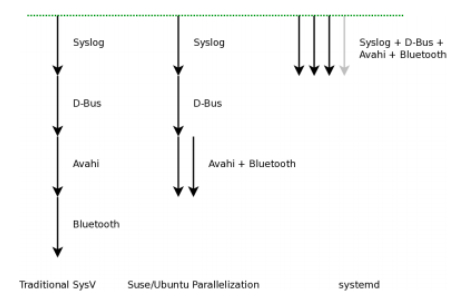
除此之外,systemd 还在启动时管理好了一些下面的事。
用C语言取代传统的脚本式的启动。前面说过,sysvint 用 /etc/rcX.d 下的各种脚本启动。然而这些脚本中需要使用 awk, sed, grep, find, xargs 等等这些操作系统的命令,这些命令需要生成进程,生成进程的开销很大,关键是生成完这些进程后,这个进程就干了点屁大的事就退了。换句话说就是,我操作系统干了那么多事为你拉个进程起来,结果你就把个字串转成小写就退了,把我操作系统当什么了?
在正常的一个 sysvinit 的脚本里,可能会有成百上千个这样的命令。所以,慢死。因此,systemd 全面用 C 语言全部取代了。一般来说,sysvinit 下,操作系统启动完成后,用 echo $$ 可以看到,pid 被分配到了上千的样子,而 systemd 的系统只是上百。
另外,systemd 是真正一个可以管住服务进程的——可以跟踪上服务进程所fork/exec出来的所有进程。
-
我们知道, 传统 Unix/Linux 的 Daemon 服务进程的最佳实践基本上是这个样子的(具体过程可参看这篇文章“[SysV Daemon](http://0pointer.de/public/systemd-man/daemon.html#SysV Daemons)”)
- 进程启动时,关闭所有的打开的文件描述符(除了标准描述符0,1,2),然后重置所有的信号处理。
- 调用
fork()创建子进程,在子进程中setsid(),然后父进程退出(为了后台执行) - 在子进程中,再调用一次
fork(),创建孙子进程,确定没有交互终端。然后子进程退出。 - 在孙子进程中,把标准输入标准输出标准错误都连到
/dev/null上,还要创建 pid 文件,日志文件,处理相关信号 …… - 最后才是真正开始提供服务。
-
在上面的这个过程中,服务进程除了两次
fork外还会fork出很多很多的子进程(比如说一些Web服务进程,会根据用户的请求链接来fork子进程),这个进程树是相当难以管理的,因为,一旦父进程退出来了,子进程就会被挂到 PID 1下,所以,基本上来说,你无法通过服务进程自已给定的一个pid文件来找到所有的相关进程(这个对开发者的要求太高了),所以,在传统的方式下用脚本启停服务是相当相当的 Buggy 的,因为无法做对所有的服务生出来的子子孙孙做到监控。 -
为了解决这个问题,
upstart通过变态的strace来跟踪进程中的fork()和exec()或exit()等相关的系统调用。这种方法相当笨拙。systemd使用了一个非常有意思的玩法来 tracking 服务进程生出来的所有进程,那就是用cgroup(我在 Docker 的基础技术“cgroup篇”中讲过这个东西)。cgroup主要是用来管理进程组资源配额的事,所以,无论服务如何启动新的子进程,所有的这些相关进程都会同属于一个cgroup,所以,systemd只需要简单的去遍历一下相应的cgroup的那个虚文件系统目录下的文件,就可以正确的找到所有的相关进程,并将他们一一停止。
另外,systemd 简化了整个 daemon 开发的过程:
- 不需要两次
fork(),只需要实现服务本身的主逻辑就可以了。 - 不需要
setsid(),systemd会帮你干 - 不需要维护
pid文件,systemd会帮处理。 - 不需要管理日志文件或是使用
syslog,或是处理HUP的日志reload信号。把日志打到stderr上,systemd帮你管理。 - 处理
SIGTERM信号,这个信号就是正确退出当前服务,不要做其他的事。 - ……
除此之外,systemd 还能——
- 自动检测启动的服务间有没有环形依赖。
- 内建 autofs 自动挂载管理功能。
- 日志服务。
systemd改造了传统的 syslog 的问题,采用二进制格式保存日志,日志索引更快。 - 快照和恢复。对当前的系统运行的服务集合做快照,并可以恢复。
- ……
还有好多好多,他接管很多很多东西,于是就让很多人不爽了,因为他在干了很多本不属于 PID 1 的事。
Systemd 争论和八卦
于是 systemd 这个东西成了可能是有史以来口水战最多的一个开源软件了。systemd 饱受各种争议,最大的争议就是他破坏了 Unix 的设计哲学(相关的哲学可以读一下《Unix编程艺术》),干了一个大而全而且相当复杂的东西。当然,Lennart 并不同意这样的说法,他后来又写一篇blog “The Biggest Myths”来解释 systemd 并不是这样的,大家可以前往一读。
这个争议大到什么样子呢?2014 年,Debian Linux 因为想准备使用 systemd 来作为标准的 init 守护进程来替换 sysvinit 。而围绕这个事的争论达到了空前的热度,争论中充满着仇恨,systemd 的支持者和反对者都在互相辱骂,导致当时 Debian 阵营开始分裂。还有人给 Lennart 发了死亡威胁的邮件,用比特币雇凶买杀手,扬言要取他的性命,在Youbute上传了侮辱他的歌曲,在IRC和各种社交渠道上给他发下流和侮辱性的消息。这已经不是争议了,而是一种不折不扣的仇恨!
于是,Lennart 在 Google Plus 上发了贴子,批评整个 Linux 开源社区和 Linus 本人。他大意说,
这个社区太病态了,全是 ass holes,你们不停用各种手段在各种地方用不同的语言和方式来侮辱和漫骂我。我还是一个年轻人,我从来没有经历过这样的场面,但是今天我已经对这种场面很熟悉了。我有时候说话可能不准确,但是我不会像他样那样说出那样的话,我也没有被这些事影响,因为我脸皮够厚,所以,为什么我可以在如何大的反对声面前让
systemd成功,但是,你们 Linux 社区太可怕了。你们里面的有精神病的人太多了。另外,对于Linus Torvalds,你是这个社区的 Role Model,但可惜你是一个 Bad Role Model,你在社区里的刻薄和侮辱性的言行,基本从一定程度上鼓励了其它人跟你一样,当然,并不只是你一个人的问题,而是在你周围聚集了一群和你一样的这样干的人。送你一句话—— A fish rots from the head down !一条鱼是从头往下腐烂的……
这篇契文很长,喜欢八卦的同学可以前往一读。感受一下 Lennart 当时的心态(我觉得能算上是非常平稳了)。
Linus也在被一媒体问起 systemd 这个事来(参看“Torvalds says he has no strong opinions on systemd”),Linus在采访里说,
我对
systemd和 Lennart 的贴子没有什么强烈的想法。虽然,传统的 Unix 设计哲学—— “Do one thing and Do it well”,很不错,而且我们大多数人也实践了这么多年,但是这并不代表所有的真实世界。在历史上,也不只有systemd这么干过。但是,我个人还是 old-fashioned 的人,至少我喜欢文本式的日志,而不是二进制的日志。但是systemd没有必要一定要有这样的品味。哦,我说细节了……
今天,systemd 占据了几乎所有的主流的 Linux 发行版的默认配置,包括:Arch Linux、CentOS、CoreOS、Debian、Fedora、Megeia、OpenSUSE、RHEL、SUSE企业版和 Ubuntu。而且,对于 CentOS, CoreOS, Fedora, RHEL, SUSE这些发行版来说,不能没有 systemd。(Ubuntu 还有一个不错的wiki – Systemd for Upstart Users 阐述了如何在两者间切换)
其它
还记得在《缓存更新的套路》一文中,我说过,如果你要做好架构,首先你得把计算机体系结构以及很多老古董的基础技术吃透了。因为里面会有很多可以借鉴和相通的东西。那么,你是否从这篇文章里看到了一些有分布式架构相似的东西?
比如:从 sysvinit 到 upstart 再到 systemd,像不像是服务治理?Linux系统下的这些服务进程,是不是很像分布式架构中的微服务?还有那个D-Bus,是不是很像SOA里的ESB?而 init 系统是不是很像一个控制系统?甚至像一个服务编排(Service Orchestration)系统?
分布式系统中的服务之间也有很多依赖,所以,在启动一个架构的时候,如果我们可以做到像 systemd 那样并行启动的话,那么是不是就像是一个微服务的玩法了?
嗯,你会发现,技术上的很多东西是相通的,也是互相有对方的影子,所以,其实技术并不多。关键是我们学在了表面还是看到了本质。
命令
Systemd 是 Linux 系统工具,用来启动守护进程,已成为大多数发行版的标准配置。
系统管理
Systemd 并不是一个命令,而是一组命令,涉及到系统管理的方方面面。
systemctl
systemctl是 Systemd 的主命令,用于管理系统。
# 重启系统
$ sudo systemctl reboot
# 关闭系统,切断电源
$ sudo systemctl poweroff
# CPU停止工作
$ sudo systemctl halt
# 暂停系统
$ sudo systemctl suspend
# 让系统进入冬眠状态
$ sudo systemctl hibernate
# 让系统进入交互式休眠状态
$ sudo systemctl hybrid-sleep
# 启动进入救援状态(单用户状态)
$ sudo systemctl rescue
systemd-analyze
systemd-analyze命令用于查看启动耗时。
# 查看启动耗时
$ systemd-analyze
# 查看每个服务的启动耗时
$ systemd-analyze blame
# 显示瀑布状的启动过程流$
$ systemd-analyze critical-chain
# 显示指定服务的启动流
$ systemd-analyze critical-chain atd.service
hostnamectl
hostnamectl命令用于查看当前主机的信息。
# 显示当前主机的信息
$ hostnamectl
# 设置主机名。
$ sudo hostnamectl set-hostname rhel7
localectl
localectl命令用于查看本地化设置。
# 查看本地化设置
$ localectl
# 设置本地化参数。
$ sudo localectl set-locale LANG=en_GB.utf8
$ sudo localectl set-keymap en_GB
timedatectl
timedatectl命令用于查看当前时区设置。
# 查看当前时区设置
$ timedatectl
# 显示所有可用的时区
$ timedatectl list-timezones
# 设置当前时区
$ sudo timedatectl set-timezone America/New_York
$ sudo timedatectl set-time YYYY-MM-DD
$ sudo timedatectl set-time HH:MM:SS
loginctl
loginctl命令用于查看当前登录的用户。
# 列出当前session
$ loginctl list-sessions
# 列出当前登录用户
$ loginctl list-users
# 列出显示指定用户的信息
$ loginctl show-user ruanyf
Unit
含义
Systemd 可以管理所有系统资源。不同的资源统称为 Unit(单元)。简单说,单元就是 Systemd 的最小功能单位,是单个进程的描述。一个个小的单元互相调用和依赖,组成一个庞大的任务管理系统,这就是 Systemd 的基本思想。
由于 Systemd 要做的事情太多,导致单元有很多不同的种类,大概一共有12种。
- Service unit:系统服务
- Target unit:多个 Unit 构成的一个组
- Device Unit:硬件设备
- Mount Unit:文件系统的挂载点
- Automount Unit:自动挂载点
- Path Unit:文件或路径
- Scope Unit:不是由 Systemd 启动的外部进程
- Slice Unit:进程组,资源分配
- Snapshot Unit:Systemd 快照,可以切回某个快照
- Socket Unit:进程间通信的 socket
- Swap Unit:swap 文件
- Timer Unit:定时器
systemctl list-units命令可以查看当前系统的所有 Unit 。
# 列出正在运行的 Unit
$ systemctl list-units
# 列出所有Unit,包括没有找到配置文件的或者启动失败的
$ systemctl list-units --all
# 列出所有没有运行的 Unit
$ systemctl list-units --all --state=inactive
# 列出所有加载失败的 Unit
$ systemctl list-units --failed
# 列出所有正在运行的、类型为 service 的 Unit
$ systemctl list-units --type=service
Unit 的状态
systemctl status命令用于查看系统状态和单个 Unit 的状态。
# 显示系统状态
$ systemctl status
# 显示单个 Unit 的状态
$ sysystemctl status bluetooth.service
# 显示远程主机的某个 Unit 的状态
$ systemctl -H root@rhel7.example.com status httpd.service
例如查看 httpd 状态
$ sudo systemctl status httpd
httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled)
Active: active (running) since 金 2014-12-05 12:18:22 JST; 7min ago
Main PID: 4349 (httpd)
Status: "Total requests: 1; Current requests/sec: 0; Current traffic: 0 B/sec"
CGroup: /system.slice/httpd.service
├─4349 /usr/sbin/httpd -DFOREGROUND
├─4350 /usr/sbin/httpd -DFOREGROUND
├─4351 /usr/sbin/httpd -DFOREGROUND
├─4352 /usr/sbin/httpd -DFOREGROUND
├─4353 /usr/sbin/httpd -DFOREGROUND
└─4354 /usr/sbin/httpd -DFOREGROUND
12月 05 12:18:22 localhost.localdomain systemd[1]: Starting The Apache HTTP Server...
12月 05 12:18:22 localhost.localdomain systemd[1]: Started The Apache HTTP Server.
12月 05 12:22:40 localhost.localdomain systemd[1]: Started The Apache HTTP Server.
上面的输出结果含义如下。
Loaded行:配置文件的位置,是否设为开机启动Active行:表示正在运行Main PID行:主进程IDStatus行:由应用本身(这里是 httpd )提供的软件当前状态CGroup块:应用的所有子进程- 日志块:应用的日志
除了status命令,systemctl还提供了三个查询状态的简单方法,主要供脚本内部的判断语句使用。
# 显示某个 Unit 是否正在运行
$ systemctl is-active application.service
# 显示某个 Unit 是否处于启动失败状态
$ systemctl is-failed application.service
# 显示某个 Unit 服务是否建立了启动链接
$ systemctl is-enabled application.service
Unit 管理
对于用户来说,最常用的是下面这些命令,用于启动和停止 Unit(主要是 service)。
# 立即启动一个服务
$ sudo systemctl start apache.service
# 立即停止一个服务
$ sudo systemctl stop apache.service
# 重启一个服务
$ sudo systemctl restart apache.service
# 杀死一个服务的所有子进程
$ sudo systemctl kill apache.service
# 重新加载一个服务的配置文件
$ sudo systemctl reload apache.service
# 重载所有修改过的配置文件
$ sudo systemctl daemon-reload
# 显示某个 Unit 的所有底层参数
$ systemctl show httpd.service
# 显示某个 Unit 的指定属性的值
$ systemctl show -p CPUShares httpd.service
# 设置某个 Unit 的指定属性
$ sudo systemctl set-property httpd.service CPUShares=500
有时候,该命令可能没有响应,执行systemctl stop服务停不下来。这时候就不得不"杀进程"了,向正在运行的进程发出kill信号,执行systemctl kill。
依赖关系
Unit 之间存在依赖关系:A 依赖于 B,就意味着 Systemd 在启动 A 的时候,同时会去启动 B。
systemctl list-dependencies命令列出一个 Unit 的所有依赖。
systemctl list-dependencies nginx.service
上面命令的输出结果之中,有些依赖是 Target 类型(详见下文),默认不会展开显示。如果要展开 Target,就需要使用--all参数。
systemctl list-dependencies --all nginx.service
Unit 的配置文件
概述
每一个 Unit 都有一个配置文件,告诉 Systemd 怎么启动这个 Unit 。
除了系统默认的单元文件/lib/systemd/system,Systemd 默认从目录/etc/systemd/system/读取配置文件。但是,里面存放的大部分文件都是符号链接,指向目录/usr/lib/systemd/system/。那些支持 Systemd 的软件,安装的时候,也会自动在/usr/lib/systemd/system目录添加一个配置文件。
systemctl enable命令用于在/etc/systemd/system/和/usr/lib/systemd/system之间,建立符号链接关系。
$ sudo systemctl enable clamd@scan.service
# 等同于
$ sudo ln -s '/usr/lib/systemd/system/clamd@scan.service' '/etc/systemd/system/multi-user.target.wants/clamd@scan.service'
如果配置文件里面设置了开机启动,systemctl enable命令相当于激活开机启动。
与之对应的,systemctl disable命令用于在两个目录之间,撤销符号链接关系,相当于撤销开机启动。
sudo systemctl disable clamd@scan.service
配置文件的后缀名,就是该 Unit 的种类,比如sshd.socket。如果省略,Systemd 默认后缀名为.service,所以sshd会被理解成sshd.service。
设置开机启动以后,软件并不会立即启动,必须等到下一次开机。如果想现在就运行该软件,那么要执行systemctl start命令。
配置文件的状态
systemctl list-unit-files命令用于列出所有配置文件。
# 列出所有配置文件
$ systemctl list-unit-files
# 列出指定类型的配置文件
$ systemctl list-unit-files --type=service
这个命令会输出一个列表。
systemctl list-unit-filesUNIT FILE STATEchronyd.service enabledclamd@.service staticclamd@scan.service disabled
这个列表显示每个配置文件的状态,一共有四种。
- enabled:已建立启动链接
- disabled:没建立启动链接
- static:该配置文件没有
[Install]部分(无法执行),只能作为其他配置文件的依赖 - masked:该配置文件被禁止建立启动链接
注意,从配置文件的状态无法看出,该 Unit 是否正在运行。这必须执行前面提到的systemctl status命令。
systemctl status bluetooth.service
一旦修改配置文件,就要让 Systemd 重新加载配置文件,然后重新启动,否则修改不会生效。
sudo systemctl daemon-reload
sudo systemctl restart httpd.service
配置文件的格式
配置文件就是普通的文本文件,可以用文本编辑器打开。
systemctl cat命令可以查看配置文件的内容。
$ systemctl cat sshd.service
[Unit]
Description=OpenSSH server daemon
Documentation=man:sshd(8) man:sshd_config(5)
After=network.target sshd-keygen.service
Wants=sshd-keygen.service
[Service]
EnvironmentFile=/etc/sysconfig/sshd
ExecStart=/usr/sbin/sshd -D $OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
Type=simpleKill
Mode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
从上面的输出可以看到,配置文件分成几个区块。每个区块的第一行,是用方括号表示的区别名,比如[Unit]。注意,配置文件的区块名和字段名,都是大小写敏感的。
每个区块内部是一些等号连接的键值对。
[Section]
Directive1=value
Directive2=value
. . .
注意,键值对的等号两侧不能有空格。
配置文件的区块
[Unit]区块通常是配置文件的第一个区块,用来定义 Unit 的元数据,以及配置与其他 Unit 的关系。它的主要字段如下。
-
Description:当前服务的简单描述 -
Documentation:文档地址 -
启动顺序
Before:如果该字段指定的 Unit 也要启动,那么必须在当前 Unit 之后启动After:如果该字段指定的 Unit 也要启动,那么必须在当前 Unit 之前启动。如network.target或sshd-keygen.service需要启动,那么sshd.service应该在它们之后启动。
-
依赖关系:
举例来说,某 Web 应用需要 postgresql 数据库储存数据。在配置文件中,
Before、After只定义要在 postgresql 之后启动,而没有定义依赖 postgresql 。上线后,由于某种原因,postgresql 需要重新启动,在停止服务期间,该 Web 应用就会无法建立数据库连接。注意,
Wants字段与Requires字段只涉及依赖关系,与启动顺序无关,默认情况下是同时启动的。Wants:与当前 Unit 配合的其他 Unit,如果它们没有运行,当前 Unit 不会启动失败。如sshd.service与sshd-keygen.service之间存在"弱依赖"关系,即如果"sshd-keygen.service"启动失败或停止运行,不影响sshd.service继续执行。Requires:当前 Unit 依赖的其他 Unit,如果它们没有运行,当前 Unit 会启动失败。Requires字段则表示"强依赖"关系,即如果该服务启动失败或异常退出,那么sshd.service也必须退出。
-
BindsTo:与Requires类似,它指定的 Unit 如果退出,会导致当前 Unit 停止运行 -
Conflicts:这里指定的 Unit 不能与当前 Unit 同时运行 -
Condition...:当前 Unit 运行必须满足的条件,否则不会运行 -
Assert...:当前 Unit 运行必须满足的条件,否则会报启动失败 -
StartLimitIntervalSec=interval, StartLimitBurst=burst:设置单元的启动频率限制。 也就是该单元在interval时间内最多允许启动burst次。
[Service]区块用来定义如何启动当前服务,只有 Service 类型的 Unit 才有这个区块。它的主要字段如下。
-
EnvironmentFile字段:指定当前服务的环境参数文件。该文件内部的key=value键值对,可以用$key的形式,在当前配置文件中获取。sshd 的环境参数文件是/etc/sysconfig/sshd。 -
ExecStart字段:定义启动进程时执行的命令。是配置文件里面最重要的字段。上面的例子中,启动sshd,执行的命令是/usr/sbin/sshd -D $OPTIONS,其中的变量$OPTIONS就来自EnvironmentFile字段指定的环境参数文件。与之作用相似的,还有如下这些字段。ExecReload字段:重启服务时执行的命令ExecStop字段:停止服务时执行的命令ExecStartPre字段:启动服务之前执行的命令ExecStartPost字段:启动服务之后执行的命令ExecStopPost字段:停止服务之后执行的命令
-
Type:字段定义启动类型。它可以设置的值如下。- simple(默认值):
ExecStart字段启动的进程为主进程 - forking:
ExecStart字段将以fork()方式启动,此时父进程将会退出,子进程将成为主进程 - oneshot:类似于
simple,但只执行一次,Systemd 会等它执行完,才启动其他服务 - dbus:类似于
simple,但会等待 D-Bus 信号后启动 - notify:类似于
simple,启动结束后会发出通知信号,然后 Systemd 再启动其他服务 - idle:类似于
simple,但是要等到其他任务都执行完,才会启动该服务。一种使用场合是为让该服务的输出,不与其他服务的输出相混合
- simple(默认值):
-
KillMode字段:定义 Systemd 如何停止服务。- control-group(默认值):当前控制组里面的所有子进程,都会被杀掉
- process:只杀主进程。比如sshd的
KillMode设为process,子进程打开的 SSH session 仍然保持连接。 - mixed:主进程将收到 SIGTERM 信号,子进程收到 SIGKILL 信号
- none:没有进程会被杀掉,只是执行服务的 stop 命令。
-
Restart:Restart字段:定义了服务退出后,Systemd 重启该服务的方式。- no(默认值):退出后不会重启
- on-success:只有正常退出时(退出状态码为0),才会重启
- on-failure:非正常退出时(退出状态码非0),包括被信号终止和超时,才会重启。比如sshd任何意外的失败,都将重启sshd;如果 sshd 正常停止(比如执行
systemctl stop命令),它就不会重启。对于守护进程,推荐设为on-failure。 - on-abnormal:只有被信号终止和超时,才会重启。对于那些允许发生错误退出的服务,可以设为
on-abnormal。 - on-abort:只有在收到没有捕捉到的信号终止时,才会重启
- on-watchdog:超时退出,才会重启
- always:不管是什么退出原因,总是重启
退出原因(↓) | Restart= (→) noalwayson-successon-failureon-abnormalon-aborton-watchdog正常退出 X X 退出码不为"0" X X 进程被强制杀死 X X X X systemd 操作超时 X X X 看门狗超时 X X X X -
RestartSec字段:表示 Systemd 重启服务之前,需要等待的秒数。 -
TimeoutSec:定义 Systemd 停止当前服务之前等待的秒数
所有的启动设置之前,都可以加上一个连词号(-),表示"抑制错误",即发生错误的时候,不影响其他命令的执行。比如,EnvironmentFile=-/etc/sysconfig/sshd(注意等号后面的那个连词号),就表示即使/etc/sysconfig/sshd文件不存在,也不会抛出错误。
[Install]通常是配置文件的最后一个区块,定义如何安装这个配置文件,即怎样做到开机启动。它的主要字段如下。
WantedBy字段:表示该服务所在的 Target,它的值是一个或多个 Target。Target的含义是服务组,表示一组服务。WantedBy=multi-user.target指的是,sshd 所在的 Target 是multi-user.target。当前 Unit 激活时(enable)符号链接会放入/etc/systemd/system目录下面[Target 名].wants子目录中,如multi-user.target.wants子目录。RequiredBy:它的值是一个或多个 Target,当前 Unit 激活时,符号链接会放入/etc/systemd/system目录下面以 Target 名 +.required后缀构成的子目录中Alias:当前 Unit 可用于启动的别名Also:当前 Unit 激活(enable)时,会被同时激活的其他 Unit
Unit 配置文件的完整字段清单,请参考官方文档。
Target
启动计算机的时候,需要启动大量的 Unit。如果每一次启动,都要一一写明本次启动需要哪些 Unit,显然非常不方便。Systemd 的解决方案就是 Target。
简单说,Target 就是一个 Unit 组,包含许多相关的 Unit 。启动某个 Target 的时候,Systemd 就会启动里面所有的 Unit。从这个意义上说,Target 这个概念类似于"状态点",启动某个 Target 就好比启动到某种状态。
传统的init启动模式里面,有 RunLevel 的概念,跟 Target 的作用很类似。不同的是,RunLevel 是互斥的,不可能多个 RunLevel 同时启动,但是多个 Target 可以同时启动。
# 查看当前系统的所有 Target
$ systemctl list-unit-files --type=target
# 查看一个 Target 包含的所有 Unit
$ systemctl list-dependencies multi-user.target
# 查看启动时的默认 Target,在这个组里的所有服务,都将开机启动。
$ systemctl get-default
# 设置启动时的默认 Target
$ sudo systemctl set-default multi-user.target
# 切换 Target 时,默认不关闭前一个 Target 启动的进程,
# systemctl isolate 命令改变这种行为,
# 关闭前一个 Target 里面所有不属于后一个 Target 的进程
$ sudo systemctl isolate multi-user.target
Target 与 传统 RunLevel 的对应关系如下。
Traditional runlevel New target name Symbolically linked to...
Runlevel 0 | runlevel0.target -> poweroff.target
Runlevel 1 | runlevel1.target -> rescue.target
Runlevel 2 | runlevel2.target -> multi-user.target
Runlevel 3 | runlevel3.target -> multi-user.target
Runlevel 4 | runlevel4.target -> multi-user.target
Runlevel 5 | runlevel5.target -> graphical.target
Runlevel 6 | runlevel6.target -> reboot.target
它与init进程的主要差别如下。
(1)默认的 RunLevel(在/etc/inittab文件设置)现在被默认的 Target 取代,位置是/etc/systemd/system/default.target,通常符号链接到graphical.target(图形界面)或者multi-user.target(多用户命令行)。
(2)启动脚本的位置,以前是/etc/init.d目录,符号链接到不同的 RunLevel 目录 (比如/etc/rc3.d、/etc/rc5.d等),现在则存放在/lib/systemd/system和/etc/systemd/system目录。
(3)配置文件的位置,以前init进程的配置文件是/etc/inittab,各种服务的配置文件存放在/etc/sysconfig目录。现在的配置文件主要存放在/lib/systemd目录,在/etc/systemd目录里面的修改可以覆盖原始设置。
日志管理
Systemd 统一管理所有 Unit 的启动日志。带来的好处就是,可以只用journalctl一个命令,查看所有日志(内核日志和应用日志)。日志的配置文件是/etc/systemd/journald.conf。
journalctl功能强大,用法非常多。
# 查看所有日志(默认情况下 ,只保存本次启动的日志)
$ sudo journalctl
# 查看内核日志(不显示应用日志)
$ sudo journalctl -k
# 查看系统本次启动的日志
$ sudo journalctl -b
$ sudo journalctl -b -0
# 查看上一次启动的日志(需更改设置)
$ sudo journalctl -b -1
# 查看指定时间的日志
$ sudo journalctl --since="2012-10-30 18:17:16"
$ sudo journalctl --since "20 min ago"
$ sudo journalctl --since yesterday
$ sudo journalctl --since "2015-01-10" --until "2015-01-11 03:00"
$ sudo journalctl --since 09:00 --until "1 hour ago"
# 显示尾部的最新10行日志
$ sudo journalctl -n
# 显示尾部指定行数的日志
$ sudo journalctl -n 20
# 实时滚动显示最新日志
$ sudo journalctl -f
# 查看指定服务的日志
$ sudo journalctl /usr/lib/systemd/systemd
# 查看指定进程的日志
$ sudo journalctl _PID=1
# 查看某个路径的脚本的日志
$ sudo journalctl /bin/bash
# 查看指定用户的日志
$ sudo journalctl _UID=33 --since today
# 查看某个 Unit 的日志
$ sudo journalctl -u nginx.service
$ sudo journalctl -u nginx.service --since today
# 实时滚动显示某个 Unit 的最新日志
$ sudo journalctl -u nginx.service -f
# 合并显示多个 Unit 的日志
$ journalctl -u nginx.service -u php-fpm.service --since today
# 查看指定优先级(及其以上级别)的日志,共有8级
# 0: emerg
# 1: alert
# 2: crit
# 3: err
# 4: warning
# 5: notice
# 6: info
# 7: debug
$ sudo journalctl -p err -b
# 日志默认分页输出,--no-pager 改为正常的标准输出
$ sudo journalctl --no-pager
# 以 JSON 格式(单行)输出
$ sudo journalctl -b -u nginx.service -o json
# 以 JSON 格式(多行)输出,可读性更好
$ sudo journalctl -b -u nginx.serviceqq -o json-pretty
# 显示日志占据的硬盘空间
$ sudo journalctl --disk-usage
# 指定日志文件占据的最大空间
$ sudo journalctl --vacuum-size=1G
# 指定日志文件保存多久
$ sudo journalctl --vacuum-time=1years
定时器示例
邮件脚本
先写一个发邮件的脚本mail.sh。
#!/usr/bin/env bash
echo "This is the body" | /usr/bin/mail -s "Subject" someone@example.com
上面代码的someone@example.com,请替换成你的邮箱地址。
然后,执行这个脚本。
bash mail.sh
执行后,你应该就会收到一封邮件,标题为Subject。
如果你的 Linux 系统不能发邮件,建议安装 ssmtp 或者 msmtp。另外,mail命令的用法,可以参考这里。
Service 单元
Service 单元就是所要执行的任务,比如发送邮件就是一种 Service。
新建 Service 非常简单,就是在/usr/lib/systemd/system目录里面新建一个文件,比如mytimer.service文件,你可以写入下面的内容。
[Unit]
Description=MyTimer
[Service]
ExecStart=/bin/bash /path/to/mail.sh
注意,定义的时候,所有路径都要写成绝对路径,比如bash要写成/bin/bash,否则 Systemd 会找不到。
现在,启动这个 Service。
sudo systemctl start mytimer.service
如果一切正常,你应该就会收到一封邮件。
Timer 单元
Service 单元只是定义了如何执行任务,要定时执行这个 Service,还必须定义 Timer 单元。
/usr/lib/systemd/system目录里面,新建一个mytimer.timer文件,写入下面的内容。
[Unit]
Description=Runs mytimer every hour
[Timer]
OnUnitActiveSec=1h
Unit=mytimer.service
[Install]
WantedBy=multi-user.target
这个 Timer 单元文件分成几个部分。
[Timer]部分定制定时器。Systemd 提供以下一些字段。
OnActiveSec:定时器生效后,多少时间开始执行任务OnBootSec:系统启动后,多少时间开始执行任务OnStartupSec:Systemd 进程启动后,多少时间开始执行任务OnUnitActiveSec:该单元上次执行后,等多少时间再次执行OnUnitInactiveSec: 定时器上次关闭后多少时间,再次执行OnCalendar:基于绝对时间,而不是相对时间执行AccuracySec:如果因为各种原因,任务必须推迟执行,推迟的最大秒数,默认是60秒Unit:真正要执行的任务,默认是同名的带有.service后缀的单元Persistent:如果设置了该字段,即使定时器到时没有启动,也会自动执行相应的单元WakeSystem:如果系统休眠,是否自动唤醒系统
上面的脚本里面,OnUnitActiveSec=1h表示一小时执行一次任务。其他的写法还有OnCalendar=*-*-* 02:00:00表示每天凌晨两点执行,OnCalendar=Mon *-*-* 02:00:00表示每周一凌晨两点执行,具体请参考中文手册。
System time
硬件时钟和系统时钟
系统用两个时钟保存时间:
-
硬件时钟(即实时时钟 RTC 或 CMOS 时钟)仅能保存:年、月、日、时、分、秒这些时间数值,无法保存时间标准(UTC 或 localtime)和是否使用夏令时调节。
-
系统时钟(即软件时间)与硬件时间分别维护,保存了:时间、时区和夏令时设置。Linux 内核保存为自 UTC 时间 1970 年1月1日经过的秒数。初始系统时钟是从硬件时间计算得来,计算时会考虑
/etc/adjtime的设置。系统启动之后,系统时钟与硬件时钟独立运行,Linux 通过时钟中断计数维护系统时钟。
大部分操作系统的时间管理包括如下方面:
- 启动时根据硬件时钟设置系统时间
- 运行时通过时间同步联网校正时间
- 关机时根据系统时间设置硬件时间
读取时间
下面命令可以获得硬件时间和系统时间:
$ timedatectl
Local time: Thu 2022-01-27 10:35:26 CST
Universal time: Thu 2022-01-27 02:35:26 UTC
RTC time: Thu 2022-01-27 02:35:26
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
- Local time 是系统时钟。
- RTC time 是硬件时钟,你会发现其与 Universal time 一样,即硬件时钟用 UTC。
- Time zone 是时区。
- System clock synchronized 是 ntp 时间同步是否成功。
- RTC in local TZ 是硬件时钟用地方时。
时间标准
时间表示有两个标准:localtime 和 UTC(Coordinated Universal Time) 。UTC 是与时区无关的全球时间标准。尽管概念上有差别,UTC 和 GMT (格林威治时间) 是一样的。localtime 标准则依赖于当前时区。
时间标准由操作系统设定,Windows 默认使用 localtime,Mac OS 默认使用 UTC,而 UNIX 系列的操作系统两者都有。使用 Linux 时,最好将硬件时钟设置为 UTC 标准,并在所有操作系统中使用。这样 Linux 系统就可以自动调整夏令时设置,而如果使用 localtime 标准那么系统时间不会根据夏令时自动调整。
通过如下命令可以检查当前设置,systemd 默认硬件时钟为协调世界时(UTC)。
$ timedatectl status | grep local
RTC in local TZ: no
将硬件时间设置为 localtime:
# timedatectl set-local-rtc 1
硬件时间设置成 UTC:
# timedatectl set-local-rtc 0
Windows 系统使用 UTC
Windows 操作系统将硬件时钟设置为 localtime。
Windows 其实也能处理 UTC,需要修改注册表。使用 regedit,新建如下 DWORD 值,并将其值设为十六进制的 1。
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation\RealTimeIsUniversal
也可以用管理员权限启动命令行来完成:
reg add "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\TimeZoneInformation" /v RealTimeIsUniversal /d 1 /t REG_DWORD /f
或者建立一个 .reg 文件并双击:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation]
"RealTimeIsUniversal"=dword:00000001
时区
检查当前时区:
timedatectl status
显示可用时区:
timedatectl list-timezones
修改时区:
# timedatectl set-timezone <Zone>/<SubZone>
# timedatectl set-timezone Asia/Shanghai
此命令会创建一个/etc/localtime软链接,指向/usr/share/zoneinfo/中的时区文件,如果手动创建此链接请确保是相对链接而不是绝对链接。
# ln -sf /usr/share/zoneinfo/Zone/SubZone /etc/localtime
时钟偏移
最能代表“真实时间”的是国际原子时钟),所有的时钟都是有误差的。电子时钟的时间是不准的,但是一般有固定的偏移。这种于基值的差称为“time skew”或“时间偏移”。用 hwclock 设置硬件时间时,会计算每天偏移的秒数。偏移值是原硬件时间与新设置硬件时间的差,并且考虑上次硬件时间设置时的偏移。新的偏移值会在设置时钟时写到文件 /etc/adjtime 。
注意: 如果硬件时间值与原值的差小于 24 小时,偏移量不会重新计算,因为时间过短,无法精确设置偏移。
如果硬件时钟总是过快或过慢,可能是计算了错误的偏移值。硬件时钟设置错误或者时间标准与其他操作系统不一致导致。删除文件 /etc/adjtime 可以删除偏移值,然后设置正确的硬件时钟和系统时钟,并检查时间标准是不是设置正确。
注意: 使用 Systemd 时,要使用 /etc/adjtime中的 drift 值(即无法或不想使用 NTP 时);需要每次调用 hwclock --adjust命令,可以通过 cron 任务实现。
时钟同步
网络时间协议 (NTP) 是一个通过包交换和可变延迟网络来同步计算机系统时间的协议。下列为这个协议的实现:
- NTP 守护进程是这个协议的参考实现,推荐用于时间服务器。它也可以调节中断频率和每秒滴答次数以减少系统时钟误差,使得硬件时钟每隔11秒重新同步一次。
- systemd-timesyncd 是一个简单的 SNTP 守护进程。它只实现了客户端,专用于从远程服务器查询时间,更适用于绝大部分安装的情形。
timedatectl:在最新的 Ubuntu 版本中,timedatectl替代了老旧的 ntpdate。默认情况下,timedatectl在系统启动的时候会立刻同步时间,并在稍后网络连接激活后通过 socket 再次检查一次。
timesyncd:在最新的 Ubuntu 版本中,timesyncd替代了 ntpd的客户端的部分。默认情况下 timesyncd会定期检测并同步时间。它还会在本地存储更新的时间,以便在系统重启时做时间单步调整。更多配置文件信息请参见 man timesyncd.conf:
时间服务器:默认情况下,基于 systemd 的工具都是从ntp.ubuntu.com请求时间同步的。自定义例如
$ sudo vim /etc/systemd/timesyncd.conf
NTP=ntp.aliyun.com cn.ntp.org.cn ntp.ntsc.ac.cn
- Windows系统上自带的两个:
time.windows.com和time.nist.gov - MacOS上自带的两个:
time.apple.com和time.asia.apple.com - NTP授时快速域名服务:
cn.ntp.org.cn - 中国科学院国家授时中心:
ntp.ntsc.ac.cn - 开源NTP服务器:
cn.pool.ntp.org - 阿里云授时服务器:
ntp.aliyun.com - 腾讯云授时服务器:
time1.cloud.tencent.com、time2.cloud.tencent.com、time3.cloud.tencent.com、time4.cloud.tencent.com、time5.cloud.tencent.com - 清华大学授时服务器:
ntp.tuna.tsinghua.edu.cn
要重新同步网络时间,可以重启ntp:
sudo systemctl restart systemd-timesyncd
sudo journalctl -f -u systemd-timesyncd
timedatectl timesync-status
其他
Firejail
防火墙
保障数据的安全性是继保障数据的可用性之后最为重要的一项工作。防火墙作为公网与内网之间的保护屏障,在保障数据的安全性方面起着至关重要的作用。
防火墙管理工具
众所周知,相较于企业内网,外部的公网环境更加恶劣,罪恶丛生。在公网与企业内网之间充当保护屏障的防火墙虽然有软件或硬件之分,但主要功能都是依据策略对穿越防火墙自身的流量进行过滤。就像家里安装的防盗门一样,目的是保护亲人和财产安全。防火墙策略可以基于流量的源目地址、端口号、协议、应用等信息来定制,然后防火墙使用预先定制的策略规则监控出入的流量,若流量与某一条策略规则相匹配,则执行相应的处理,反之则丢弃。这样一来,就能够保证仅有合法的流量在企业内网和外部公网之间流动了。
从RHEL 7系统开始,firewalld防火墙正式取代了iptables防火墙。对于接触Linux系统比较早或学习过RHEL 5/6系统的读者来说,当他们发现曾经掌握的知识在RHEL 7/8中不再适用,需要全新学习firewalld时,难免会有抵触心理。其实,iptables与firewalld都不是真正的防火墙,它们都只是用来定义防火墙策略的防火墙管理工具而已;或者说,它们只是一种服务。iptables服务会把配置好的防火墙策略交由内核层面的netfilter网络过滤器来处理,而firewalld服务则是把配置好的防火墙策略交由内核层面的nftables包过滤框架来处理。换句话说,当前在Linux系统中其实存在多个防火墙管理工具,旨在方便运维人员管理Linux系统中的防火墙策略,我们只需要配置妥当其中的一个就足够了。
虽然这些工具各有优劣,但它们在防火墙策略的配置思路上是保持一致的。大家甚至可以不用完全掌握本章介绍的内容,只要在这多个防火墙管理工具中任选一款并将其学透,就足以满足日常的工作需求了。
Iptables
在早期的Linux系统中,默认使用的是iptables防火墙管理服务来配置防火墙。尽管新型的firewalld防火墙管理服务已经被投入使用多年,但是大量的企业在生产环境中依然出于各种原因而继续使用iptables。
策略与规则链
防火墙会按照从上到下的顺序来读取配置的策略规则,在找到匹配项后就立即结束匹配工作并去执行匹配项中定义的行为(即放行或阻止)。如果在读取完所有的策略规则之后没有匹配项,就去执行默认的策略。一般而言,防火墙策略规则的设置有两种:“通”(即放行)和“堵”(即阻止)。当防火墙的默认策略为拒绝时(堵),就要设置允许规则(通),否则谁都进不来;如果防火墙的默认策略为允许,就要设置拒绝规则,否则谁都能进来,防火墙也就失去了防范的作用。
iptables服务把用于处理或过滤流量的策略条目称之为规则,多条规则可以组成一个规则链,而规则链则依据数据包处理位置的不同进行分类,具体如下:
- 在进行路由选择前处理数据包(PREROUTING);
- 处理流入的数据包(INPUT);
- 处理流出的数据包(OUTPUT);
- 处理转发的数据包(FORWARD);
- 在进行路由选择后处理数据包(POSTROUTING)。
一般来说,从内网向外网发送的流量一般都是可控且良性的,因此使用最多的就是INPUT规则链,该规则链可以增大黑客人员从外网入侵内网的难度。
比如在您居住的社区内,物业管理公司有两条规定:禁止小商小贩进入社区;各种车辆在进入社区时都要登记。显而易见,这两条规定应该是用于社区的正门的(流量必须经过的地方),而不是每家每户的防盗门上。根据前面提到的防火墙策略的匹配顺序,可能会存在多种情况。比如,来访人员是小商小贩,则直接会被物业公司的保安拒之门外,也就无须再对车辆进行登记。如果来访人员乘坐一辆汽车进入社区正门,则“禁止小商小贩进入社区”的第一条规则就没有被匹配到,因此按照顺序匹配第二条策略,即需要对车辆进行登记。如果是社区居民要进入正门,则这两条规定都不会匹配到,因此会执行默认的放行策略。
但是,仅有策略规则还不能保证社区的安全,保安还应该知道采用什么样的动作来处理这些匹配的流量,比如“允许”“拒绝”“登记”“不理它”。这些动作对应到iptables服务的术语中分别是ACCEPT(允许流量通过)、REJECT(拒绝流量通过)、LOG(记录日志信息)、DROP(拒绝流量通过)。“允许流量通过”和“记录日志信息”都比较好理解,这里需要着重讲解的是REJECT和DROP的不同点。就DROP来说,它是直接将流量丢弃而且不响应;REJECT则会在拒绝流量后再回复一条“信息已经收到,但是被扔掉了”信息,从而让流量发送方清晰地看到数据被拒绝的响应信息。
下面举一个例子,让各位读者更直观地理解这两个拒绝动作的不同之处。比如有一天您正在家里看电视,突然听到有人敲门,您透过防盗门的猫眼一看是推销商品的,便会在不需要的情况下开门并拒绝他们(REJECT)。但如果看到的是债主带了十几个小弟来讨债,此时不仅要拒绝开门,还要默不作声,伪装成自己不在家的样子(DROP)。
当把Linux系统中的防火墙策略设置为REJECT动作后,流量发送方会看到端口不可达的响应:
[root@linuxprobe ~]# ping -c 4 192.168.10.10
PING 192.168.10.10 (192.168.10.10) 56(84) bytes of data.
From 192.168.10.10 icmp_seq=1 Destination Port Unreachable
From 192.168.10.10 icmp_seq=2 Destination Port Unreachable
From 192.168.10.10 icmp_seq=3 Destination Port Unreachable
From 192.168.10.10 icmp_seq=4 Destination Port Unreachable
--- 192.168.10.10 ping statistics ---
4 packets transmitted, 0 received, +4 errors, 100 packet loss, time 3002ms
而把Linux系统中的防火墙策略修改成DROP动作后,流量发送方会看到响应超时的提醒。但是流量发送方无法判断流量是被拒绝,还是接收方主机当前不在线:
[root@linuxprobe ~]# ping -c 4 192.168.10.10
PING 192.168.10.10 (192.168.10.10) 56(84) bytes of data.
--- 192.168.10.10 ping statistics ---
4 packets transmitted, 0 received, 100 packet loss, time 3000ms
基本的命令参数
iptables是一款基于命令行的防火墙策略管理工具,具有大量的参数,学习难度较大。好在对于日常的防火墙策略配置来讲,大家无须深入了解诸如“四表五链”的理论概念,只需要掌握常用的参数并做到灵活搭配即可,这就足以应对日常工作了。
根据OSI七层模型的定义,iptables属于数据链路层的服务,所以可以根据流量的源地址、目的地址、传输协议、服务类型等信息进行匹配;一旦匹配成功,iptables就会根据策略规则所预设的动作来处理这些流量。另外,再次提醒一下,防火墙策略规则的匹配顺序是从上到下的,因此要把较为严格、优先级较高的策略规则放到前面,以免发生错误。表8-1总结归纳了常用的iptables命令参数。再次强调,无须死记硬背这些参数,只需借助下面的实验来理解掌握即可。
命令格式
iptables [-t table] COMMAND chain CRETIRIA -j ACTION
- -t table :filter/nat/mangle
- COMMAND:定义如何对规则进行管理
- chain:指定你接下来的规则到底是在哪个链上操作的,当定义策略的时候,是可以省略的
- CRETIRIA:指定匹配标准
- -j ACTION :指定如何进行处理
参数说明
| 参数 | 说明 | 示例 |
|---|---|---|
| -t | 对指定的表操作(raw、mangle、nat、filter),默认 filter 表 | iptables -t nat |
| -j | 要进行的处理动作:DROP(丢弃),REJECT(拒绝),ACCEPT(接受),SANT(基于原地址的转换) | iptable -A INPUT 1 -s 192.168.120.0 -j DROP |
通用匹配
| 参数 | 说明 | 示例 |
|---|---|---|
| -p | 协议(tcp/udp/icmp) | iptables -A INPUT -p tcp |
| -s | 匹配原地址,加" ! “表示除这个IP外,192.168.1.0/255.255.255.0 示一组范围内的地址 | iptables -A INPUT -s 192.168.1.1 |
| -d | 匹配目的地址 ,地址格式同 -s | iptables -A INPUT -d 192.168.12.1 |
| -i | 匹配入口网卡流入的数据,无此项表示可以来自任何一个网络接口 | iptables -A INPUT -i eth0 |
| -o | 匹配出口网卡流出的数据 | iptables -A FORWARD -o eth0 |
查看管理命令
| 参数 | 说明 | 示例 |
|---|---|---|
| -L | 列出指定链上面的所有规则,如果没有指定链,列出表上所有链的所有规则 | iptables -L |
规则管理命令
| 参数 | 说明 | 示例 |
|---|---|---|
| -A | 在指定链的末尾插入指定的规则 | iptables -A INPUT |
| -I | 在链中的指定位置插入规则。默认规则号是1,在链的头部插入规则 | iptables -I INPUT 1 –dport 80 -j ACCEPT |
| -D | 在指定的链中删除指定规则号的规则。 | iptables -D INPUT 1 |
| -R | 修改指定规则号的规则 | iptable -R INPUT 1 -s 192.168.120.0 -j DROP |
链管理命令
| 参数 | 说明 | 示例 |
|---|---|---|
| -F | 清空规则链 | iptables -F |
| -N | 新的规则 | iptables -N allowed |
其他
| 参数 | 说明 | 示例 |
|---|---|---|
| –sport | 匹配源端口流入的数据 | iptables -A INPUT -p tcp –sport 22 |
| –dport | 匹配目的端口流出的数据 | iptables -A INPUT -p tcp –dport 22 |
| –to-source | 指定SANT转换后的地址 | iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j SANT –to-source 172.16.100.1 |
| -m | 使用扩展模块来进行数据包的匹配(multiport/tcp/state/addrtype) | iptables -m multiport |
动作说明
处理动作除了 ACCEPT、REJECT、DROP、REDIRECT 和 MASQUERADE 以外,还多出 LOG、ULOG、DNAT、SNAT、MIRROR、QUEUE、RETURN、TOS、TTL、MARK 等,其中某些处理动作不会中断过滤程序,某些处理动作则会中断同一规则链的过滤,并依照前述流程继续进行下一个规则链的过滤,一直到堆栈中的规则检查完毕为止。透过这种机制所带来的好处是,我们可以进行复杂、多重的封包过滤,简单的说,iptables 可以进行纵横交错式的过滤(tables)而非链状过滤(chains)。
| 动作 | 说明 | 示例 |
|---|---|---|
| ACCEPT | 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链(nat:postrouting) | |
| REJECT | 拦阻该封包,并传送封包通知对方,可以传送的封包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是 tcp-reset(这个封包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接 中断过滤程序。 | iptables -A FORWARD -p TCP –dport 22 -j REJECT –reject-with tcp-reset |
| DROP | 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。 | |
| REDIRECT | 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将 会继续比对其它规则。 这个功能可以用来实作通透式 porxy 或用来保护 web 服务器。 | iptables -t nat -A PREROUTING -p tcp –dport 80 -j REDIRECT –to-ports 8080 |
| MASQUERADE | 改写封包来源 IP 为防火墙 NIC IP,可以指定 port 对应的范围,进行完此处理动作后,直接跳往下一个规则链(mangle:postrouting)。这个功能与 SNAT 略有不同,当进行 IP 伪装时,不需指定要伪装成哪个 IP,IP 会从网卡直接读取,当使用拨接连线时,IP 通常是由 ISP 公司的 DHCP 服务器指派的,这个时候 MASQUERADE 特别有用。 | iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE –to-ports 1024-31000 |
| LOG | 将封包相关讯息纪录在 /var/log 中,详细位置请查阅 /etc/syslog.conf 组态档,进行完此处理动作后,将会继续比对其它规则。 | iptables -A INPUT -p tcp -j LOG –log-prefix “INPUT packets” |
| SNAT | 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则链(mangle:postrouting)。 | iptables -t nat -A POSTROUTING -p tcp-o eth0 -j SNAT –to-source 194.236.50.155-194.236.50.160:1024-32000 |
| DNAT | 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规则链(filter:input 或 filter:forward)。 | iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 –dport 80 -j DNAT –to-destination 192.168.1.1-192.168.1.10:80-100 |
| MIRROR | 镜射封包,也就是将来源 IP 与目的地 IP 对调后,将封包送回,进行完此处理动作后,将会中断过滤程序。 | |
| QUEUE | 中断过滤程序,将封包放入队列,交给其它程序处理。透过自行开发的处理程序,可以进行其它应用,例如:计算联机费用……等。 | |
| RETURN | 结束在目前规则链中的过滤程序,返回主规则链继续过滤,如果把自订规则链看成是一个子程序,那么这个动作,就相当于提早结束子程序并返回到主程序中。 | |
| MARK | 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。 | iptables -t mangle -A PREROUTING -p tcp –dport 22 -j MARK –set-mark 2 |
例子
1.在iptables命令后添加-L参数查看已有的防火墙规则链。
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT udp -- anywhere anywhere udp dpt:domain
ACCEPT tcp -- anywhere anywhere tcp dpt:domain
ACCEPT udp -- anywhere anywhere udp dpt:bootps
ACCEPT tcp -- anywhere anywhere tcp dpt:bootps
Chain FORWARD (policy ACCEPT)
target prot opt source destination
ACCEPT all -- anywhere 192.168.122.0/24 ctstate RELATED,ESTABLISHED
ACCEPT all -- 192.168.122.0/24 anywhere
ACCEPT all -- anywhere anywhere
REJECT all -- anywhere anywhere reject-with icmp-port-unreachable
REJECT all -- anywhere anywhere reject-with icmp-port-unreachable
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
ACCEPT udp -- anywhere anywhere udp dpt:bootpc
2.在iptables命令后添加-F参数清空已有的防火墙规则链。
[root@linuxprobe ~]# iptables -F
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
3.把INPUT规则链的默认策略设置为拒绝。
[root@linuxprobe ~]# iptables -P INPUT DROP
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
前文提到,防火墙策略规则的设置无非有两种方式:“通”和“堵”。当把INPUT链设置为默认拒绝后,就要往里面写入允许策略了,否则所有流入的数据包都会被默认拒绝掉。同学们需要留意的是,规则链的默认策略拒绝动作只能是DROP,而不能是REJECT。
4.向INPUT链中添加允许ICMP流量进入的策略规则。
在日常运维工作中,经常会使用ping命令来检查对方主机是否在线,而向防火墙的INPUT规则链中添加一条允许ICMP流量进入的策略规则就默认允许了这种ping命令检测行为。
[root@linuxprobe ~]# iptables -I INPUT -p icmp -j ACCEPT
[root@linuxprobe ~]# ping -c 4 192.168.10.10
PING 192.168.10.10 (192.168.10.10) 56(84) bytes of data.
64 bytes from 192.168.10.10: icmp_seq=1 ttl=64 time=0.154 ms
64 bytes from 192.168.10.10: icmp_seq=2 ttl=64 time=0.041 ms
64 bytes from 192.168.10.10: icmp_seq=3 ttl=64 time=0.038 ms
64 bytes from 192.168.10.10: icmp_seq=4 ttl=64 time=0.046 ms
--- 192.168.10.10 ping statistics ---
4 packets transmitted, 4 received, 0 packet loss, time 104ms
rtt min/avg/max/mdev = 0.038/0.069/0.154/0.049 ms
5.删除INPUT规则链中刚刚加入的那条策略(允许ICMP流量),并把默认策略设置为允许。
使用-F参数会清空已有的所有防火墙策略;使用-D参数可以删除某一条指定的策略,因此更加安全和准确。
[root@linuxprobe ~]# iptables -D INPUT 1
[root@linuxprobe ~]# iptables -P INPUT ACCEPT
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
6.将INPUT规则链设置为只允许指定网段的主机访问本机的22端口,拒绝来自其他所有主机的流量。
要对某台主机进行匹配,可直接写出它的IP地址;如需对网段进行匹配,则需要写为子网掩码的形式(比如192.168.10.0/24)。
[root@linuxprobe ~]# iptables -I INPUT -s 192.168.10.0/24 -p tcp --dport 22 -j ACCEPT
[root@linuxprobe ~]# iptables -A INPUT -p tcp --dport 22 -j REJECT
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT tcp -- 192.168.10.0/24 anywhere tcp dpt:ssh
REJECT tcp -- anywhere anywhere tcp dpt:ssh reject-with icmp-port-unreachable
………………省略部分输出信息………………
再次重申,防火墙策略规则是按照从上到下的顺序匹配的,因此一定要把允许动作放到拒绝动作前面,否则所有的流量就将被拒绝掉,从而导致任何主机都无法访问我们的服务。另外,这里提到的22号端口是ssh服务使用的。
在设置完上述INPUT规则链之后,使用IP地址在192.168.10.0/24网段内的主机访问服务器(即前面提到的设置了INPUT规则链的主机)的22端口,效果如下:
[root@Client A ~]# ssh 192.168.10.10
The authenticity of host '192.168.10.10 (192.168.10.10)' can't be established.
ECDSA key fingerprint is SHA256:5d52kZi1la/FJK4v4jibLBZhLqzGqbJAskZiME6ZXpQ.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.10.10' (ECDSA) to the list of known hosts.
root@192.168.10.10's password: 此处输入服务器密码
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Wed Jan 20 16:30:28 2021 from 192.168.10.1
然后,再使用IP地址在192.168.20.0/24网段内的主机访问服务器的22端口(虽网段不同,但已确认可以相互通信),效果如下:
[root@Client B ~]# ssh 192.168.10.10
Connecting to 192.168.10.10:22...
Could not connect to '192.168.10.10' (port 22): Connection failed.
由上可以看到,提示连接请求被拒绝了(Connection failed)。
7.向INPUT规则链中添加拒绝所有人访问本机12345端口的策略规则。
[root@linuxprobe ~]# iptables -I INPUT -p tcp --dport 12345 -j REJECT
[root@linuxprobe ~]# iptables -I INPUT -p udp --dport 12345 -j REJECT
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
REJECT udp -- anywhere anywhere udp dpt:italk reject-with icmp-port-unreachable
REJECT tcp -- anywhere anywhere tcp dpt:italk reject-with icmp-port-unreachable
ACCEPT tcp -- 192.168.10.0/24 anywhere tcp dpt:ssh
REJECT tcp -- anywhere anywhere tcp dpt:ssh reject-with icmp-port-unreachable
………………省略部分输出信息………………
8.向INPUT规则链中添加拒绝192.168.10.5主机访问本机80端口(Web服务)的策略规则。
[root@linuxprobe ~]# iptables -I INPUT -p tcp -s 192.168.10.5 --dport 80 -j REJECT
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
REJECT tcp -- 192.168.10.5 anywhere tcp dpt:http reject-with icmp-port-unreachable
REJECT udp -- anywhere anywhere udp dpt:italk reject-with icmp-port-unreachable
REJECT tcp -- anywhere anywhere tcp dpt:italk reject-with icmp-port-unreachable
ACCEPT tcp -- 192.168.10.0/24 anywhere tcp dpt:ssh
REJECT tcp -- anywhere anywhere tcp dpt:ssh reject-with icmp-port-unreachable
………………省略部分输出信息………………
9.向INPUT规则链中添加拒绝所有主机访问本机1000~1024端口的策略规则。
前面在添加防火墙策略时,使用的是-I参数,它默认会把规则添加到最上面的位置,因此优先级是最高的。如果工作中需要添加一条最后“兜底”的规则,那就用-A参数吧。这两个参数的效果差别还是很大的:
[root@linuxprobe ~]# iptables -A INPUT -p tcp --dport 1000:1024 -j REJECT
[root@linuxprobe ~]# iptables -A INPUT -p udp --dport 1000:1024 -j REJECT
[root@linuxprobe ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
REJECT tcp -- 192.168.10.5 anywhere tcp dpt:http reject-with icmp-port-unreachable
REJECT udp -- anywhere anywhere udp dpt:italk reject-with icmp-port-unreachable
REJECT tcp -- anywhere anywhere tcp dpt:italk reject-with icmp-port-unreachable
ACCEPT tcp -- 192.168.10.0/24 anywhere tcp dpt:ssh
REJECT tcp -- anywhere anywhere tcp dpt:ssh reject-with icmp-port-unreachable
REJECT tcp -- anywhere anywhere tcp dpts:cadlock2:1024 reject-with icmp-port-unreachable
REJECT udp -- anywhere anywhere udp dpts:cadlock2:1024 reject-with icmp-port-unreachable
………………省略部分输出信息………………
有关iptables命令的知识讲解到此就结束了,大家是不是意犹未尽?考虑到Linux防火墙的发展趋势,大家只要能把上面的实例吸收消化,就可以完全搞定日常的iptables配置工作了。但是请特别注意,使用iptables命令配置的防火墙规则默认会在系统下一次重启时失效,如果想让配置的防火墙策略永久生效,还要执行保存命令:
[root@linuxprobe ~]# iptables-save
# Generated by xtables-save v1.8.2 on Wed Jan 20 16:56:27 2021
………………省略部分输出信息………………
对了,如果公司服务器是5/6/7版本的话,对应的保存命令应该是:
[root@linuxprobe ~]# service iptables save
iptables: Saving firewall rules to /etc/sysconfig/iptables: [ OK ]
基本概念
iptables 是一个配置 Linux 内核 防火墙 的命令行工具,是 Netfilter 项目的一部分。术语 iptables 也经常代指该内核级防火墙。iptables 可以直接配置,也可以通过许多 控制台 和 图形化 前端配置。iptables 用于 ipv4,ip6tables 用于 IPv6。iptables和ip6tables 拥有相同的语法,但是有些特别的选项,对 IPv4 和 IPv6 有些不同的。
iptables 可以检测、修改、转发、重定向和丢弃 IPv4 数据包。过滤 IPv4 数据包的代码已经内置于内核中,并且按照不同的目的被组织成 表 的集合。表 由一组预先定义的 链 组成,链 包含遍历顺序规则(即结构是:iptables -> Tables -> Chains -> Rules)。每一条规则包含一个谓词的潜在匹配和相应的动作(称为 目标),如果谓词为真,该动作会被执行。也就是说条件匹配。iptables 是用户工具,允许用户使用 链 和 规则。很多新手面对复杂的 linux IP 路由时总是感到气馁,但是,实际上最常用的一些应用案例(NAT 或者基本的网络防火墙)并不是很复杂。
理解 iptables 如何工作的关键是上面这张图(Netfilter模型)。图中在上面的小写字母代表 表,在下面的大写字母代表 链。从任何网络端口 进来的每一个 IP 数据包都要从上到下的穿过这张图。一种常见的错误认知是认为 iptables 对从内部端口进入的数据包和从面向互联网端口进入的数据包采取不同的处理方式,相反,iptabales 对从任何端口进入的数据包都会采取相同的处理方式。可以定义规则使 iptables 采取不同的方式对待从不同端口进入的数据包。当然一些数据包是用于本地进程的,因此在图中表现为从顶端进入,到 <Local Process> 停止,而另一些数据包是由本地进程生成的,因此在图中表现为从 <Local Process> 发出,一直向下穿过该流程图。一份关于该流程图如何工作的详细解释请参考Iptables Tutorial。
一个解释原理的例子:假设使用路由器作为网关(即我们平时的上网方式,即<Local Process> 是路由器)
那么:
- 局域网设备通过路由器访问互联网的流量方向:
PREROUTING链->FORWARD链->POSTINGROUTING链 - 局域网设备访问路由器的流量(如登陆路由器 web 管理界面/ssh 连接路由器/访问路由器的 dns 服务器等)方向:
PREROUTING链->INPUT链->网关本机 - 路由器访问互联网的流量方向:
网关本机->OUTPUT链->POSTINGROUTING链
表(Tables)
ptables 包含 5 张表(tables):
raw用于配置数据包,raw中的数据包不会被系统跟踪。filter是用于存放所有与防火墙相关操作的默认表。nat用于 网络地址转换(例如:端口转发)。mangle用于对特定数据包的修改(参考 损坏数据包)。security用于 强制访问控制 网络规则(例如: SELinux – 详细信息参考 该文章)。
大部分情况仅需要使用 filter 和 nat。其他表用于更复杂的情况——包括多路由和路由判定——已经超出了本文介绍的范围。
链(Chains)
表由链组成,链是一些按顺序排列的规则的列表。默认的 filter 表包含 INPUT, OUTPUT 和 FORWARD 3条内建的链,这3条链作用于数据包过滤过程中的不同时间点,如该上面流程图所示。nat 表包含PREROUTING, POSTROUTING 和 OUTPUT 链。
使用 iptables(8) 查看其他表中内建链的描述。
默认情况下,任何链中都没有规则。可以向链中添加自己想用的规则。链的默认规则通常设置为 ACCEPT,如果想确保任何包都不能通过规则集,那么可以重置为 DROP。默认的规则总是在一条链的最后生效,所以在默认规则生效前数据包需要通过所有存在的规则。
用户可以加入自己定义的链,从而使规则集更有效并且易于修改。如何使用自定义链请参考 Simple stateful firewall。
规则 (Rules)
数据包的过滤基于 规则。规则由一个目标(数据包包匹配所有条件后的动作)和很多匹配(导致该规则可以应用的数据包所满足的条件)指定。一个规则的典型匹配事项是数据包进入的端口(例如:eth0 或者 eth1)、数据包的类型(ICMP, TCP, 或者 UDP)和数据包的目的端口。
目标使用 -j 或者 --jump 选项指定。目标可以是用户定义的链(例如,如果条件匹配,跳转到之后的用户定义的链,继续处理)、一个内置的特定目标或者是一个目标扩展。内置目标是 ACCEPT, DROP, QUEUE 和 RETURN,目标扩展是 REJECT 和 LOG。如果目标是内置目标,数据包的命运会立刻被决定并且在当前表的数据包的处理过程会停止。如果目标是用户定义的链,并且数据包成功穿过第二条链,目标将移动到原始链中的下一个规则。目标扩展可以被终止(像内置目标一样)或者不终止(像用户定义链一样)。详细信息参阅 iptables-extensions(8)。
遍历链(Traversing Chains)
该流程图描述链了在任何接口上收到的网络数据包是按照怎样的顺序穿过表的交通管制链。第一个路由策略包括决定数据包的目的地是本地主机(这种情况下,数据包穿过 INPUT 链),还是其他主机(数据包穿过 FORWARD 链);中间的路由策略包括决定给传出的数据包使用那个源地址、分配哪个接口;最后一个路由策略存在是因为先前的 mangle 与 nat 链可能会改变数据包的路由信息。数据包通过路径上的每一条链时,链中的每一条规则按顺序匹配;无论何时匹配了一条规则,相应的 target/jump 动作将会执行。最常用的3个 target 是 ACCEPT, DROP ,或者 jump 到用户自定义的链。内置的链有默认的策略,但是用户自定义的链没有默认的策略。在 jump 到的链中,若每一条规则都不能提供完全匹配,那么数据包像下面这张图片描述的一样返回到调用链。在任何时候,若 DROP target 的规则实现完全匹配,那么被匹配的数据包会被丢弃,不会进行进一步处理。如果一个数据包在链中被 ACCEPT,那么它也会被所有的父链 ACCEPT,并且不再遍历其他父链。然而,要注意的是,数据包还会以正常的方式继续遍历其他表中的其他链。
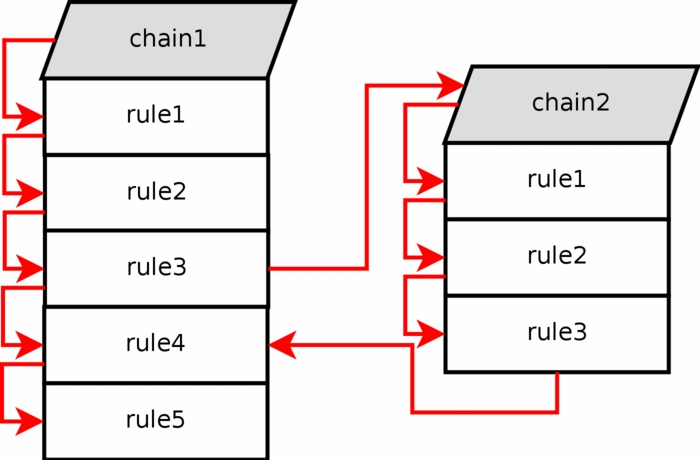
模块(Modules)
有许多模块可以用来扩展 iptables,例如 connlimit, conntrack, limit 和 recent。这些模块增添了功能,可以进行更复杂的过滤。
Firewalld
RHEL 8系统中集成了多款防火墙管理工具,其中firewalld(Dynamic Firewall Manager of Linux systems,Linux系统的动态防火墙管理器)服务是默认的防火墙配置管理工具,它拥有基于CLI(命令行界面)和基于GUI(图形用户界面)的两种管理方式。
相较于传统的防火墙管理配置工具,firewalld支持动态更新技术并加入了区域(zone)的概念。简单来说,区域就是firewalld预先准备了几套防火墙策略集合(策略模板),用户可以根据生产场景的不同而选择合适的策略集合,从而实现防火墙策略之间的快速切换。例如,我们有一台笔记本电脑,每天都要在办公室、咖啡厅和家里使用。按常理来讲,这三者的安全性按照由高到低的顺序来排列,应该是家庭、公司办公室、咖啡厅。当前,我们希望为这台笔记本电脑制定如下防火墙策略规则:在家中允许访问所有服务;在办公室内仅允许访问文件共享服务;在咖啡厅仅允许上网浏览。在以往,我们需要频繁地手动设置防火墙策略规则,而现在只需要预设好区域集合,然后轻点鼠标就可以自动切换了,从而极大地提升了防火墙策略的应用效率。firewalld中常见的区域名称(默认为public)以及相应的策略规则如表所示。
| 区域 | 默认规则策略 |
|---|---|
| trusted | 允许所有的数据包 |
| home | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、mdns、ipp-client、amba-client与dhcpv6-client服务相关,则允许流量 |
| internal | 等同于home区域 |
| work | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、ipp-client与dhcpv6-client服务相关,则允许流量 |
| public | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、dhcpv6-client服务相关,则允许流量 |
| external | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量 |
| dmz | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量 |
| block | 拒绝流入的流量,除非与流出的流量相关 |
| drop | 拒绝流入的流量,除非与流出的流量相关 |
终端管理工具
命令行终端是一种极富效率的工作方式,firewall-cmd是firewalld防火墙配置管理工具的CLI(命令行界面)版本。它的参数一般都是以“长格式”来提供的。大家不要一听到长格式就头大,因为RHEL 8系统支持部分命令的参数补齐,其中就包含这条命令(很酷吧)。也就是说,现在除了能用Tab键自动补齐命令或文件名等内容之外,还可以用Tab键来补齐表所示的长格式参数。这太棒了!
| 参数 | 作用 |
|---|---|
| –get-default-zone | 查询默认的区域名称 |
| –set-default-zone=<区域名称> | 设置默认的区域,使其永久生效 |
| –get-zones | 显示可用的区域 |
| –get-services | 显示预先定义的服务 |
| –get-active-zones | 显示当前正在使用的区域与网卡名称 |
| –add-source= | 将源自此IP或子网的流量导向指定的区域 |
| –remove-source= | 不再将源自此IP或子网的流量导向某个指定区域 |
| –add-interface=<网卡名称> | 将源自该网卡的所有流量都导向某个指定区域 |
| –change-interface=<网卡名称> | 将某个网卡与区域进行关联 |
| –list-all | 显示当前区域的网卡配置参数、资源、端口以及服务等信息 |
| –list-all-zones | 显示所有区域的网卡配置参数、资源、端口以及服务等信息 |
| –add-service=<服务名> | 设置默认区域允许该服务的流量 |
| –add-port=<端口号/协议> | 设置默认区域允许该端口的流量 |
| –remove-service=<服务名> | 设置默认区域不再允许该服务的流量 |
| –remove-port=<端口号/协议> | 设置默认区域不再允许该端口的流量 |
| –reload | 让“永久生效”的配置规则立即生效,并覆盖当前的配置规则 |
| –panic-on | 开启应急状况模式 |
| –panic-off | 关闭应急状况模式 |
与Linux系统中其他的防火墙策略配置工具一样,使用firewalld配置的防火墙策略默认为运行时(Runtime)模式,又称为当前生效模式,而且会随着系统的重启而失效。如果想让配置策略一直存在,就需要使用永久(Permanent)模式了,方法就是在用firewall-cmd命令正常设置防火墙策略时添加–permanent参数,这样配置的防火墙策略就可以永久生效了。但是,永久生效模式有一个“不近人情”的特点,就是使用它设置的策略只有在系统重启之后才能自动生效。如果想让配置的策略立即生效,需要手动执行firewall-cmd –reload命令。
接下来的实验都很简单,但是提醒大家一定要仔细查看使用的是Runtime模式还是Permanent模式。如果不关注这个细节,就算正确配置了防火墙策略,也可能无法达到预期的效果。
1.查看firewalld服务当前所使用的区域。
这是一步非常重要的操作。在配置防火墙策略前,必须查看当前生效的是哪个区域,否则配置的防火墙策略将不会立即生效。
[root@linuxprobe ~]# firewall-cmd --get-default-zone
public
2.查询指定网卡在firewalld服务中绑定的区域。
在生产环境中,服务器大多不止有一块网卡。一般来说,充当网关的服务器有两块网卡,一块对公网,另外一块对内网,那么这两块网卡在审查流量时所用的策略肯定也是不一致的。因此,可以根据网卡针对的流量来源,为网卡绑定不同的区域,实现对防火墙策略的灵活管控。
[root@linuxprobe ~]# firewall-cmd --get-zone-of-interface=ens160
public
3.把网卡默认区域修改为external,并在系统重启后生效。
[root@linuxprobe ~]# firewall-cmd --permanent --zone=external --change-interface=ens160
The interface is under control of NetworkManager, setting zone to 'external'.
success
[root@linuxprobe ~]# firewall-cmd --permanent --get-zone-of-interface=ens160
external
4.把firewalld服务的默认区域设置为public。
默认区域也叫全局配置,指的是对所有网卡都生效的配置,优先级较低。在下面的代码中可以看到,当前默认区域为public,而ens160网卡的区域为external。此时便是以网卡的区域名称为准。
通俗来说,默认区域就是一种通用的政策。例如,食堂为所有人准备了一次性餐具,而环保主义者则会自己携带碗筷。如果您自带了碗筷,就可以用自己的;反之就用食堂统一提供的。
[root@linuxprobe ~]# firewall-cmd --set-default-zone=public
Warning: ZONE_ALREADY_SET: public
success
[root@linuxprobe ~]# firewall-cmd --get-default-zone
public
[root@linuxprobe ~]# firewall-cmd --get-zone-of-interface=ens160
external
5.启动和关闭firewalld防火墙服务的应急状况模式。
如果想在1s的时间内阻断一切网络连接,有什么好办法呢?大家下意识地会说:“拔掉网线!”这是一个物理级别的高招。但是,如果人在北京,服务器在异地呢?panic紧急模式在这个时候就派上用场了。使用–panic-on参数会立即切断一切网络连接,而使用–panic-off则会恢复网络连接。切记,紧急模式会切断一切网络连接,因此在远程管理服务器时,在按下回车键前一定要三思。
[root@linuxprobe ~]# firewall-cmd --panic-on
success
[root@linuxprobe ~]# firewall-cmd --panic-off
success
6.查询SSH和HTTPS协议的流量是否允许放行。
在工作中可以不使用–zone参数指定区域名称,firewall-cmd命令会自动依据默认区域进行查询,从而减少用户输入量。但是,如果默认区域与网卡所绑定的不一致时,就会发生冲突,因此规范写法的zone参数是一定要加的。
[root@linuxprobe ~]# firewall-cmd --zone=public --query-service=ssh
yes
[root@linuxprobe ~]# firewall-cmd --zone=public --query-service=https
no
7.把HTTPS协议的流量设置为永久允许放行,并立即生效。
默认情况下进行的修改都属于Runtime模式,即当前生效而重启后失效,因此在工作和考试中尽量避免使用。而在使用–permanent参数时,则是当前不会立即看到效果,而在重启或重新加载后方可生效。于是,在添加了允许放行HTTPS流量的策略后,查询当前模式策略,发现依然是不允许放行HTTPS协议的流量:
[root@linuxprobe ~]# firewall-cmd --permanent --zone=public --add-service=https
success
[root@linuxprobe ~]# firewall-cmd --zone=public --query-service=https
no
不想重启服务器的话,就用–reload参数吧:
[root@linuxprobe ~]# firewall-cmd --reload
success
[root@linuxprobe ~]# firewall-cmd --zone=public --query-service=https
yes
8.把HTTP协议的流量设置为永久拒绝,并立即生效。
由于在默认情况下HTTP协议的流量就没有被允许,所以会有“Warning: NOT_ENABLED: http”这样的提示信息,因此对实际操作没有影响。
[root@linuxprobe ~]# firewall-cmd --permanent --zone=public --remove-service=http
Warning: NOT_ENABLED: http
success
[root@linuxprobe ~]# firewall-cmd --reload
success
9.把访问8080和8081端口的流量策略设置为允许,但仅限当前生效。
[root@linuxprobe ~]# firewall-cmd --zone=public --add-port=8080-8081/tcp
success
[root@linuxprobe ~]# firewall-cmd --zone=public --list-ports
8080-8081/tcp
10.把原本访问本机888端口的流量转发到22端口,要且求当前和长期均有效。
SSH远程控制协议是基于TCP/22端口传输控制指令的,如果想让用户通过其他端口号也能访问ssh服务,就可以试试端口转发技术了。通过这项技术,新的端口号在收到用户请求后会自动转发到原本服务的端口上,使得用户能够通过新的端口访问到原本的服务。
来举个例子帮助大家理解。假设小强是电子厂的工人,他喜欢上了三号流水线上的工人小花,但不好意思表白,于是写了一封情书并交给门卫张大爷,希望由张大爷转交给小花。这样一来,情书(信息)的传输由从小强到小花,变成了小强到张大爷再到小花,情书(信息)依然能顺利送达。
使用firewall-cmd命令实现端口转发的格式有点长,这里为大家总结好了:
firewall-cmd --permanent --zone=<区域> --add-forward-port=port=<源端口号>:proto=<协议>:toport=<目标端口号>:toaddr=<目标IP地址>
上述命令中的目标IP地址一般是服务器本机的IP地址:
[root@linuxprobe ~]# firewall-cmd --permanent --zone=public --add-forward-port=port=888:proto=tcp:toport=22:toaddr=192.168.10.10
success
[root@linuxprobe ~]# firewall-cmd --reload
success
在客户端使用ssh命令尝试访问192.168.10.10主机的888端口,访问成功:
[root@client A ~]# ssh -p 888 192.168.10.10
The authenticity of host '[192.168.10.10]:888 ([192.168.10.10]:888)' can't be established.
ECDSA key fingerprint is b8:25:88:89:5c:05:b6:dd:ef:76:63:ff:1a:54:02:1a.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '[192.168.10.10]:888' (ECDSA) to the list of known hosts.
root@192.168.10.10's password:此处输入远程root管理员的密码
Last login: Sun Jul 19 21:43:48 2021 from 192.168.10.10
11.富规则的设置。
富规则也叫复规则,表示更细致、更详细的防火墙策略配置,它可以针对系统服务、端口号、源地址和目标地址等诸多信息进行更有针对性的策略配置。它的优先级在所有的防火墙策略中也是最高的。比如,我们可以在firewalld服务中配置一条富规则,使其拒绝192.168.10.0/24网段的所有用户访问本机的ssh服务(22端口):
[root@linuxprobe ~]# firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv4" source address="192.168.10.0/24" service name="ssh" reject"
success
[root@linuxprobe ~]# firewall-cmd --reload
success
在客户端使用ssh命令尝试访问192.168.10.10主机的ssh服务(22端口):
[root@client A ~]# ssh 192.168.10.10
Connecting to 192.168.10.10:22...
Could not connect to '192.168.10.10' (port 22): Connection failed.
图形管理工具
在各种版本的Linux系统中,几乎没有能让刘遄老师欣慰并推荐的图形化工具,但是firewall-config做到了。它是firewalld防火墙配置管理工具的GUI(图形用户界面)版本,几乎可以实现所有以命令行来执行的操作。毫不夸张地说,即使读者没有扎实的Linux命令基础,也完全可以通过它来妥善配置RHEL 8中的防火墙策略。
成功安装firewall-config后,其工具的界面如图所示:
其功能具体如下。
1:选择运行时(Runtime)或永久(Permanent)模式的配置。
2:可选的策略集合区域列表。
3:常用的系统服务列表。
4:主机地址的黑白名单。
5:当前正在使用的区域。
6:管理当前被选中区域中的服务。
7:管理当前被选中区域中的端口。
8:设置允许被访问的协议。
9:设置允许被访问的端口。
10:开启或关闭SNAT(源网络地址转换)技术。
11:设置端口转发策略。
12:控制请求icmp服务的流量。
13:管理防火墙的富规则。
14:被选中区域的服务,若勾选了相应服务前面的复选框,则表示允许与之相关的流量。
15:firewall-config工具的运行状态。
除了图中列出的功能,还有用于将网卡与区域绑定的Interfaces选项,以及用于将IP地址与区域绑定的Sources选项。另外再啰唆一句。在使用firewall-config工具配置完防火墙策略之后,无须进行二次确认,因为只要有修改内容,它就自动进行保存。
下面进行动手实践环节。
先将当前区域中请求http服务的流量设置为允许放行,但仅限当前生效。具体配置如图所示:
尝试添加一条防火墙策略规则,使其放行访问8080~8088端口(TCP协议)的流量,并将其设置为永久生效,以达到系统重启后防火墙策略依然生效的目的。在按照下图所示的界面配置完毕之后,还需要在Options菜单中单击Reload Firewalld命令,让配置的防火墙策略立即生效。这与在命令行中使用–reload参数的效果一样。
放行访问8080~8088端口的流量:
让配置的防火墙策略规则立即生效:
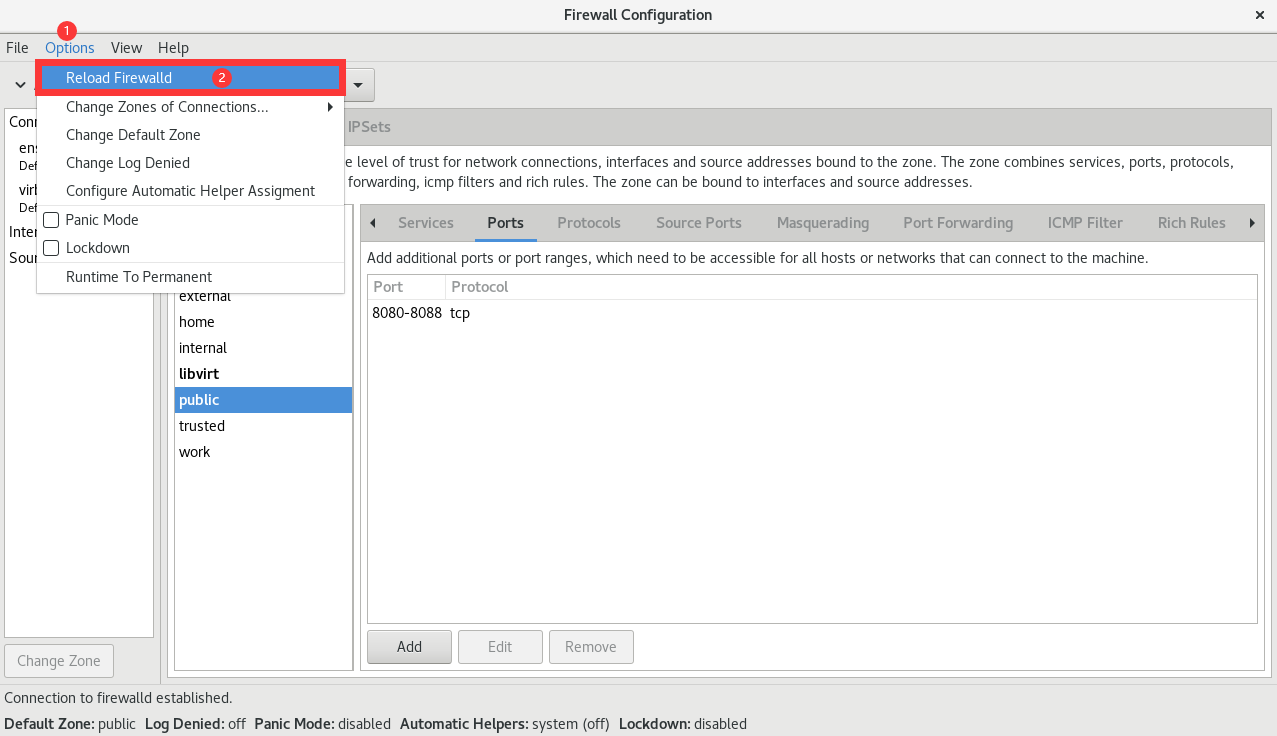
前面在讲解firewall-config工具的功能时,曾经提到了SNAT(Source Network Address Translation,源网络地址转换)技术。SNAT是一种为了解决IP地址匮乏而设计的技术,它可以使得多个内网中的用户通过同一个外网IP接入Internet。该技术的应用非常广泛,甚至可以说我们每天都在使用,只不过没有察觉到罢了。比如,当通过家中的网关设备(无线路由器)访问本书配套站点www.linuxprobe.com时,就用到了SNAT技术。
大家可以看一下在网络中不使用SNAT技术和使用SNAT技术时的情况。在没有使用SNAT技术的局域网中有多台PC,如果网关服务器没有应用SNAT技术,则互联网中的网站服务器在收到PC的请求数据包,并回送响应数据包时,将无法在网络中找到这个私有网络的IP地址,所以PC也就收不到响应数据包了。在使用SNAT技术处理过的局域网中,由于网关服务器应用了SNAT技术,所以互联网中的网站服务器会将响应数据包发给网关服务器,再由后者转发给局域网中的PC。
没有使用SNAT技术的网络:
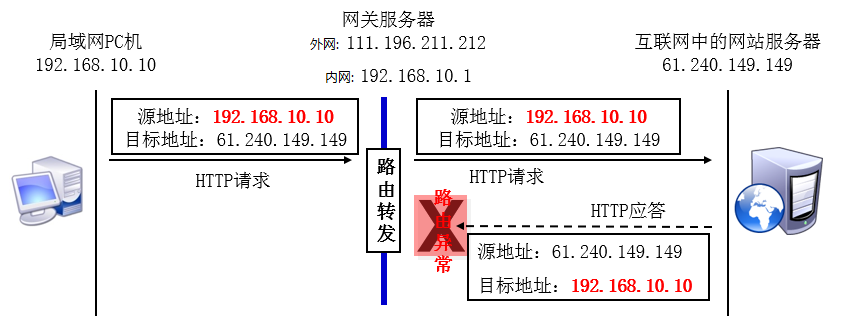
使用SNAT技术处理过的网络:
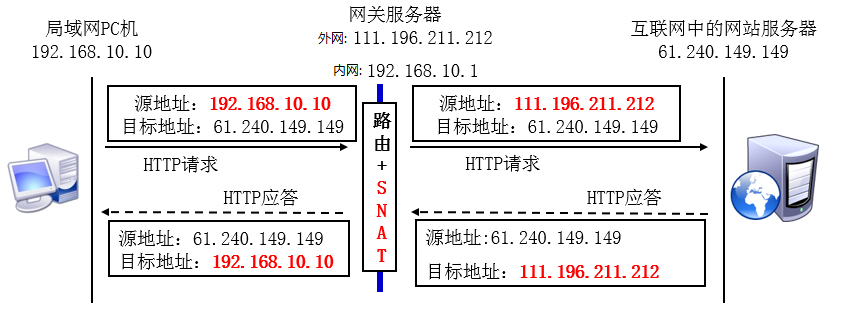
使用iptables命令实现SNAT技术是一件很麻烦的事情,但是在firewall-config中却是小菜一碟了。用户只需按照下图进行配置,并选中Masquerade zone复选框,就自动开启了SNAT技术。
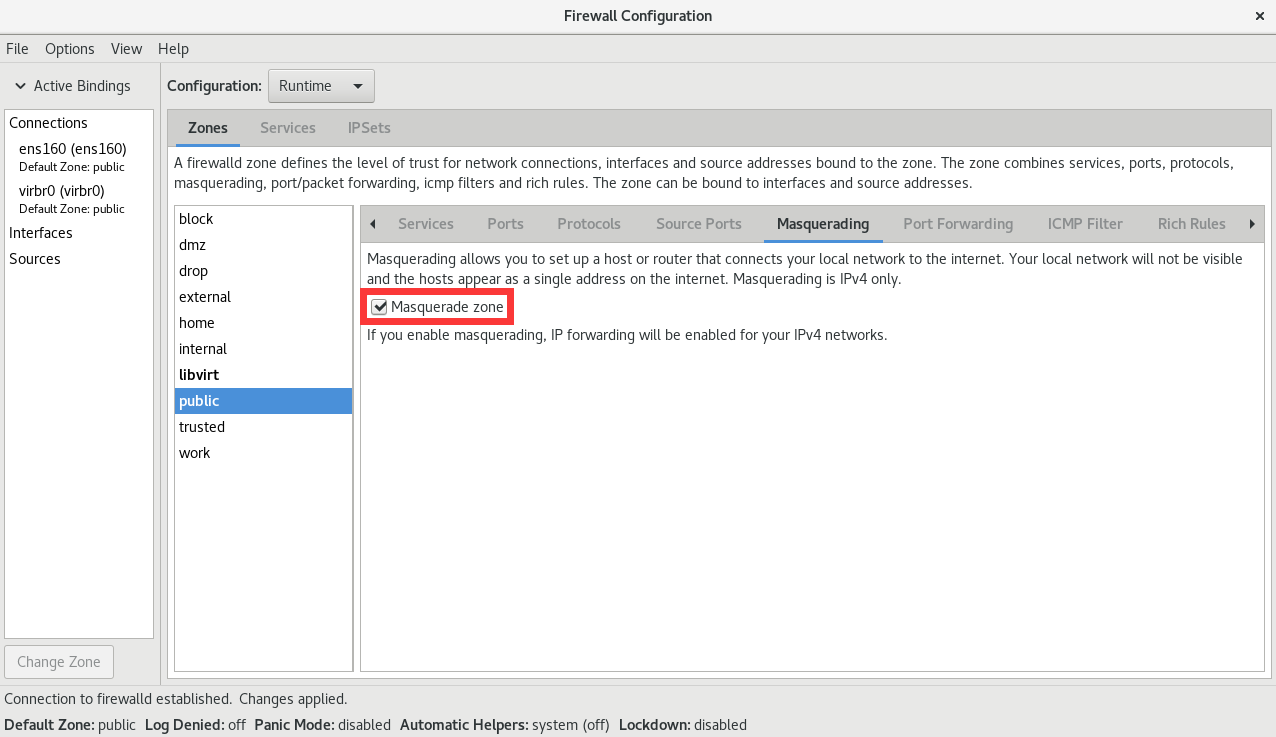
为了让大家直观查看不同工具在实现相同功能时的区别,针对前面使用firewall-cmd配置的防火墙策略规则,这里使用firewall-config工具进行了重新演示:将本机888端口的流量转发到22端口,且要求当前和长期均有效,具体如下图所示:
配置本地的端口转发:
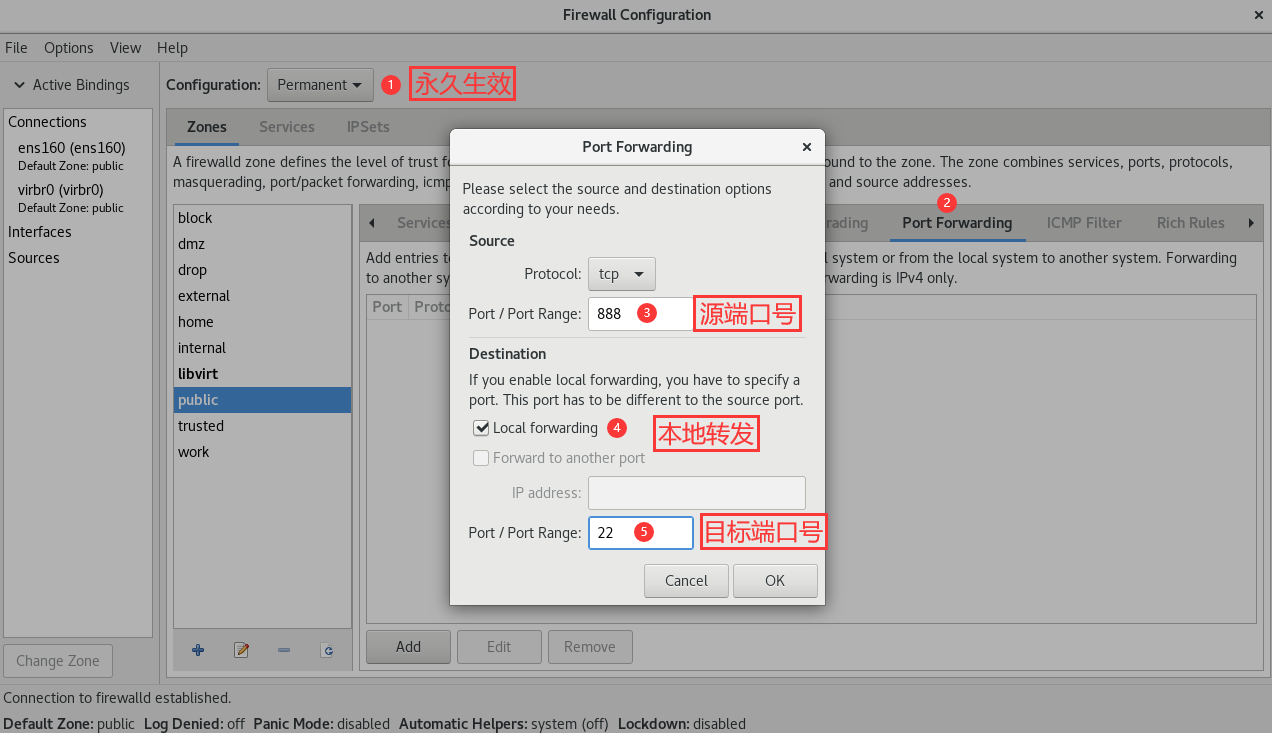
让防火墙效策略规则立即生效:
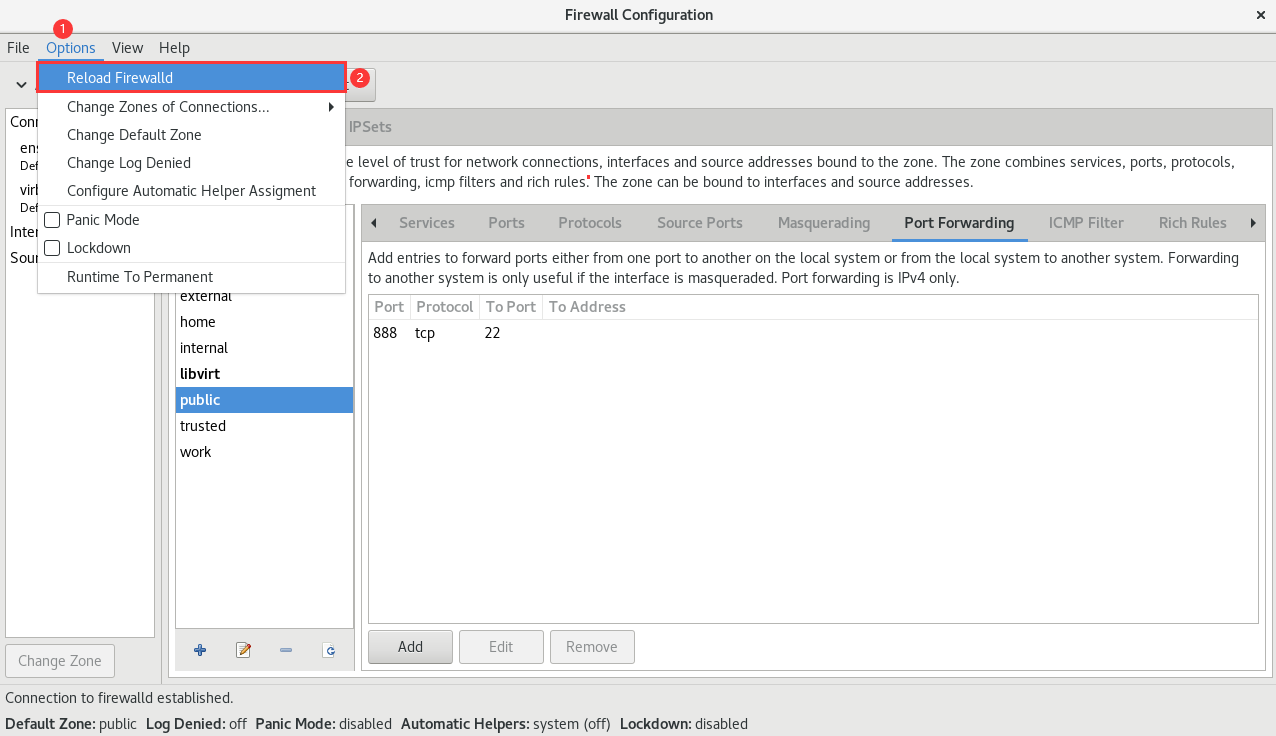
用命令配置富规则可真辛苦,幸好我们现在有了图形用户界面的工具。让192.168.10.20主机访问本机的1234端口号,如下图所示。其中Element选项能够根据服务名称、端口号、协议等信息进行匹配;Source与Destination选项后的inverted复选框代表反选功能,将其选中则代表对已填写信息进行反选,即选中填写信息以外的主机地址;Log复选框在选中后,日志不仅会被记录到日志文件中,而且还可以在设置日志的级别(Level)后,再将日志记录到日志文件中,以方便后续的筛查。
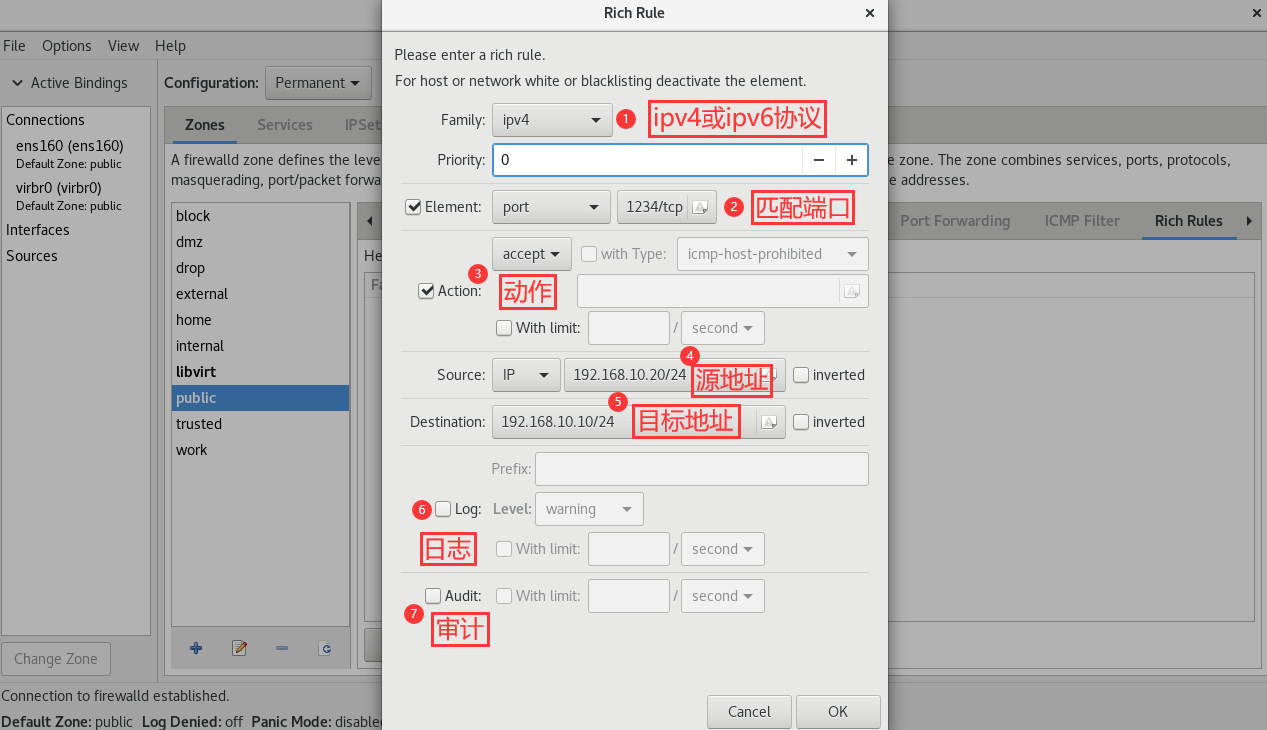
如果生产环境中的服务器有多块网卡在同时提供服务(这种情况很常见),则对内网和对外网提供服务的网卡要选择的防火墙策略区域也是不一样的。也就是说,可以把网卡与防火墙策略区域进行绑定,这样就可以使用不同的防火墙区域策略,对源自不同网卡的流量进行有针对性的监控,效果会更好。
把网卡与防火墙策略区域进行绑定:
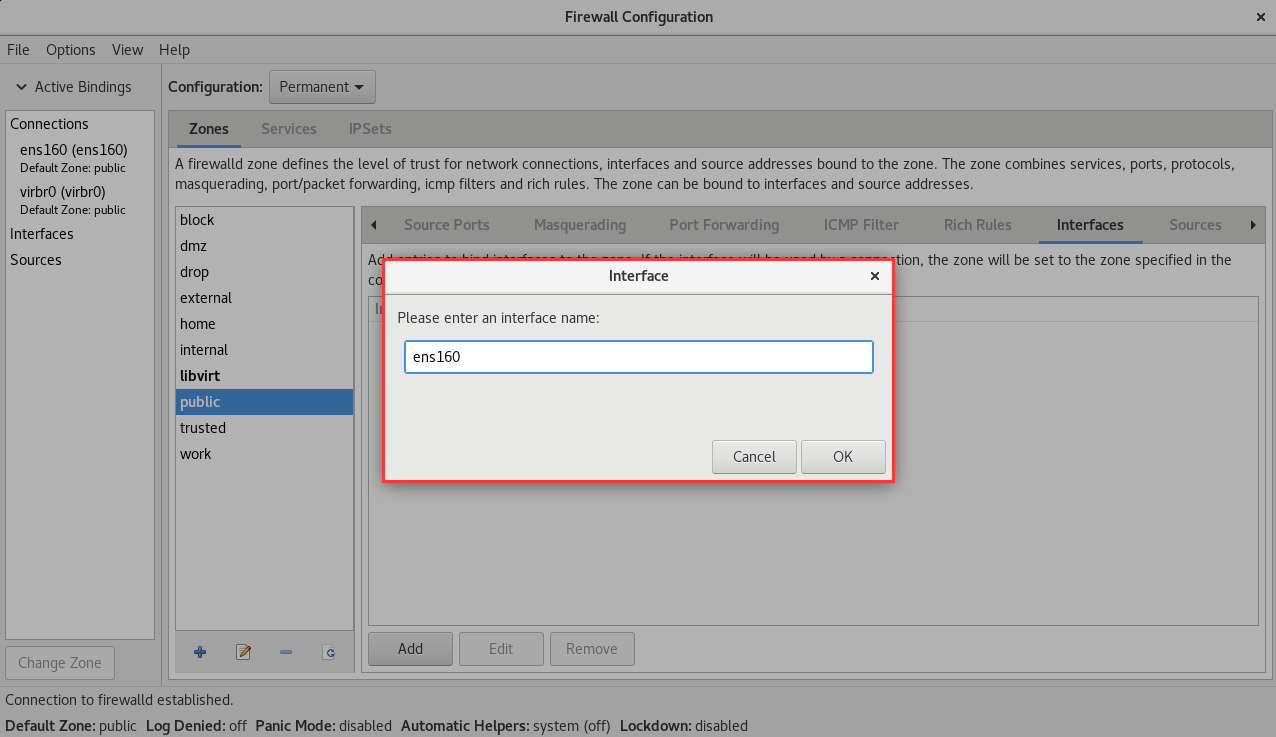
网卡与策略区域绑定完成:
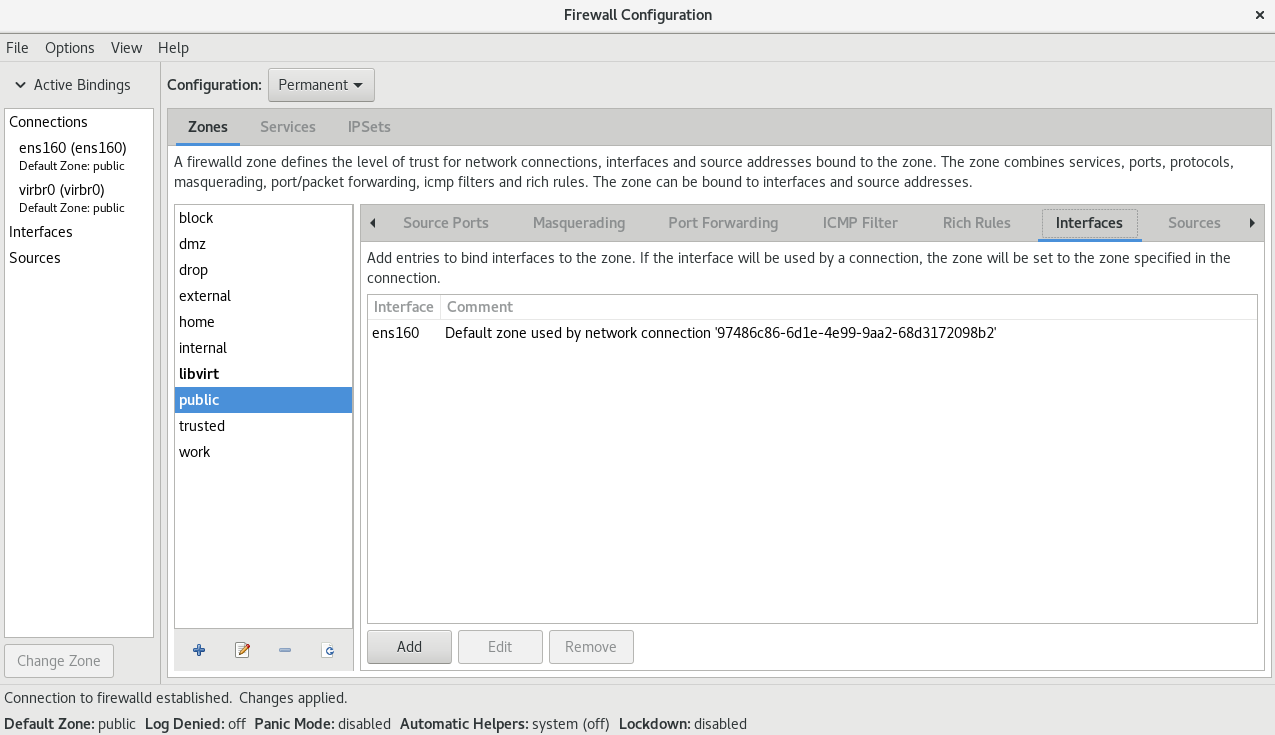
最后再提一句,firewall-config工具真的非常实用,很多原本复杂的长命令被图形化按钮替代,设置规则也简单明了,足以应对日常工作。所以再次向大家强调配置防火墙策略的原则—只要能实现所需的功能,用什么工具请随君便。
服务的访问控制列表
TCP Wrapper是RHEL 6/7系统中默认启用的一款流量监控程序,它能够根据来访主机的地址与本机的目标服务程序做出允许或拒绝的操作。在RHEL 8版本中,它已经被firewalld正式替代。换句话说,Linux系统中其实有两个层面的防火墙,第一种是前面讲到的基于TCP/IP协议的流量过滤工具,而TCP Wrapper服务则是能允许或禁止Linux系统提供服务的防火墙,从而在更高层面保护了Linux系统的安全运行。
TCP Wrapper服务的防火墙策略由两个控制列表文件所控制,用户可以编辑允许控制列表文件来放行对服务的请求流量,也可以编辑拒绝控制列表文件来阻止对服务的请求流量。控制列表文件修改后会立即生效,系统将会先检查允许控制列表文件(/etc/hosts.allow),如果匹配到相应的允许策略则放行流量;如果没有匹配,则会进一步匹配拒绝控制列表文件(/etc/hosts.deny),若找到匹配项则拒绝该流量。如果这两个文件都没有匹配到,则默认放行流量。
由于RHEL 8版本已经不再支持TCP Wrapper服务程序,因此我们接下来选择在一台老版本的服务器上进行实验。TCP Wrapper服务的控制列表文件配置起来并不复杂,常用的参数如表所示。
| 客户端类型 | 示例 | 满足示例的客户端列表 |
|---|---|---|
| 单一主机 | 192.168.10.10 | IP地址为192.168.10.10的主机 |
| 指定网段 | 192.168.10. | IP段为192.168.10.0/24的主机 |
| 指定网段 | 192.168.10.0/255.255.255.0 | IP段为192.168.10.0/24的主机 |
| 指定DNS后缀 | .linuxprobe.com | 所有DNS后缀为.linuxprobe.com的主机 |
| 指定主机名称 | <www.linuxprobe.com> | 主机名称为www.linuxprobe.com的主机 |
| 指定所有客户端 | ALL | 所有主机全部包括在内 |
在配置TCP Wrapper服务时需要遵循两个原则:
- 编写拒绝策略规则时,填写的是服务名称,而非协议名称;
- 建议先编写拒绝策略规则,再编写允许策略规则,以便直观地看到相应的效果。
下面编写拒绝策略规则文件,禁止访问本机sshd服务的所有流量(无须修改/etc/hosts.deny文件中原有的注释信息):
[root@linuxprobe ~]# vim /etc/hosts.deny
#
# hosts.deny This file contains access rules which are used to
# deny connections to network services that either use
# the tcp_wrappers library or that have been
# started through a tcp_wrappers-enabled xinetd.
#
# The rules in this file can also be set up in
# /etc/hosts.allow with a 'deny' option instead.
#
# See 'man 5 hosts_options' and 'man 5 hosts_access'
# for information on rule syntax.
# See 'man tcpd' for information on tcp_wrappers
sshd:*
[root@linuxprobe ~]# ssh 192.168.10.10
ssh_exchange_identification: read: Connection reset by peer
接下来,在允许策略规则文件中添加一条规则,使其放行源自192.168.10.0/24网段,且访问本机sshd服务的所有流量。可以看到,服务器立刻就放行了访问sshd服务的流量,效果非常直观:
[root@linuxprobe ~]# vim /etc/hosts.allow
#
# hosts.allow This file contains access rules which are used to
# allow or deny connections to network services that
# either use the tcp_wrappers library or that have been
# started through a tcp_wrappers-enabled xinetd.
#
# See 'man 5 hosts_options' and 'man 5 hosts_access'
# for information on rule syntax.
# See 'man tcpd' for information on tcp_wrappers
sshd:192.168.10.
[root@linuxprobe ~]# ssh 192.168.10.10
The authenticity of host '192.168.10.10 (192.168.10.10)' can't be established.
ECDSA key fingerprint is 70:3b:5d:37:96:7b:2e:a5:28:0d:7e:dc:47:6a:fe:5c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.10.10' (ECDSA) to the list of known hosts.
root@192.168.10.10's password:
Last login: Wed May 4 07:56:29 2021
[root@linuxprobe ~]#
Cockpit 驾驶舱管理工具
首先,Cockpit是一个英文单词,即“(飞机、船或赛车的)驾驶舱、驾驶座”,它用名字传达出了功能丰富的特性。其次,Cockpit是一个基于Web的图形化服务管理工具,对用户相当友好,即便是新手也可以轻松上手。而且它天然具备很好的跨平台性,因此被广泛应用于服务器、容器、虚拟机等多种管理场景。最后,红帽公司对Cockpit也十分看重,直接将它默认安装到了RHEL 8系统中,由此衍生的CentOS和Fedora也都标配有Cockpit。
Cockpit在默认情况下就已经被安装到系统中。下面执行dnf命令对此进行确认:
[root@linuxprobe ~]# dnf install cockpit
Updating Subscription Management repositories.
Unable to read consumer identity
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
AppStream 3.1 MB/s | 3.2 kB 00:00
BaseOS 2.7 MB/s | 2.7 kB 00:00
Package cockpit-185-2.el8.x86_64 is already installed.
Dependencies resolved.
Nothing to do.
Complete!
但是,Cockpit服务程序在RHEL 8版本中没有自动运行,下面将它开启并加入到开机启动项中:
[root@linuxprobe ~]# systemctl start cockpit
[root@linuxprobe ~]# systemctl enable cockpit.socket
Created symlink /etc/systemd/system/sockets.target.wants/cockpit.socket → /usr/lib/systemd/system/cockpit.socket.
在Cockpit服务启动后,打开系统自带的浏览器,在地址栏中输入“本机地址:9090”即可访问。由于访问Cockpit的流量会使用HTTPS进行加密,而证书又是在本地签发的,因此还需要进行添加并信任本地证书的操作。
添加额外允许的证书:
确认信任本地证书:
进入Cockpit的登录界面后,输入root管理员的账号与系统密码,单击Log In按钮后即可进入:
进入Cockpit的Web界面,发现里面可谓“别有洞天”。Cockpit总共分为13个功能模块:系统状态(System)、日志信息(Logs)、硬盘存储(Storage)、网卡网络(Networking)、账户安全(Accounts)、服务程序(Services)、软件仓库(Applications)、报告分析(Diagnostic Reports)、内核排错(Kernel Dump)、SElinux、更新软件(Software Updates)、订阅服务(Subscriptions)、终端界面(Terminal)。下面逐一进行讲解。
1.System
进入Cockpit界面后默认显示的便是System(系统)界面,在该界面中能够看到系统架构、版本、主机名与时间等信息,还能够动态地展现出CPU、硬盘、内存和网络的复杂情况,这有点类似于Web版的“Winodws系统任务管理器”,属实好用。
系统状态界面:
2.Logs
这个模块能够提供系统的全部日志,但是同学们可能会好奇,“为什么下图中的内容这么有限呢”?原因出在图中的两个选项中:时间和日志级别。通过这两个选项可以让用户更快地找到所需信息,而不是像/var/log/message文件那样一股脑儿地都抛给用户。
日志信息界面:
3.Storage
这个功能模块是同学们最喜欢的一个模块,原因不是这个模块显示了硬盘的I/O读写负载情况,而是可以让用户通过该界面,用鼠标创建出RAID、LVM、VDO和iSCSI等存储设备。是的,您没有看错,RAID和LVM都可以用鼠标进行创建了,是不是很开心呢?
硬盘存储界面:
4.Networking
既然名为Networking模块,那么动态看网卡的输出和接收值肯定是这个模块的标配功能了。我们不仅可以在这里进行网卡的绑定(Bonding)和聚合(Team),还可以创建桥接网卡及添加VLAN。最下方会单独列出与网卡相关的日志信息。
网卡网络界面:
**5.**Accounts
大家千万别小看Accounts模块,虽然它的账户安全界面有些简陋,只有一个用于创建账户的按钮,但只要点击进入某个用户的管理界面中,马上会发现“别有洞天”——账户管理界面,这个界面中的功能非常丰富,我们在这里可以对用户进行重命名,设置用户的权限,还可以锁定、修改密码以及创建SSH密钥信息。
账户安全界面:
账户管理界面:
6.Services
在Services功能模块的界面中,可以查看系统中已有的服务列表和运行状态。单击某一服务,进入该服务的管理界面后,可以对具体的服务进行开启、关闭操作。在Services功能模块中设置了服务并将其加入到开机启动项后,在系统重启后也依然会为用户提供服务。
服务程序界面:
服务管理界面:
7.Applications
后期采用Cockpit或红帽订阅服务安装的软件都会显示在这个功能模块中。
软件仓库界面:
8.Diagnostic Report
Diagnostic Report模块的功能是帮助用户收集及分析系统的信息,找到系统出现问题的原因。单击Create Report按钮后大约两分钟左右,会出现报告生成完毕的弹窗。好吧,摊牌了,这个功能其实很鸡肋,就是将sosreport命令做成了一个网页按钮。
报告分析界面:
报告生成完毕:
9.Kernel Dump
Kernel Dump(Kdump)是一个在系统崩溃、死锁或死机时用来收集内核参数的一个服务。举例来说,如果有一天系统崩溃了,这时Kdump服务就会开始工作,将系统的运行状态和内核数据收集到一个名为dump core的文件中,以便后续让运维人员分析并找出问题所在。由于我们在安装系统时没有启动该服务,所以可以等到后续使用时再开启该功能界面。
内核排错界面:
10.SElinux
下图所示为SELinux服务的控制按钮和警告信息界面。
SElinux管理界面:
11.Software Updates
这里提到的Software Updates并不是我们用来更新其他常规软件的一个界面,而是用来对红帽客户订阅的服务进行更新的界面。用户只有在购买了红帽第三方服务后才能使用这里面的功能。在购买了红帽订阅服务后,用户便可以在这里下载到相应服务程序的最新版本和稳定版本。
更新软件界面:
12.Subscriptions
这里依然是一则红帽公司的“小广告”—如果想成为尊贵的红帽服务用户,要付费购买订阅服务。个人用户无须购买,而且这对我们的后续实验没有任何影响。
订阅服务界面:
12.Terminal
压轴的总是在最后。Cockpit服务提供了Shell终端的在线控制平台,可方便用户通过网页上的终端功能管理服务器。这个功能深受运维人员喜爱。
终端管理界面
至此,相信各位读者已经充分掌握了防火墙的管理能力。防火墙管理工具有很多种,我们任选其一即可。在配置后续的服务前,大家要记得检查网络和防火墙的状态,以避免出现服务明明配置正确,但无法从外部访问的情况,最终影响实验效果。
在 Ubuntu 上使用 UFW&GUFW
Ubuntu 20.04 随附了一个称为UFW(非复杂防火墙)的防火墙配置工具。 它是用于管理iptables防火墙规则的用户友好型前端。 它的主要目标是使防火墙的管理变得更容易,或者顾名思义,变得简单。而GUFW是UFW的图形介面。
检查UFW状态
UFW默认情况下处于禁用状态。 您可以使用以下命令检查UFW服务的状态:
sudo ufw status verbose
输出将显示防火墙状态为非活动:
Status: inactive
如果UFW已激活,则输出将类似于以下内容:
Status: active
UFW默认策略
UFW防火墙的默认行为是阻止所有传入和转发流量,并允许所有出站流量。 这意味着除非您专门打开端口,否则任何尝试访问您的服务器的人都将无法连接。 服务器上运行的应用程序和服务将可以访问外界。
默认策略在/etc/default/ufw文件中定义,可以通过手动修改文件或使用sudo ufw default <policy> <chain>命令来更改。
防火墙策略是建立更复杂和用户定义的规则的基础。 通常,最初的UFW默认策略是一个很好的起点。
应用配置文件
应用程序配置文件是INI格式的文本文件,描述了服务并包含该服务的防火墙规则。 在安装软件包期间,会在/etc/ufw/applications.d目录中创建应用程序配置文件。
您可以通过键入以下内容列出服务器上所有可用的应用程序配置文件:
$ sudo ufw app list
Available applications:
Nginx Full
Nginx HTTP
Nginx HTTPS
OpenSSH
要查找有关特定配置文件和包含的规则的更多信息,请使用以下命令:
$ sudo ufw app info 'Nginx Full'
Profile: Nginx Full
Title: Web Server (Nginx, HTTP + HTTPS)
Description: Small, but very powerful and efficient web server
Ports:
80,443/tcp
输出显示“ Nginx Full”配置文件打开了端口80和443。
您也可以为应用创建自定义配置文件。
启用UFW
如果要从远程位置连接到Ubuntu,则在启用UFW防火墙之前,必须明确允许传入的SSH连接。 否则,您将无法连接到计算机。
要将您的UFW防火墙配置为允许传入的SSH连接,请键入以下命令:
$ sudo ufw allow ssh
Rules updated
Rules updated (v6)
如果SSH在非标准端口上运行,则需要打开该端口。
例如,如果您的ssh守护程序侦听端口7722,请输入以下命令以允许该端口上的连接:
sudo ufw allow 7722/tcp
现在已将防火墙配置为允许传入的SSH连接,您可以通过键入以下内容来启用它:
$ sudo ufw enable
Command may disrupt existing ssh connections. Proceed with operation (y|n)? y
Firewall is active and enabled on system startup
将警告您启用防火墙可能会破坏现有的ssh连接,只需键入y并单击Enter。
打开端口
根据系统上运行的应用程序,您可能还需要打开其他端口。 打开端口的一般语法如下:
ufw allow port_number/protocol
以下是有关如何允许HTTP连接的几种方法。
第一种选择是使用服务名称。 UFW检查/etc/services文件中指定服务的端口和协议:
sudo ufw allow http
您还可以指定端口号和协议:
sudo ufw allow 80/tcp
如果未给出协议,则UFW会同时为tcp和udp创建规则。
另一个选择是使用应用程序配置文件; 在这种情况下,“ Nginx HTTP”:
sudo ufw allow 'Nginx HTTP'
UFW还支持使用proto关键字指定协议的另一种语法:
sudo ufw allow proto tcp to any port 80
端口范围
UFW还允许您打开端口范围。 起始端口和结束端口用冒号(:)分隔,并且您必须指定协议tcp或udp。
例如,如果要同时在tcp和udp上允许端口从7100到7200,则可以运行以下命令:
sudo ufw allow 7100:7200/tcp
特定的IP地址和端口
要允许来自给定源IP的所有端口上的连接,请使用from关键字,后跟源地址。
以下是将IP地址列入白名单的示例:
sudo ufw allow from 64.63.62.61
如果要仅允许给定IP地址访问特定端口,请使用to any port关键字,后跟端口号。
例如,要允许IP地址为64.63.62.61的计算机访问端口22,请输入:
sudo ufw allow from 64.63.62.61 to any port 22
子网
允许连接到IP地址子网的语法与使用单个IP地址时的语法相同。 唯一的区别是您需要指定子网掩码。
下面是一个示例,显示了如何允许访问从192.168.0.1到192.168.0.254的IP地址到端口7890(clash):
sudo ufw allow from 192.168.0.0/24 to any port 7890
特定网络接口
要允许在特定的网络接口上进行连接,请使用in on关键字,后跟网络接口(网卡)的名称:
sudo ufw allow in on eth2 to any port 3306
拒绝连接
所有传入连接的默认策略均设置为deny,如果您未更改默认策略,除非您专门打开连接,否则UFW会阻止所有传入连接。
撰写拒绝规则与撰写允许规则相同; 您只需要使用deny关键字而不是allow。
假设您打开了端口80和443,并且服务器受到23.24.25.0/24网络的攻击。 要拒绝来自23.24.25.0/24的所有连接,您可以运行以下命令:
sudo ufw deny from 23.24.25.0/24
以下是拒绝访问23.24.25.0/24中的端口80和443的示例,您可以使用以下命令:
sudo ufw deny proto tcp from 23.24.25.0/24 to any port 80,443
删除UFW规则
有两种方法可以通过规则编号和指定实际规则来删除UFW规则。
按规则号删除规则比较容易,尤其是当您不熟悉UFW时。 要首先通过规则编号删除规则,您需要找到要删除的规则的编号。 要获取编号规则的列表,请使用ufw status numbered命令:
$ sudo ufw status numbered
Status: active
To Action From
-- ------ ----
[ 1] 22/tcp ALLOW IN Anywhere
[ 2] 80/tcp ALLOW IN Anywhere
[ 3] 8080/tcp ALLOW IN Anywhere
要删除规则号3,该规则号允许连接到端口8080,请输入:
sudo ufw delete 3
第二种方法是通过指定实际规则来删除规则。 例如,如果您添加了打开端口8069的规则,则可以使用以下命令将其删除:
sudo ufw delete allow 8069
禁用UFW
如果出于任何原因要停止UFW并停用所有规则,则可以使用:
sudo ufw disable
以后,如果您想重新启用UTF并激活所有规则,只需键入:
sudo ufw enable
重设UFW
重置UFW将禁用UFW,并删除所有活动规则。 如果您想还原所有更改并重新开始,这将很有帮助。
要重置UFW,请输入以下命令:
sudo ufw reset
IP伪装
IP伪装是Linux内核中NAT(网络地址转换)的一种变体,它通过重写源IP地址和目标IP地址和端口来转换网络流量。 借助IP伪装,您可以使用一台充当网关的Linux计算机,允许专用网络中的一台或多台计算机与Internet通信。
使用UFW配置IP伪装涉及几个步骤。
首先,您需要启用IP转发。 为此,请打开/etc/ufw/sysctl.conf文件,查找并取消注释以下行:net.ipv4.ip_forward = 1:
$ sudo nano /etc/ufw/sysctl.conf
net/ipv4/ip_forward=1
接下来,您需要配置UFW以允许转发数据包。 打开UFW配置文件,找到DEFAULT_FORWARD_POLICY键,然后将值从DROP更改为ACCEPT:
$ sudo nano /etc/default/ufw
DEFAULT_FORWARD_POLICY="ACCEPT"
现在,您需要在nat表中设置POSTROUTING链的默认策略和伪装规则。 为此,请打开/etc/ufw/before.rules文件,附加以下几行:
$ sudo nano /etc/ufw/before.rules
#NAT table rules
*nat
:POSTROUTING ACCEPT [0:0]
# Forward traffic through eth0 - Change to public network interface
-A POSTROUTING -s 10.8.0.0/16 -o eth0 -j MASQUERADE
# don't delete the 'COMMIT' line or these rules won't be processed
COMMIT
别忘了在-A POSTROUTING行中替换eth0以匹配公共网络接口的名称:
完成后,保存并关闭文件。
最后,通过禁用和重新启用UFW重新加载UFW规则:
sudo ufw disable
sudo ufw e
Linux Kernel
来自 Wikipedia:
内核是计算机操作系统的核心组件,对系统有完全的控制。开机时最先启动,然后负责后续的启动工作。它负责处理其它软件的请求,将这些请求转化为中央处理器的数据处理请求。内核还负责管理内存,管理系统和其它打印机、扬声器等外围设备的通讯,是操作系统最基础的部分。
内核包安装在/boot/下的文件系统上。为了能够引导到内核,必须适当配置启动加载器。
Kernel module
内核模块是可以按需加载或卸载的内核代码,可以不重启系统就扩充内核的功能。
要创建内核模块,请阅读此指南。模块可以设置成内置或者动态加载,要编译成可动态加载,需要在内核配置时将模块配置为 M (模块)。
获取信息
模块保存在 /lib/modules/kernel_release (使用 uname -r 命令显示当前内核版本)。
注意: 模块名通常使用 (_) 或 - 连接,但是这些符号在 modprobe 命令和 /etc/modprobe.d/ 配置文件中都是可以相互替换的。
显示当前装入的内核模块:
lsmod
在上面的输出中:
Module显示每个模块的名称Size显示每个模块的大小(并不是它们占的内存大小)Used by显示每个模块被使用的次数和使用它们的模块
显然,这里有很多模块。加载的模块数量取决于你的系统和版本以及正在运行的内容。我们可以这样计数:
$ lsmod | wc -l
67
modules.builtin 文件中列出了所有构建在内核中的模块
$ more /lib/modules/$(uname -r)/modules.builtin | head -10
kernel/arch/x86/crypto/crc32c-intel.ko
kernel/arch/x86/events/intel/intel-uncore.ko
kernel/arch/x86/platform/intel/iosf_mbi.ko
kernel/mm/zpool.ko
kernel/mm/zbud.ko
kernel/mm/zsmalloc.ko
kernel/fs/binfmt_script.ko
kernel/fs/mbcache.ko
kernel/fs/configfs/configfs.ko
kernel/fs/crypto/fscrypto.ko
显示模块信息:
modinfo module_name
显示所有模块的配置信息:
modprobe -c | less
显示某个模块的配置信息:
modprobe -c | grep module_name
显示一个装入模块使用的选项:
systool -v -m module_name
显示模块的依赖关系:
modprobe --show-depends module_name
使用systemd自动加载模块
目前,所有必要模块的加载均由 udev 自动完成。所以,如果不需要使用任何额外的模块,就没有必要在任何配置文件中添加启动时加载的模块。但是,有些情况下可能需要在系统启动时加载某个额外的模块,或者将某个模块列入黑名单以便使系统正常运行。
内核模块可以在/etc/modules-load.d/ 下的文件中明确列出,以便systemd在引导过程中加载它们。 每个配置文件都以 /etc/modules-load.d/<program>.conf的样式命名。 配置文件仅包含要加载的内核模块名称列表,以换行符分隔。 空行和第一个非空白字符为#或;的行被忽略。
$ cat /etc/modules-load.d/virtio-net.conf
# Load virtio_net.ko at boot
virtio_net
手动加载卸载
控制内核模块载入/移除的命令是kmod 软件包提供的, 要手动装入模块的话,执行:
# modprobe module_name
按文件名加载模块:
# insmod filename [args]
注意: 如果升级了内核但是没有重启,路径 /usr/lib/modules/$(uname -r)/ 已经不存在。modprobe 会返回错误 1,没有额外的错误信息。如果出现 modprobe 加载失败,请检查模块路径以确认是否是这个问题导致。
如果要移除一个模块:
# modprobe -r module_name
或者:
# rmmod module_name
配置模块参数
手动加载时设置
传递参数的基本方式是使用 modprobe 选项,格式是 key=value:
# modprobe module_name parameter_name=parameter_value
使用 /etc/modprobe.d/中的文件
要通过配置文件传递参数,在 /etc/modprobe.d/ 中放入任意名称 .conf 文件,加入:
$ sudo gedit /etc/modprobe.d/myfilename.conf
options modname parametername=parametercontents
例如
$ sudo gedit /etc/modprobe.d/thinkfan.conf
# On thinkpads, this lets the thinkfan daemon control fan speed
options thinkpad_acpi fan_control=1
注意: 如果要在启动时就修改内核参数(从 init ramdisk 开始),需要将相应的.conf-文件加入 mkinitcpio.conf 的 FILES 参数中。
使用内核命令行
如果模块直接编译进内核,也可以通过启动管理器(GRUB, LILO 或 Syslinux)的内核行加入参数:
modname.parametername=parametercontents
例如:
thinkpad_acpi.fan_control=1
别名
$ cat /etc/modprobe.d/myalias.conf
# Lets you use 'mymod' in MODULES, instead of 'really_long_module_name'
alias mymod really_long_module_name
有些模块具有别名,以方便其它程序自动装入模块。禁用这些别名可以阻止自动装入,但是仍然可以手动装入。
$ cat /etc/modprobe.d/modprobe.conf
# Prevent autoload of bluetooth
alias net-pf-31 off
# Prevent autoload of ipv6
alias net-pf-10 off
黑名单
禁用内核模块
对内核模块来说,黑名单是指禁止某个模块装入的机制。当对应的硬件不存在或者装入某个模块会导致问题时很有用。
有些模块作为 initramfs 的一部分装入。
mkinitcpio -M 会显示所有自动检测到到模块:要阻止 initramfs 装入某些模块,可以在 /etc/modprobe.d中将它们加入黑名单。并应在映像生成过程中通过modconf挂钩将其添加。
运行 mkinitcpio -v 会显示各种钩子(例如 filesystem 钩子, SCSI 钩子等)装入的模块。如果您的HOOKS 数组中没有 modconf 钩子(例如,和默认配置不同)则请将该”.conf"文件添加到/etc/mkinitcpio.conf中的FILES数组中。一旦您将其列入黑名单,请重新生成 initramfs,然后重新启动。
使用 /etc/modprobe.d/ 中的文件
在 /etc/modprobe.d/ 中创建 .conf 文件,使用 blacklist 关键字屏蔽不需要的模块,例如如果不想装入 pcspkr 模块:
$ sudo gedit /etc/modprobe.d/nobeep.conf
# Do not load the pcspkr module on boot
blacklist pcspkr
注意: blacklist 命令将屏蔽一个模板,所以不会自动装入,但是如果其它非屏蔽模块需要这个模块,系统依然会装入它。
要避免这个行为,可以让 modprobe 使用自定义的 install 命令,而不是像往常一样将模块插入内核,因此您可以通过以下方式强制模块始终无法加载:
$ sudo gedit /etc/modprobe.d/blacklist.conf
...
install MODULE /bin/true
...
这样就可以 “屏蔽” 模块及所有依赖它的模块。
使用内核命令行
提示: 如果模块损坏导致无法引导系统,这将非常有用。
您也可以从引导加载程序中将模块列入黑名单。
如Kernel参数.中所述,只需将module_blacklist=modname1,modname2,modname3 添加到引导加载程序的内核行中即可。
注意: 将多个模块列入黑名单时,请注意,它们之间仅用逗号分隔。 空格或其他内容可能会破坏语法。
Kernel parameters
一共有三种办法,可以给内核传递参数,用于控制其行为方式:
- 在编译内核时(这个最根本,会决定后面两种方法)
- 内核启动时(通常是在一个启动管理器里设置).
- 在运行时 (通过修改在
/proc和/sys中的文件).
本页面主要是讲第二种方法。内核参数可以在启动时临时修改,也可以永久性写到启动管理器的配置文件中,永远起作用。下面示例把参数quiet 和 splash 加到启动管理器。
systemd-boot
-
当启动菜单出现时 按
e进入编辑界面:initrd=\initramfs-linux.img root=/dev/sda2 quiet splash -
如果想永久加入参数,编辑
/boot/loader/entries/arch.conf(假设你已经设置好了 EFI system partition) 的options行:
注意:
- 如果没有设置显示启动菜单, 你需要按住
Space启动电脑来进入启动菜单 。 - 如果不能够从启动菜单上进行编辑,修改
/boot/loader/loader.conf加入editor 1来开启编辑功能。
更多信息请参见 systemd-boot .
GRUB
-
在菜单出现后按
e然后将它们添加至linux行:linux /boot/vmlinuz-linux root=UUID=978e3e81-8048-4ae1-8a06-aa727458e8ff ro quiet splash按 b 以便用这些参数启动。
-
要使改变在重启后仍生效,您可以手动编辑
/boot/grub/grub.cfg中的如上内容。对于初学者,建议编辑/etc/default/grub并将您的内核选项添加至GRUB_CMDLINE_LINUX_DEFAULT行:GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"然后重新生成
grub.cfg文件:# grub-mkconfig -o /boot/grub/grub.cfg
有关配置GRUB的更多信息,请参阅 GRUB 。
发布时间表
内核发布时间表:有吗?
短的回答是,每两到三个月就有一个新的内核版本发布。长的回答是,这不是一个硬性规定。
这个意思是,你经常会看到每两到三个月就有一个新的内核版本发布。这是内核维护者团队的目标,但并没有规定新版本必须在前一个版本的 8 周后准时发布的期限。
新的内核版本(通常)是由 Linus Torvalds 在它准备好的时候发布的。通常是每 2 到 3 个月发布一次。该版本被宣布为“稳定”,一般以 X.Y 的格式编号。
但这并不是 X.Y 开发的结束。稳定版会有更多的小版本以进行错误的修复。这些小版本在稳定版的内核上又增加了一个点,就像是 X.Y.Z。
虽然 X.Y(通常)是由 Linux 创造者 Linus Torvalds 发布的,但是维护稳定的 X.Y 内核、合并错误修复和发布 X.Y.Z 版本的责任是由另外的内核开发者负责的。
一个内核版本支持多长时间?
和发布一样,一个内核版本支持多长时间也没有固定的日期和时间表。
一个普通的稳定内核版本通常会被支持两个半月到三个月,这取决于下一个稳定内核版本的发布时间。
例如,稳定版内核 5.14 会在稳定版内核 5.15 发布后的几周内达到生命末期。结束支持是由该稳定内核版本的维护者在 Linux 内核邮件列表中宣布的。用户和贡献者会被要求切换到新发布的稳定版本。
但这只适用于正常的稳定内核版本,还有 LTS(长期支持)内核版本,它们的支持期要比 3 个月长得多。
LTS 内核:它支持多长时间?
LTS 内核也没有固定的发布时间表。通常,每年都有一个 LTS 内核版本,一般是当年的最后一个版本,它至少会被支持两年。但同样,这里也没有固定的规则。
LTS 内核的维护者可以同意某个 LTS 内核的维护时间超过通常的两年。这个协议是根据必要性和参与的人员来达成的。
这种情况经常发生在 Android 项目中。由于两年的时间不足以让制造商结束对他们的硬件和软件功能的支持,你经常会发现一些 LTS 内核会被支持六年之久。
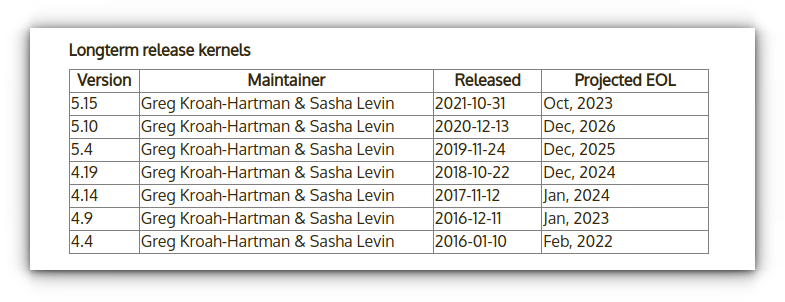
你可以 在 Linux 内核网站上 找到这个信息。
你的发行版可能没有跟随通常的 Linux 内核版本
如果你检查你的 Linux 内核版本,你可能会发现 你的发行版使用了一个旧的内核。也有可能该发行版提供的内核已经在内核网站上被标记为到达了生命末期。
不要惊慌。你的发行版会负责修补内核的错误和漏洞。除非你真的在使用一个不知名的 Linux 发行版,否则你可以相信你的发行版会保持它的安全和健全。
如果你有足够的理由,比如为了支持更新的硬件,你可以自由地在你使用的任何发行版或 Ubuntu 中安装最新的 Linux 内核 。
如果你想了解更多细节,我已经 在这里解释了为什么你的发行版使用过时的 Linux 内核。
安装内核
dpkg
从 kernel.ubuntu.com 网站手动下载可用的最新 Linux 内核:
- linux-image-X.Y.Z-generic-.deb
- linux-modules-X.Y.Z-generic-.deb
手动安装内核:
sudo dpkg --install *.deb
重启系统,使用新内核:
sudo reboot
检查是否如你所愿:
uname -r
apt-get
不同于上一个方法,这种方法会从 Ubuntu 官方仓库下载、安装内核版本:
运行:
sudo apt-get upgrade linux-image-generic
XanMod Kernel
最新内核集成的一些新特性的确是可以提升性能的。xanmod 内核的安装可以去它们的官方网站来查询,xanmod 内核的特性很多地方都有,官方也写的有很多,不过大多数还是以下几点:
- 改善了 CPU 调度能力
- 改善了 I/O 的调度能力
- 增加了一些和性能有关的第三方补丁
- 使用了最新的 GCC 进行编译
- 使用了最新的 MicroCode
安装的方式也比较简单,添加源并且更新安装就行了:
echo 'deb http://deb.xanmod.org releases main' | sudo tee /etc/apt/sources.list.d/xanmod-kernel.list && wget -qO - https://dl.xanmod.org/gpg.key | sudo apt-key add -
然后安装,我个人安装的是最新的 5.8.1 的 edge:
sudo apt update && sudo apt install linux-xanmod-edge
安装完毕后还可以安装最新的微码:
sudo apt update && sudo apt install linux-xanmod
重启以应用
sudo reboot
Zen/Liquorix Kernel
- 一些内核黑客合作的结果,是适合日常使用的优秀内核
- 以吞吐量和功耗为代价来换取性能
- 相对 linux 内核加入了 Fsync 功能。Fsync 是维尔福公司发布的一个可以帮助提升大量多线程应用运行帧率的特殊内核补丁,这对改善游戏性能有很大帮助。在一些采用 .Net 的 wine 游戏中会有 明显的性能提升
- 如果你使用英伟达显卡,记得更换驱动为相应的 dkms 版本。一般来说较新的显卡安装 nvidia-dkms 即可。DKMS,即 Dynamic Kernel Module System。可以使内核变更(如升级)后自动编译模块,适配新内核。
Questions about: I’m not a kernel expert, but my understanding is that there are different ways for the kernel to prioritize tasks to be processed by the CPU. Priority on a server or workstation is different from a gaming PC. The Zen (and Liquorix) kernel alters the way this is done to optimise for gaming and multimedia. From what I can tell, the difference between the Zen and Liquorix kernels is the scheduler used, but are otherwise the same. There’s more info here.
Ubuntu Prerequisites:
sudo add-apt-repository ppa:damentz/liquorix && sudo apt-get update
The Liquorix kernel can be installed by way of meta-packages. This will guarantee that the latest kernel is installed on every upgrade.
64-bit:
sudo apt-get install linux-image-liquorix-amd64 linux-headers-liquorix-amd64
Mainline Kernel
切換内核
可以通过修改 /etc/default/grub 中的 GRUB_DEFAULT 值来改变默认启动项。
查看 grub menu 目前的選項 :
$ grep -A100 submenu /boot/grub/grub.cfg |grep menuentry
submenu 'Advanced options for Ubuntu' $menuentry_id_option 'gnulinux-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29' {
menuentry 'Ubuntu, with Linux 4.4.0-1062-aws' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-1062-aws-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29' {
menuentry 'Ubuntu, with Linux 4.4.0-1062-aws (recovery mode)' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-1062-aws-recovery-4a67ec61-9cd5-4a26-b00f-9391a34c8a29' {
menuentry 'Ubuntu, with Linux 4.4.0-1061-aws' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-1061-aws-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29' {
menuentry 'Ubuntu, with Linux 4.4.0-1061-aws (recovery mode)' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.4.0-1061-aws-recovery-4a67ec61-9cd5-4a26-b00f-9391a34c8a29' {
接下來修改 grub config 檔案:
sudo nano /etc/default/grup
找到 GRUB_DEFAULT=0 ,將數字 0 改成想用來開機的 kernel,以這個例子來說:
- 0 = ‘Ubuntu, with Linux 4.4.0-1062-aws’ = ‘gnulinux-4.4.0-1062-aws-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29’
- 1 = ‘Ubuntu, with Linux 4.4.0-1062-aws (recovery mode)’ = ‘gnulinux-4.4.0-1062-aws-recovery-4a67ec61-9cd5-4a26-b00f-9391a34c8a29’
- 2 = ‘Ubuntu, with Linux 4.4.0-1061-aws’ = ‘gnulinux-4.4.0-1061-aws-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29’
- 3 = ‘Ubuntu, with Linux 4.4.0-1061-aws (recovery mode)’ = ‘gnulinux-4.4.0-1061-aws-recovery-4a67ec61-9cd5-4a26-b00f-9391a34c8a29’
GRUB 启动项序号从 0 开始计数,0 代表第一个启动项,也是上述选项的默认值,1 表示第二个启动项,以此类推。主菜单和子菜单项之间用 > 隔开。
下面的例子启动的是主菜单项 ‘Advanced options for Arch Linux’ 下子菜单的第三项:
-
使用数字编号:
GRUB_DEFAULT=2 # or GRUB_DEFAULT="1>2" -
使用菜单标题:
GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 4.4.0-1061-aws" -
还可以这样:
GRUB_DEFAULT="gnulinux-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29>gnulinux-4.4.0-1061-aws-advanced-4a67ec61-9cd5-4a26-b00f-9391a34c8a29" -
更新 grup 設定:
sudo update-grub sudo reboot
删除旧内核
随着时间的流逝,持续的内核更新会在系统中积聚大量的不再使用的内核,浪费你的磁盘空间。每个内核镜像和其相关联的模块/头文件会占用200-400MB的磁盘空间,因此由不再使用的内核而浪费的磁盘空间会快速地增加。
GRUB管理器为每个旧内核都维护了一个GRUB入口,以备你想要使用它们。
作为磁盘清理的一部分,如果你不再使用这些,你可以考虑清理掉这些镜像。
在删除旧内核之前,记住最好留有2个最近的内核(最新的和上一个版本),以防主要的版本出错。
在Ubuntu内核镜像包含了以下的包。
- linux-image-: 内核镜像
- linux-image-extra-: 额外的内核模块
- linux-headers-: 内核头文件
首先检查系统中安装的内核镜像。
dpkg --list | grep linux-image
dpkg --list | grep linux-headers
在列出的内核镜像中,你可以移除一个特定的版本。
sudo apt-get purge linux-image-3.19.0-15
sudo apt-get purge linux-headers-3.19.0-15
上面的命令会删除内核镜像和它相关联的内核模块和头文件。
注意如果你还没有升级内核那么删除旧内核会自动触发安装新内核。这样在删除旧内核之后,GRUB配置会自动升级来移除GRUB菜单中相关GRUB入口。
如果你有很多没用的内核,你可以用shell表达式来一次性地删除多个内核。注意这个括号表达式只在bash或者兼容的shell中才有效。
sudo apt-get purge linux-image-3.19.0-{18,20,21,25}
sudo apt-get purge linux-headers-3.19.0-{18,20,21,25}
上面的命令会删除4个内核镜像:3.19.0-18、3.19.0-20、3.19.0-21 和 3.19.0-25。
如果GRUB配置由于任何原因在删除旧内核后没有正确升级,你可以尝试手动用update-grub2命令来更新配置。
sudo update-grub2
现在就重启来验证GRUB菜单是否已经正确清理了。
编写第一个内核模块
容器
Namespace
概念
**namespace 是 Linux 内核用来隔离内核资源的方式。**通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
用途
实际上,Linux 内核实现 namespace 的一个主要目的就是实现轻量级虚拟化(容器)服务。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到隔离的目的。也就是说 linux 内核提供的 namespace 技术为 docker 等容器技术的出现和发展提供了基础条件。
我们可以从 docker 实现者的角度考虑该如何实现一个资源隔离的容器。比如是不是可以通过 chroot 命令切换根目录的挂载点,从而隔离文件系统。为了在分布式的环境下进行通信和定位,容器必须要有独立的 IP、端口和路由等,这就需要对网络进行隔离。同时容器还需要一个独立的主机名以便在网络中标识自己。接下来还需要进程间的通信、用户权限等的隔离。最后,运行在容器中的应用需要有进程号(PID),自然也需要与宿主机中的 PID 进行隔离。也就是说这六种隔离能力是实现一个容器的基础,让我们看看 linux 内核的 namespace 特性为我们提供了什么样的隔离能力:

上表中的前六种 namespace 正是实现容器必须的隔离技术,至于新近提供的 Cgroup namespace 目前还没有被 docker 采用。相信在不久的将来各种容器也会添加对 Cgroup namespace 的支持。
发展历史
Linux 在很早的版本中就实现了部分的 namespace,比如内核 2.4 就实现了 mount namespace。大多数的 namespace 支持是在内核 2.6 中完成的,比如 IPC、Network、PID、和 UTS。还有个别的 namespace 比较特殊,比如 User,从内核 2.6 就开始实现了,但在内核 3.8 中才宣布完成。同时,随着 Linux 自身的发展以及容器技术持续发展带来的需求,也会有新的 namespace 被支持,比如在内核 4.6 中就添加了 Cgroup namespace。
Linux 提供了多个 API 用来操作 namespace,它们是 clone()、setns() 和 unshare() 函数,为了确定隔离的到底是哪项 namespace,在使用这些 API 时,通常需要指定一些调用参数:CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。如果要同时隔离多个 namespace,可以使用 | (按位或)组合这些参数。同时我们还可以通过 /proc 下面的一些文件来操作 namespace。
查看进程所属的 namespace
从版本号为 3.8 的内核开始,/proc/[pid]/ns 目录下会包含进程所属的 namespace 信息,使用下面的命令可以查看当前进程所属的 namespace 信息:
$ ll /proc/$$/ns
total 0
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 net -> 'net:[4026532008]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 time -> 'time:[4026531834]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 user -> 'user:[4026531837]'
lrwxrwxrwx 1 kurome kurome 0 Mar 3 11:33 uts -> 'uts:[4026531838]'
首先,这些 namespace 文件都是链接文件。链接文件的内容的格式为 xxx:[inode number]。其中的 xxx 为 namespace 的类型,inode number 则用来标识一个 namespace,我们也可以把它理解为 namespace 的 ID。如果两个进程的某个 namespace 文件指向同一个链接文件,说明其相关资源在同一个 namespace 中。
其次,在 /proc/[pid]/ns 里放置这些链接文件的另外一个作用是,一旦这些链接文件被打开,只要打开的文件描述符(fd)存在,那么就算该 namespace 下的所有进程都已结束,这个 namespace 也会一直存在,后续的进程还可以再加入进来。
除了打开文件的方式,我们还可以通过文件挂载的方式阻止 namespace 被删除。比如我们可以把当前进程中的 uts 挂载到 ~/uts 文件:
touch ~/uts
sudo mount --bind /proc/$$/ns/uts ~/uts
使用 stat 命令检查下结果:
stat ~/uts
很神奇吧,~/uts 的 inode 和链接文件中的 inode number 是一样的,它们是同一个文件。
clone() 函数
我们可以通过 clone() 在创建新进程的同时创建 namespace。clone() 在 C 语言库中的声明如下:
/* Prototype for the glibc wrapper function */
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
实际上,clone() 是在 C 语言库中定义的一个封装(wrapper)函数,它负责建立新进程的堆栈并且调用对编程者隐藏的 clone() 系统调用。Clone() 其实是 linux 系统调用 fork() 的一种更通用的实现方式,它可以通过 flags 来控制使用多少功能。一共有 20 多种 CLONE_ 开头的 falg(标志位) 参数用来控制 clone 进程的方方面面(比如是否与父进程共享虚拟内存等),下面我们只介绍与 namespace 相关的 4 个参数:
- fn:指定一个由新进程执行的函数。当这个函数返回时,子进程终止。该函数返回一个整数,表示子进程的退出代码。
- child_stack:传入子进程使用的栈空间,也就是把用户态堆栈指针赋给子进程的 esp 寄存器。调用进程(指调用 clone() 的进程)应该总是为子进程分配新的堆栈。
- flags:表示使用哪些 CLONE_开头的标志位,与 namespace 相关的有CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。
- arg:指向传递给 fn() 函数的参数。
setns() 函数
通过 setns() 函数可以将当前进程加入到已有的 namespace 中。setns() 在 C 语言库中的声明如下:
#define _GNU_SOURCE
#include <sched.h>
int setns(int fd, int nstype);
和 clone() 函数一样,C 语言库中的 setns() 函数也是对 setns() 系统调用的封装:
- fd:表示要加入 namespace 的文件描述符。它是一个指向 /proc/[pid]/ns 目录中文件的文件描述符,可以通过直接打开该目录下的链接文件或者打开一个挂载了该目录下链接文件的文件得到。
- nstype:参数 nstype 让调用者可以检查 fd 指向的 namespace 类型是否符合实际要求。若把该参数设置为 0 表示不检查。
前面我们提到:可以通过挂载的方式把 namespace 保留下来。保留 namespace 的目的是为以后把进程加入这个 namespace 做准备。在 docker 中,使用 docker exec 命令在已经运行着的容器中执行新的命令就需要用到 setns() 函数。为了把新加入的 namespace 利用起来,还需要引入 execve() 系列的函数,该函数可以执行用户的命令,比较常见的用法是调用 /bin/bash 并接受参数运行起一个 shell。
unshare() 函数
通过 unshare 函数可以在原进程上进行 namespace 隔离。也就是创建并加入新的 namespace 。unshare() 在 C 语言库中的声明如下:
#define _GNU_SOURCE
#include <sched.h>
int unshare(int flags);
和前面两个函数一样,C 语言库中的 unshare() 函数也是对 unshare() 系统调用的封装。调用 unshare() 的主要作用就是:不启动新的进程就可以起到资源隔离的效果,相当于跳出原先的 namespace 进行操作。
系统还默认提供了一个叫 unshare 的命令,其实就是在调用 unshare() 系统调用。下面的 demo 使用 unshare 命令把当前进程的 user namespace 设置成了 root:
$ whoami
nick
$ unshare --map-root-user --user sh -c whoami
root
cgroups
简介
说实话,一些未知的软件应用可能需要被控制或限制——至少是为了稳定性或者某种程度上的安全性。很多时候,一个bug或者仅仅只是烂代码就有可能破坏掉整个机器甚至可能削弱整个生态。幸运的是,有一种方式可以控制应用程序,Linux控制组(cgroups)是一个内核功能,用于限制、记录和隔离一个或多个进程对CPU、内存、磁盘I/O 以及网络的访问及使用。
即,cgroups(Control Groups) 是 linux 内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups 可以限制、记录任务组所使用的物理资源。本质上来说,cgroups 是内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
控制组技术最初是由谷歌开发的,最终在2.6.24版本(2008年1月)中并入Linux内核主线。这项技术被部分重新设计,添加了kernfs(用于分割一些sysfs逻辑),这些改变被合并到3.15和3.16版本的内核中。
实现 cgroups 的主要目的是为不同用户层面的资源管理提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化(Linux 容器或者LXC),cgroups 提供了四大功能:
- 资源限制:一个控制组可以配置成不能超过指定的内存限制或是不能使用超过一定数量的处理器或限制使用特定的外围设备。
- 优先级:一个或者多个控制组可以配置成使用更少或者更多的CPU 时间片数量或者磁盘 IO 带宽,实际上就等同于控制了任务运行的优先级。
- 记录:一个控制组的资源使用情况会被监督以及测量。
- 控制:进程组可以被冻结,暂停或者重启。
概念
Task(任务) 在 linux 系统中,内核本身的调度和管理并不对进程和线程进行区分,只是根据 clone 时传入的参数的不同来从概念上区分进程和线程。这里使用 task 来表示系统的一个进程或线程。
Cgroup(控制组) cgroups 中的资源控制以 cgroup 为单位实现。Cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另一个 cgroup。
Subsystem(子系统) cgroups 中的子系统就是一个资源调度控制器(又叫 controllers)。比如 CPU 子系统可以控制 CPU 的时间分配,内存子系统可以限制内存的使用量。内核版本 4.10.0,支持的 subsystem 如下( cat /proc/cgroups):
- blkio 对块设备的 IO 进行限制。
- cpu 限制 CPU 时间片的分配,与 cpuacct 挂载在同一目录。
- cpuacct 生成 cgroup 中的任务占用 CPU 资源的报告,与 cpu 挂载在同一目录。
- cpuset 给 cgroup 中的任务分配独立的 CPU(多处理器系统) 和内存节点。
- devices 允许或禁止 cgroup 中的任务访问设备。
- freezer 暂停/恢复 cgroup 中的任务。
- hugetlb 限制使用的内存页数量。
- memory 对 cgroup 中的任务的可用内存进行限制,并自动生成资源占用报告。
- net_cls 使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器(tc 指令)可以识别来自特定 cgroup 任务的数据包,并进行网络限制。
- net_prio 允许基于 cgroup 设置网络流量(netowork traffic)的优先级。
- perf_event 允许使用 perf 工具来监控 cgroup。
- pids 限制任务的数量。
Hierarchy(层级) 层级有一系列 cgroup 以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。层级中的 cgroup 节点可以包含零个或多个子节点,子节点继承父节点挂载的子系统。一个操作系统中可以有多个层级。
接口
(以下为 Ubuntu 20.04,内核 5.13.0-30-generic)
cgroups 以文件的方式提供应用接口,我们可以通过 mount 命令来查看 cgroups 默认的挂载点:
$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755,inode64)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
...
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
第一行的 tmpfs 说明 /sys/fs/cgroup 目录下的文件都是存在于内存中的临时文件。
第二行的挂载点 /sys/fs/cgroup/systemd 用于 systemd 系统对 cgroups 的支持。
其余的挂载点则是内核支持的各个子系统的根级层级结构。
需要注意的是,在使用 systemd 系统的操作系统中,/sys/fs/cgroup 目录都是由 systemd 在系统启动的过程中挂载的,并且挂载为只读的类型。换句话说,系统是不建议我们在 /sys/fs/cgroup 目录下创建新的目录并挂载其它子系统的。这一点与之前的操作系统不太一样。
下面让我们来探索一下 /sys/fs/cgroup 目录及其子目录下都是些什么:
$ ls /sys/fs/cgroup
blkio cpu,cpuacct freezer misc net_prio rdma
cpu cpuset hugetlb net_cls perf_event systemd
cpuacct devices memory net_cls,net_prio pids unified
/sys/fs/cgroup 目录下是各个子系统的根目录。我们以 memory 子系统为例,看看 memory 目录下都有什么?
$ ls /sys/fs/cgroup/memory
cgroup.clone_children memory.memsw.limit_in_bytes
cgroup.event_control memory.memsw.max_usage_in_bytes
cgroup.procs memory.memsw.usage_in_bytes
cgroup.sane_behavior memory.move_charge_at_immigrate
memory.failcnt memory.numa_stat
memory.force_empty memory.oom_control
memory.kmem.failcnt memory.pressure_level
memory.kmem.limit_in_bytes memory.soft_limit_in_bytes
memory.kmem.max_usage_in_bytes memory.stat
memory.kmem.slabinfo memory.swappiness
memory.kmem.tcp.failcnt memory.usage_in_bytes
memory.kmem.tcp.limit_in_bytes memory.use_hierarchy
memory.kmem.tcp.max_usage_in_bytes notify_on_release
memory.kmem.tcp.usage_in_bytes release_agent
memory.kmem.usage_in_bytes system.slice
memory.limit_in_bytes tasks
memory.max_usage_in_bytes user.slice
memory.memsw.failcnt
这些文件就是 cgroups 的 memory 子系统中的根级设置。比如 memory.limit_in_bytes 中的数字用来限制进程的最大可用内存,memory.swappiness 中保存着使用 swap 的权重等等。
手动方法
你可以直接或者间接(通过LXC、libvirt或者Docker)访问及管理控制组,这里我首先介绍使用sysfs以及libgroups库。接下来的示例需要你预先安装一个必须的包。
sudo apt-get install libcgroup1 cgroup-tools
我将使用一个简单的shell脚本文件test.sh作为示例应用程序,它将会在无限while循环中运行以下两个命令。
$ cat test.sh
!/bin/shwhile [ 1 ]; do
echo "hello world"
sleep 60
done
安装必要的包后,你可以直接通过sysfs的目录结构来配置你的控制组,例如,要在内存子系统中创建一个叫做foo的控制组,只需要在/sys/fs/cgroup/memory底下新建一个叫做foo的目录:
sudo mkdir /sys/fs/cgroup/memory/foo
在我们使用 cgroups 时,最好不要直接在各个子系统的根目录下直接修改其配置文件。推荐的方式是为不同的需求在子系统树中定义不同的节点。
cgroups 的文件系统会在创建文件目录的时候自动创建配置文件:
$ ls /sys/fs/cgroup/memory/foo
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
memory.failcnt memory.memsw.usage_in_bytes
memory.force_empty memory.move_charge_at_immigrate
memory.kmem.failcnt memory.numa_stat
memory.kmem.limit_in_bytes memory.oom_control
memory.kmem.max_usage_in_bytes memory.pressure_level
memory.kmem.slabinfo memory.soft_limit_in_bytes
memory.kmem.tcp.failcnt memory.stat
memory.kmem.tcp.limit_in_bytes memory.swappiness
memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes
memory.kmem.tcp.usage_in_bytes memory.use_hierarchy
memory.kmem.usage_in_bytes notify_on_release
memory.limit_in_bytes tasks
memory.max_usage_in_bytes
默认情况下,每个新建的控制组将会继承对系统整个内存池的访问权限。但对于某些应用程序,这些程序拒绝释放已分配的内存并继续分配更多内存,这种默认继承方式显然不是个好主意。要使程序的内存限制变得更为合理,你需要更新文件memory.limit_in_bytes。
限制控制组foo下运行的任何应用的内存上限为50MB:
echo 50000000 | sudo tee /sys/fs/cgroup/memory/foo/memory.limit_in_bytes
验证设置:
$ sudo cat memory.limit_in_bytes
49999872
请注意,回读的值始终是内核页面大小的倍数(即4096字节或4KB)。这个值是内存的最小可分配大小。
启动应用程序test.sh:
sh ~/test.sh
使用进程ID(PID),将应用程序移动到内存控制器底下的控制组foo:
echo 2152 | sudo tee /sys/fs/cgroup/memory/foo/cgroup.procs
使用相同的PID,列出正在运行的进程并验证它是否在正确的控制组下运行:
$ ps -o cgroup 2152
CGROUP
5:devices:/user.slice,4:pids:/user.slice/user-1000.slice/user@1000.service,3:m...
或者通过 /proc/[pid]/cgroup 来查看指定进程属于哪些 cgroup:
$ cat /proc/2152/cgroup
13:cpuset:/
12:blkio:/
11:misc:/
10:rdma:/
9:freezer:/
8:cpu,cpuacct:/
7:perf_event:/
6:hugetlb:/
5:devices:/user.slice
4:pids:/user.slice/user-1000.slice/user@1000.service
3:memory:/foo #here
2:net_cls,net_prio:/
1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome\x2dsession\x2dmanager.slice/gnome-session-manager@ubuntu.service
0::/user.slice/user-1000.slice/user@1000.service/gnome\x2dsession\x2dmanager.slice/gnome-session-manager@ubuntu.service
每一行包含用冒号隔开的三列,他们的含义分别是:
- cgroup 树的 ID, 和 /proc/cgroups 文件中的 ID 一一对应。
- 和 cgroup 树绑定的所有 subsystem,多个 subsystem 之间用逗号隔开。这里 name=systemd 表示没有和任何 subsystem 绑定,只是给他起了个名字叫 systemd。
- 进程在 cgroup 树中的路径,即进程所属的 cgroup,这个路径是相对于挂载点的相对路径。
你还可以通过读取文件来监控控制组正在使用的资源。在这种情况下,你可以查看你的进程(以及生成的子进程)被分配的内存大小。
$ cat /sys/fs/cgroup/memory/foo/memory.usage_in_bytes
188416
当进程“迷路”时
现在让我们重新创建相同的场景,但这次我们将控制组foo的内存限制从50MB改为500 bytes:
echo 500 | sudo tee /sys/fs/cgroup/memory/foo/memory.limit_in_bytes
注意:如果任务超出其定义的限制,内核将进行干预,并在某些情况下终止该任务。
同样,当您重新读取值时,它将始终是内核页面大小的倍数。因此,虽然您将其设置为500字节,但它实际上被设置为4 KB:
$ cat /sys/fs/cgroup/memory/foo/memory.limit_in_bytes
4096
启动应用程序test.sh,将其移动到控制组下并监视系统日志:
$ sudo tail -f /var/log/messages
...
请注意,内核的Out-Of-Mempry Killer(也叫做oom-killer 内存不足杀手)在应用程序达到4KB限制时就会介入。它会杀死应用程序,应用程序将不再运行,你可以通过输入以下命令进行验证:
ps -o cgroup 2152
使用libcgroup
之前描述的许多早期步骤都可以通过libcgroup包中提供的管理工具进行简化。例如,使用cgcreate二进制文件的单个命令即可创建sysfs条目和文件。
输入以下命令即可在内存子系统下创建一个叫做foo的控制组:
sudo cgcreate -g memory:foo
注意:libcgroup提供了一种管理控制组中任务的机制。
使用与之前相同的方法,你就可以开始设置内存阈值:
echo 50000000 | sudo tee /sys/fs/cgroup/memory/foo/memory.limit_in_bytes
验证新配置的设置:
$ sudo cat memory.limit_in_bytes
50003968
使用cgexec二进制文件在控制组foo中运行应用程序:
sudo cgexec -g memory:foo ~/test.sh
使用它的进程ID - PID来验证应用程序是否在控制组和子系统(内存)下运行:
$ ps -o cgroup 2945
CGROUP
6:memory:/foo,1:name=systemd:/user.slice/user-0.slice/session-1.scope
如果您的应用程序不再运行,并且您想要清理并删除控制组,则可以使用二进制文件cgdelete来执行此操作。要从内存控制器下删除控制组foo,请输入:
sudo cgdelete memory:foo
持久组
您也可以通过一个简单的配置文件和服务的启动来完成上述所有操作。您可以在/etc/cgconfig.conf文件中定义所有控制组名称和属性。以下为foo组添加了一些属性:
$ cat /etc/cgconfig.conf
group foo {
cpu {
cpu.shares = 100;
}
memory {
memory.limit_in_bytes = 5000000;
}
}
cpu.shares选项定义了该组的CPU优先级。默认情况下,所有组都继承1024 shares(CPU share指的是控制组中的任务被分配到的CPU的 time的优先级,即值越大,分配到的CPU time越多,这个值需大于等于2),即100%的CPU time(CPU time是CPU用于处理一个程序所花费的时间)。通过将cpu.shares的值降低到更保守的值(如100),这个组将会被限制只能使用大概10%的CPU time。
就如之前讨论的,在控制组中运行的进程也可以被限制它能访问的CPUs(内核)的数量。将以下部分添加到同一个配置文件cgconfig.conf中组名底下。
cpuset {
cpuset.cpus="0-5";
}
有了这个限制,这个控制组会将应用程序绑定到到0核到5核——也就是说,它只能访问系统上的前6个CPU核。
接下来,您需要使用cgconfig服务加载此配置。首先,启用cgconfig以在系统启动时能够加载上述配置:
$ sudo systemctl enable cgconfig
Create symlink from /etc/systemd/system/sysinit.target.wants/cgconfig.service
to /usr/lib/systemd/system/cgconfig.service.
现在,启动cgconfig服务并手动加载相同的配置文件(或者您可以跳过此步骤直接重启系统):
sudo systemctl start cgconfig
在控制组foo下启动该应用程序并将其绑定到您设置的内存和CPU限制:
sudo cgexec -g memory,cpu,cpuset:foo ~/test.sh &
除了将应用程序启动到预定义的控制组之外,其余所有内容都将在系统重新启动后持续存在。但是,您可以通过定义依赖于cgconfig服务的启动初始脚本来启动该应用程序,自动执行该过程。
总结
通常来说,限制一个机器上一个或者多个任务的权限是必要的。控制组提供了这项功能,通过使用它,您可以对一些特别重要或无法控制的应用程序实施严格的硬件和软件限制。如果一个应用程序没有设置上限阈值或限制它可以在系统上消耗的内存量,cgroups可以解决这个问题。如果另一个应用程序没有CPU上的限制,那么cgroups可以再一次解决您的问题。您可以通过cgroup完成这么多工作,只需花一点时间,您就可以使用你的操作系统环境恢复稳定性,安全性和健全性。
使用 Systemd
当 Linux 的 init 系统发展到 systemd 之后,systemd 与 cgroups 发生了融合(或者说 systemd 提供了 cgroups 的使用和管理接口)。
Systemd 依赖 cgroups
要理解 systemd 与 cgroups 的关系,我们需要先区分 cgroups 的两个方面:层级结构(A)和资源控制(B)。首先 cgroups 是以层级结构组织并标识进程的一种方式,同时它也是在该层级结构上执行资源限制的一种方式。我们简单的把 cgroups 的层级结构称为 A,把 cgrpups 的资源控制能力称为 B。
对于 systemd 来说,A 是必须的,如果没有 A,systemd 将不能很好的工作。而 B 则是可选的,如果你不需要对资源进行控制,那么在编译 Linux 内核时完全可以去掉 B 相关的编译选项。
Systemd 默认挂载的 cgroups 系统
在系统的开机阶段,systemd 会把支持的 controllers (subsystem 子系统)挂载到默认的 /sys/fs/cgroup/ 目录下面,除了 systemd 目录外,其它目录都是对应的 subsystem。
/sys/fs/cgroup/systemd 目录是 systemd 维护的自己使用的非 subsystem 的 cgroups 层级结构。换句话说就是,并不允许其它的程序动这个目录下的内容。其实 /sys/fs/cgroup/systemd 目录对应的 cgroups 层级结构就是 systemd 用来使用 cgoups 中 feature A 的。
Cgroup 的默认层级
过将 cgroup 层级系统与 systemd unit 树绑定,systemd 可以把资源管理的设置从进程级别移至应用程序级别。因此,我们可以使用 systemctl 指令,或者通过修改 systemd unit 的配置文件来管理 unit 相关的资源。
默认情况下,systemd 会自动创建 slice、scope 和 service unit 的层级来为 cgroup 树提供统一的层级结构。
系统中运行的所有进程,都是 systemd init 进程的子进程。在资源管控方面,systemd 提供了三种 unit 类型:
- service: 一个或一组进程,由 systemd 依据 unit 配置文件启动。service 对指定进程进行封装,这样进程可以作为一个整体被启动或终止。
- scope:一组外部创建的进程。由进程通过 fork() 函数启动和终止、之后被 systemd 在运行时注册的进程,scope 会将其封装。例如:用户会话、 容器和虚拟机被认为是 scope。
- slice: 一组按层级排列的 unit。slice 并不包含进程,但会组建一个层级,并将 scope 和 service 都放置其中。真正的进程包含在 scope 或 service 中。在这一被划分层级的树中,每一个 slice 单位的名字对应通向层级中一个位置的路径。
以通过 systemd-cgls 命令来查看 cgroups 的层级结构
Control group /:
-.slice
├─419 bpfilter_umh
├─user.slice
│ ├─user-125.slice
│ │ ├─session-c1.scope
│ │ │ ├─1101 gdm-session-worker [pam/gdm-launch-environment]
│ │ │ ├─1158 /usr/lib/gdm3/gdm-x-session dbus-run-session -- gnome-session ->
│ │ │ ├─1160 /usr/lib/xorg/Xorg vt1 -displayfd 3 -auth /run/user/125/gdm/Xau>
│ │ │ ├─1347 dbus-run-session -- gnome-session --autostart /usr/share/gdm/gr>
│ │ │ ├─1348 dbus-daemon --nofork --print-address 4 --session
│ │ │ ├─1349 /usr/libexec/gnome-session-binary --systemd --autostart /usr/sh>
│ │ │ ├─1352 /usr/libexec/at-spi-bus-launcher
│ │ │ ├─1357 /usr/bin/dbus-daemon --config-file=/usr/share/defaults/at-spi2/>
│ │ │ ├─1378 /usr/bin/gnome-shell
│ │ │ ├─1432 ibus-daemon --panel disable --xim
│ │ │ ├─1435 /usr/libexec/ibus-dconf
│ │ │ ├─1438 /usr/libexec/ibus-x11 --kill-daemon
│ │ │ ├─1440 /usr/libexec/ibus-portal
│ │ │ ├─1451 /usr/libexec/at-spi2-registryd --use-gnome-session
service、scope 和 slice unit 被直接映射到 cgroup 树中的对象。当这些 unit 被激活时,它们会直接一一映射到由 unit 名建立的 cgroup 路径中。例如,cron.service 属于 system.slice,会直接映射到 cgroup system.slice/cron.service/ 中。 注意,所有的用户会话、虚拟机和容器进程会被自动放置在一个单独的 scope 单元中。
默认情况下,系统会创建四种 slice:
- -.slice:根 slice
- system.slice:所有系统 service 的默认位置
- user.slice:所有用户会话的默认位置
- machine.slice:所有虚拟机和 Linux 容器的默认位置
创建临时的 cgroup
对资源管理的设置可以是 transient(临时的),也可以是 persistent (永久的)。我们先来介绍如何创建临时的 cgroup。
需要使用 systemd-run 命令创建临时的 cgroup,它可以创建并启动临时的 service 或 scope unit,并在此 unit 中运行程序。systemd-run 命令默认创建 service 类型的 unit,比如我们创建名称为 toptest 的 service 运行 top 命令:
sudo systemd-run --unit=toptest --slice=test top -b
然后查看一下 test.slice 的状态:
sudo systemctl status test.slice
创建了一个 test.slice/toptest.service cgroup 层级关系。再看看 toptest.service 的状态:
sudo systemctl status toptest.service
top 命令被包装成一个 service 运行在后台了!
接下来我们就可以通过 systemctl 命令来限制 toptest.service 的资源了。在限制前让我们先来看一看 top 进程的 cgroup 信息:
cat /proc/2850/cgroup
比如我们限制 toptest.service 的 CPUShares 为 600,可用内存的上限为 550M:
sudo systemctl set-property toptest.service CPUShares=600 MemoryLimit=500M
再次检查 top 进程的 cgroup 信息:
cat /proc/2850/cgroup
在 CPU 和 memory 子系统中都出现了 toptest.service 的名字。同时去查看 /sys/fs/cgroup/memory/test.slice 和 /sys/fs/cgroup/cpu/test.slice 目录,这两个目录下都多出了一个 toptest.service 目录。我们设置的 CPUShares=600 MemoryLimit=500M 被分别写入了这些目录下的对应文件中。
临时 cgroup 的特征是,所包含的进程一旦结束,临时 cgroup 就会被自动释放。比如我们 kill 掉 top 进程,然后再查看 /sys/fs/cgroup/memory/test.slice 和 /sys/fs/cgroup/cpu/test.slice 目录,刚才的 toptest.service 目录已经不见了。
通过配置文件修改 cgroup
所有被 systemd 监管的 persistent cgroup(持久的 cgroup)都在 /usr/lib/systemd/system/ 目录中有一个 unit 配置文件。比如我们常见的 service 类型 unit 的配置文件。我们可以通过设置 unit 配置文件来控制应用程序的资源,persistent cgroup 的特点是即便系统重启,相关配置也会被保留。需要注意的是,scope unit 不能以此方式创建。下面让我们为 cron.service 添加 CPU 和内存相关的一些限制,编辑 /lib/systemd/system/cron.service 文件:
$ sudo vim /lib/systemd/system/cron.service
[Service]
CPUShares=600
MemoryLimit=500M
EnviromentFile=-/etc/default/cron
ExecStart=/usr/sbin/cron -f $EXTRA_OPTS
IgnoreSIGPIPE=false
KillMode=process
然后重新加载配置文件并重启 cron.service:
sudo systemctl daemon-reload
sudo systemctl restart cron.service
现在去查看 /sys/fs/cgroup/memory/system.slice/cron.service/memory.limit_in_bytes 和 /sys/fs/cgroup/cpu/system.slice/cron.service/cpu.shares 文件,是不是已经包含我们配置的内容了!
通过 systemctl 命令修改 cgroup
除了编辑 unit 的配置文件,还可以通过 systemctl set-property 命令来修改 cgroup,这种方式修该的配置也会在重启系统时保存下来。现在我们把 cron.service 的 CPUShares 改为 700:
sudo systemctl set-property cron.service CPUShares=700
查看 /sys/fs/cgroup/cpu/system.slice/cron.service/cpu.shares 文件的内容应该是 700,重启系统后该文件的内容还是 700。
Systemd-cgtop 命令
类似于 top 命令,systemd-cgtop 命令显示 cgoups 的实时资源消耗情况。
通过它我们就可以分析应用使用资源的情况。
LXC
LXC(Linux容器,Linux Container)相当于你运行了一个接近于裸机的虚拟机。这项技术始于2008年,LXC的大部分功能来自于Solaris容器(又叫做Solaries Zones)以及之前的FreeBSD jails技术。 LXC并不是创建一个成熟的虚拟机,而是创建了一个拥有自己进程程和网络空间的虚拟环境,使用命名空间来强制进程隔离并利用内核的控制组(cgroups)功能,该功能可以限制,计算和隔离一个或多个进程的CPU,内存,磁盘I / O和网络使用情况。 您可以将这种用户空间框架想像成是chroot的高级形式。
chroot是一个改变当前运行进程以及其子进程的根目录的操作。一个运行在这种环境的程序无法访问根目录外的文件和命令。
注意:LXC使用命名空间来强制进程隔离,同时利用内核的控制组来计算以及限制一个或多个进程的CPU,内存,磁盘I / O和网络使用。
但容器究竟是什么?简短的答案是容器将软件应用程序与操作系统分离,为用户提供干净且最小的Linux环境,与此同时在一个或多个隔离的“容器”中运行其他所有内容。容器的目的是启动一组有限数量的应用程序或服务(通常称为微服务),并使它们在独立的沙盒环境中运行。
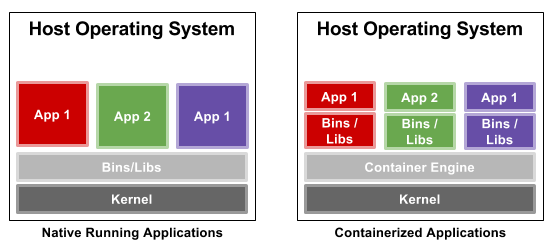
这种隔离可防止在给定容器内运行的进程监视或影响在另一个容器中运行的进程。此外,这些集装箱化服务不会影响或干扰主机。能够将分散在多个物理服务器上的许多服务合并为一个的想法是数据中心选择采用该技术的众多原因之一。
容器有以下几个特点:
- 安全性:容器里可以运行网络服务,这可以限制安全漏洞或违规行为造成的损害。那些成功利用那个容器的一个或多个应用的安全漏洞的入侵者将会被限制在只能在那个容器中做一些操作。
- 隔离性:容器允许在同一物理机器上部署一个或多个应用程序,即使这些应用程序必须在不同的域下运行,每个域都需要独占访问其各自的资源。例如,通过将每个容器关联的不同IP地址,在不同容器中运行的多个应用程序可以绑定到同一物理网络接口。
- 虚拟化和透明性:容器为系统提供虚拟化环境,这个环境可以隐藏或限制系统底层的物理设备或系统配置的可见性。容器背后的一般原则是避免更改运行应用程序的环境,但解决安全性或隔离问题除外。
使用LXC的工具
对于大多数现代Linux发行版,内核都启用了控制组,但您很可能仍需要安装LXC工具。
对于Ubuntu或Debian,只需键入:
sudo apt-get install lxc
现在,在开始使用这些工具之前,您需要配置您的环境。在此之前,您需要验证当前用户是否同时在/etc/subuid和/etc/subgid中定义了uid和gid:
$ cat /etc/subuid
petros:100000:65536
$ cat /etc/subgid
petros:100000:65536
如果~/.config/lxc不存在,则创建该目录,并且把配置文件/etc/lxc/default.conf复制到~/.config/lxc/default.conf.,将以下两行添加到文件末尾:
lxc.id_map = u 0 100000 65536
lxc.id_map = g 0 100000 65536
结果如下:
$ cat ~/.config/lxc/default.conf
lxc.network.type = veth
lxc.network.link = lxcbr0
lxc.network.flags = up
lxc.network.hwaddr = 00:16:3e:xx:xx:xx
lxc.id_map = u 0 100000 65536
lxc.id_map = g 0 100000 65536
将以下命令添加到/etc/lxc/lxc-usernet文件末尾(把第一列换成你的username):
petros veth lxcbr0 10
最快使这些配置生效的方法是重启或者将用户登出再登入。
重新登录后,请验证当前是否已加载veth网络驱动程序:
$ lsmod | grep veth
veth 16384 0
如果没有,请输入:
sudo modprobe veth
现在您可以使用LXC工具集来下载,运行,管理Linux容器。
接下来,下载容器镜像并将其命名为“example-container”。当您键入以下命令时,您将看到一长串许多Linux发行版和版本支持的容器:
sudo lxc-create -t download -n example-container
将会有三个弹出框让您分别选择发行版名称(distribution),版本号(release)以及架构(architecture)。请选择以下三个选项:
Distribution: ubuntu
Release: xenial
Architecture: amd64
选择后点击Enter,rootfs将在本地下载并配置。出于安全原因,每个容器不附带OpenSSH服务器或用户帐户。同时也不会提供默认的root密码。要更改root密码并登录,必须在容器目录路径中运行lxc-attach或chroot(在启动之后)。
启动容器:
sudo lxc-start -n example-container -d
-d选项表示隐藏容器,它会在后台运行。如果您想要观察boot的过程,只需要将-d换成-F。那么它将在前台运行,登录框出现时结束。
你可能会遇到如下错误:
$ sudo lxc-start -n example-container -d
lxc-start: tools/lxc_start.c: main: 366 The container
failed to start.
lxc-start: tools/lxc_start.c: main: 368 To get more details,
run the container in foreground mode.
lxc-start: tools/lxc_start.c: main: 370 Additional information
can be obtained by setting the --logfile and --logpriority
options.
如果你遇到了,您需要通过在前台运行lxc-start服务来调试它:
$ sudo lxc-start -n example-container -F
lxc-start: conf.c: instantiate_veth: 2685 failed to create veth
pair (vethQ4NS0B and vethJMHON2): Operation not supported
lxc-start: conf.c: lxc_create_network: 3029 failed to
create netdev
lxc-start: start.c: lxc_spawn: 1103 Failed to create
the network.
lxc-start: start.c: __lxc_start: 1358 Failed to spawn
container "example-container".
lxc-start: tools/lxc_start.c: main: 366 The container failed
to start.
lxc-start: tools/lxc_start.c: main: 370 Additional information
can be obtained by setting the --logfile and --logpriority
options.
从以上示例,你可以看到模块veth没有被引入,在引入之后,将会解决这个问题。
之后,打开第二个terminal窗口,验证容器的状态。
$ sudo lxc-info -n example-container
Name: example-container
State: RUNNING
PID: 1356
IP: 10.0.3.28
CPU use: 0.29 seconds
BlkIO use: 16.80 MiB
Memory use: 29.02 MiB
KMem use: 0 bytes
Link: vethPRK7YU
TX bytes: 1.34 KiB
RX bytes: 2.09 KiB
Total bytes: 3.43 KiB
也可以通过另一种方式来查看所有安装的容器,运行命令:
$ sudo lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6
example-container RUNNING 0 - 10.0.3.28 -
但是问题是你仍然不能登录进去,你只需要直接attach到正在运行的容器,创建你的用户,使用passwd命令改变相关的密码。
$ sudo lxc-attach -n example-container
root@example-container:/#
root@example-container:/# useradd petros
root@example-container:/# passwd petros
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
更改密码后,您将能够从控制台直接登录到容器,而无需使用lxc-attach命令:
sudo lxc-console -n example-container
如果要通过网络连接到此运行容器,请安装OpenSSH服务器:
# apt-get install openssh-server
抓取容器的本地IP地址:
# ip addr show eth0|grep inet
inet 10.0.3.25/24 brd 10.0.3.255 scope global eth0
inet6 fe80::216:3eff:fed8:53b4/64 scope link
然后在主机的新的控制台窗口中键入:
ssh 10.0.3.25
瞧!您现在可以SSH到正在运行的容器并键入您的用户名和密码。
在主机系统上,而不是在容器内,可以观察在启动容器后启动和运行的LXC进程:
$ ps aux | grep lxc | grep -v grep
...
要停止容器,请键入(在主机):
sudo lxc-stop -n example-container
停止后,验证容器的状态:
$ sudo lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6
example-container STOPPED 0 - - -
$ sudo lxc-info -n example-container
Name: example-container
State: STOPPED
要彻底销毁容器 - 即从主机system—type清除它:
$ sudo lxc-destroy -n example-container
Destroyed container example-container
销毁后,可以验证是否已将其删除:
$ sudo lxc-info -n example-container
example-container doesn't exist
$ sudo lxc-ls -f
注意:如果您尝试销毁正在运行的容器,该命令将失败并告知您容器仍在运行:
$ sudo lxc-destroy -n example-container
example-container is running
在销毁容器前必须先停止它。
高级配置
有时,可能需要配置一个或多个容器来完成一个或多个任务。 LXC通过让管理员修改位于/var/lib/lxc中的容器配置文件来简化这一过程:
$ sudo su
# cd /var/lib/lxc
# ls
example-container
容器的父目录将包含至少两个文件:1)容器配置文件和 2)容器的整个rootfs:
# cd example-container/
# ls
config rootfs
假设您想要在主机系统启动时自动启动名称为example-container的容器。那么您需要将以下行添加到容器的配置文件/var/lib/lxc/example-container/config的尾部:
# Enable autostart
lxc.start.auto = 1
重新启动容器或重新启动主机系统后,您应该看到如下内容:
$ sudo lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6
example-container RUNNING 1 - 10.0.3.25 -
注意 AUTOSTART 字段现在被设置为“1”。
如果在容器启动时,您希望容器绑定装载主机上的目录路径,请将以下行添加到同一文件的尾部:
# 将挂载系统路径绑定到本地路径
lxc.mount.entry = /mnt mnt none bind 0 0
通过上面的示例,当容器重新启动时,您将看到容器本地的 / mnt目录可访问的主机/ mnt目录的内容。
特权与非特权容器
您经常会发现在与LXC相关的内容中讨论特权容器和非特权容器的概念。但它们究竟是什么呢?这个概念非常简单,并且LXC容器可以在任一配置下运行。
根据设计,无特权容器被认为比特权容器更安全,更保密。无特权容器运行时,容器的root UID映射到主机系统上的非root UID。这使得攻击者即使破解了容器,也难以获得对底层主机的root权限。简而言之,如果攻击者设法通过已知的软件漏洞破坏了您的容器,他们会立即发现自己无法获取任何主机权限。
特权容器可能使系统暴露于此类攻击。这就是为什么我们最好在特权模式下运行尽量少的容器。确定需要特权访问的容器,并确保付出额外的努力来定期更新并以其他方式锁定它们。
然而,Docker又是什么呢?
我花了相当多的时间谈论Linux容器,但是Docker呢?它是生产中部署最多的容器解决方案。自首次推出以来,Docker已经风靡Linux计算世界。 Docker是一种Apache许可的开源容器化技术,旨在自动化在容器内创建和部署微服务这类重复性任务。 Docker将容器视为非常轻量级和模块化的虚拟机。最初,Docker是在LXC之上构建的,但它已经远离了这种依赖,从而带来了更好的开发人员和用户体验。与LXC非常相似,Docker继续使用内核cgroup子系统。该技术不仅仅是运行容器,还简化了创建容器,构建映像,共享构建的映像以及对其进行版本控制的过程。
Docker主要关注于:
- 可移植性:Docker提供基于镜像的部署模型。这种类型的可移植性允许更简单的方式在多个环境中共享应用程序或服务集合(以及它们的所有依赖)。
- 版本控制:单个Docker镜像由一系列组合层组成。每当镜像被更改时,都会创建一个新层。例如,每次用户指定命令(例如运行或复制)时,都会创建一个新层。 Docker将重用这些层用于新的容器构建。分层到Docker是它自己的版本控制方法。
- 回滚:再次,每个Docker镜像都有很多层。如果您不想使用当前运行的层,则可以回滚到以前的版本。这种敏捷性使软件开发人员可以更轻松地持续集成和部署他们的软件技术。
- 快速部署:配置新硬件通常需要数天时间。并且,安装和配置它的工作量和开销是非常繁重的。使用Docker,您可以在几秒钟将镜像启动并运行,相比于之前,节省了大量的时间。当你使用完一个容器时,你可以轻松地销毁它。
从本质上说,Docker和LXC都非常相似。它们都是用户空间和轻量级虚拟化平台,它们利用cgroup和命名空间来管理资源隔离。但是,两者之间也存在许多明显的差异。
进程管理
Docker将容器限制为单个进程运行。如果您的应用程序包含X个并发进程,Docker将要求您运行X个容器,每个容器都有自己单独的进程。 LXC不是这样,LXC运行具有传统init进程的容器,反过来,可以在同一容器内托管多个进程。例如,如果要托管LAMP(Linux + Apache + MySQL + PHP)服务器,每个应用程序的每个进程都需要跨越多个Docker容器。
状态管理
Docker被设计为无状态,意味着它不支持持久存储。有很多方法可以解决这个问题,但同样,只有在进程需要时才需要它。创建Docker镜像时,它将包含只读层。这不会改变。在运行时,如果容器的进程对其内部状态进行任何更改,则将保持内部状态和镜像的当前状态之间的差异,直到对Docker镜像进行提交(创建新层)或直到容器被删除,差异也会消失。
可移植性
在讨论Docker时,这个词往往被过度使用——因为它是Docker相对于LXC的最重要的优势。 Docker从应用程序中抽象出网络,存储和操作系统细节方面做得更好。这样就形成了一个真正独立于配置的应用程序,保证应用程序的环境始终保持不变,无论启用它的机器配置环境如何。
Docker旨在使开发人员和系统管理员都受益。它已成为许多DevOps(开发人员+维护人员)工具链中不可或缺的一部分。开发人员可以专注于编写代码,而无需担心最终托管它的系统是什么。使用Docker,无需安装和配置复杂数据库,也无需担心在不兼容的语言工具链版本之间切换。 Docker为维护人员提供了更多的灵活性,通常可以减少托管一些较小和更基本的应用程序所需的物理系统数量。 Docker简化了软件交付。新功能和错误/安全修复程序可以快速到达客户,无需任何麻烦,意外或停机。
总结
为了基础设施安全性和系统稳定性而隔离进程并不像听起来那么痛苦。 Linux内核提供了所有必要的工具,使简单易用的用户空间应用程序【如LXC(甚至Docker)】能够在隔离的沙盒环境中管理操作系统的微实例及其本地服务。
沙箱
在计算机安全领域,沙箱(Sandbox)是一种程序的隔离运行机制,其目的是限制不可信进程的权限。沙箱技术经常被用于执行未经测试的或不可信的客户程序。为了避免不可信程序可能破坏其它程序的运行,沙箱技术通过为不可信客户程序提供虚拟化的磁盘、内存以及网络资源,而这种虚拟化手段对客户程序来说是透明的。由于沙箱里的资源被虚拟化(或被间接化),所以沙箱里的不可信程序的恶意行为往往会被限制在沙箱中。
沙箱技术一直是系统安全领域的挑战,不存在说哪一种方案是足够安全的。沙箱技术方案通常是需要结合多种系统安全技术来实现,采用防御纵深(Defence in Depth)的设计原则,筑建多道防御屏障,尽可能地将安全风险将为最低。下面我们主要讨论如何利用Linux kernel所提供的安全功能来建立有效的沙箱技术。
在讨论之前,我们简单回顾一下Linux安全模型相关的内容(假设读者已经非常熟悉):
(1) 每个进程都有自己的地址空间;
(2) MMU硬件机制来保证地址空间的隔离;
(3) Kernel是系统的TCB(Trusted Computing Base),是安全策略的制定者和执行者;
(4) 进程是最小的权限边界;
(5) root具有最高权限,它能控制一切;
(6) 其它用户受DAC(Discretionary Access Control)限制,如文件系统的UGO权限控制。
进程是最小的权限边界,其根本原因是MMU能保证进程地址空间的隔离。
Linux Kernel还提供了与进程降权(drop privilege)相关的一些功能:
- setuid
- POSIX.1e capability
- chroot jail
- Quota control (eg, cgroup, namespace)
- Linux Container
- Linux Security Module (LSM)
下面我们会介绍如何在实践中利用这些诀窍来构建一个有效的sandbox.
Sandboxing
systemd-nspawn
中文手册
入门笔记
🗓️ 2021/02/05
介绍
systemd-nspawn是一个类似chroot一样的命令,用来启动一个容器,但是有比chroot更加强大的功能,能够完全虚拟化文件系统、进程树等系统,同时对于容器的网络接口、资源占用进行限制。
systemd-nspawn与docker类似,但又存在一些不同点,这些不同点主要是因为软件设计运行的场景不一样。Docker容器更加注重颗粒化的管理,容器作为最基本的单位,每个容器只运行单一的进程,并且由多个容器组成一个运用,比如如果要通过Docker运行WordPress,还需要配置一个MariaDB或是MySQL容器,这样的架构方便进行集群和批量管理,能弹性的扩展资源,更适合在云计算平台上使用。
相对Docker而言,systemd-nspawn的一些特点,让我觉得在一些场景上,systemd-nspawn更适合个人/单机使用:
systemd-nspawn启动一个容器则会完整的启动整个系统,可以把依赖的服务都集中到一个容器里面systemd-nspawn是systemd自带组件,而systemd目前作为主流发行版的默认init进程,基本上所有Linux发行版都会自带- 容器内到容器外的无缝对接,使用
systemctl加上参数--machine就可以控制容器内的服务,journalctl也支持查看容器内服务的日志 systemd-nspawn可以直接使用现在的文件系统作为容器的rootfs启动,不同于Docker的copy-on-write,这点看似比较傻瓜,却比较实用,特别是个人非常折腾的时候。
配置
容器的配置非常的简单,只要保证容器rootfs存在,就可以启动容器,Debian系容器使用工具debootstrap下载,Arch对应使用pacstrap安装,由于容器与主机共享内核,容器内部不需要安装内核和内核模块。
| 容器名称 | myContainer |
|---|---|
| 服务单元 | systemd-nspawn@myContainer.service |
| 容器根目录 | /var/lib/machines/myContainer |
| 配置文件 | /etc/systemd/nspawn/myContainer.nspawn |
容器内部包括常见设定,包括root密码、时区、主机名等可以使用systemd-nspawn -D root启动(忽略-b参数)跳过登录过程启动容器,之后进行配置。容器本身运行环境、资源限制则通过.nspawn配置完成,主要的配置包括文件系统还有网络配置。
用户空间隔离
--private-users参数用于隔离用户空间文件的uid/gid,如果不设定这个参数,默认是打开的,即运行时候容器内和容器外,文件拥有者不一样,具体表现为容器内的uid/gid在实际文件系统中会添加一段偏移,容器外可以控制容器内文件,但是如果直接拷贝文件到容器里面,容器内运行的进程是没有读写权限的。
如果启用了--private-users参数,原有文件依旧会保持原有uid/gid,只有在容器内发生读写的时候,产生新的文件才会映射到新的拥有者,通过开启--private-users-chown参数,强行迫使原有文件全部映射到新的用户和用户组。同理,也可以反向操作,将发生偏移的容器内的文件,全部修改回正常的uid/gid
私有网络配置
--private-network参数对应配置文件[Network]下的Private,启用这个参数之后,宿主机网络和容器网络将隔离开,只能通过NAT或是桥接方式通讯,设置--network-interface、--network-macvlan、--network-ipvlan、--network-veth都会间接开启私有网络。
--network-interface 参数指定一个网络给容器,这个参数不是共享网卡,而是直接从宿主机中移除这个网卡,并添加到容器中,在停用容器之后才会返回这个网卡。参数对应配置文件中[Network]Interface。注意:不能直接把无线网卡分配给容器,如果要分配无线网卡给容器,无线网卡必须支持命名空间。
--network-macvlan/--network-ipvlan,相当于桥接,网卡的前缀是mv-/iv-,macvlan是同个网卡不同MAC地址,ipvlan是同个MAC地址不同IP地址。这两个方法都有一个缺点,那就是无法直接于宿主机通讯,即使处于同一个网段下面。
--network-veth,在主机和容器之间创建一个虚拟网卡,网卡前缀是ve-,--network-bridge把主机上的桥接网卡映射到容器里面,不能直接指定主机上的物理网卡,必须在主机端建立bridge之后,把这个bridge分配给容器,这个参数会间接启用--network-veth。
其他的网络相关参数还有 --network-zone=或是--port,用于批量管理容器网络,后者用于暴露端口到主机,不过都是在开启私有网络并且配置完整的时候可以启用,具体可以去看手册。
要禁用私有网络,设定参数--network-veth=no/--private-network=no或是在配置文件里面添加:
[Network]
Private=no
VirtualEthernet=no
这样子容器于主机共享网络接口。
资源限定
限定容器能占用资源有时候也是非常重要的,这一部分可以参考systemd资源控制
systemctl set-property systemd-nspawn@container-name.service MemoryMax=2G
systemctl set-property systemd-nspawn@container-name.service CPUQuota=200%
容器管理
容器管理使用命令machinectl,但是实际上也是等同systemctl对应的命令
machinectl |
systemctl |
说明 |
|---|---|---|
machinectl list |
systemctl list-machines |
列出正在运行的容器 |
machinectl login name |
连接到容器控制台 | |
machinectl status name |
systemctl status systemd-nspawn@name |
查看容器运行状态 |
machinectl start name |
systemctl start systemd-nspawn@name |
启动容器 |
machinectl poweroff name |
systemctl stop systemd-nspawn@name |
关闭容器 |
machinectl reboot name |
systemctl restart systemd-nspawn@name |
重启容器 |
machinectl terminate name |
强行停止容器,在容器没有反应的时候使用 | |
machinectl enable name |
systemctl enable systemd-nspawn@name |
开机自启 |
machinectl disable name |
systemctl disable systemd-nspawn@name |
禁用自启 |
nspawn.org
A hub for systemd-nspawn containers and images.
nspawn.org 目前提供了 Arch、CentOS、Debian、Fedora、Ubuntu 的各版本镜像,并可以直接用 systemd-nspawn 的验证机制进行签名验证。
推荐的用法是使用其提供的 “nspawn” 工具。下面以创建一个 Fedora 30 容器为例:
-
获取工具:
wget https://raw.githubusercontent.com/nspawn/nspawn/master/nspawn chmod +x nspawn -
获取 Fedora 30 镜像:
sudo ./nspawn init fedora/30/tar -
启动容器并获取 shell:
$ sudo machinectl start fedora-30-tar $ sudo machinectl shell fedora-30-tar Connected to machine fedora-30-tar. Press ^] three times within 1s to exit session. [root@fedora30 ~]#
一些背景:容器默认的存储路径在 /var/lib/machines/。nspawn.org 的创建者是 shibumi,目前是 Arch Linux Trusted User。所有的镜像使用 mkosi 制作,定义文件均在 GitHub 上。除了 nspawn 容器镜像,这个站点还提供可引导的 GPT-UEFI 镜像。
Bubblewrap
使用 bwrap 沙盒
bwrap 是命令的名字。这个项目的名字叫 bubblewrap。它是一个使用 Linux 命名空间的非特权沙盒(有用户命名空间支持的话)。
我之前使用过 Gentoo 的 sandbox 工具。它是 Gentoo 用于打包的工具,使用的是 LD_PRELOAD 机制,所以并不可靠。主要用途也就是避免打包软件的时候不小心污染到用户家目录。
使用 bwrap 的话,限制是强制的,没那么容易绕过(至于像 Go 这种因为不使用 libc 而意外绕过就更难得了)。不过 bwrap 不会在触发限制的时候报错。
bwrap 的原理是,把 / 放到一个 tmpfs 上,然后需要允许访问的目录通过 bind mount 弄进来。所以没弄进来的部分就是不存在,写数据的话就存在内存里,用完就扔掉了。这一点和 systemd 也不一样——systemd 会把不允许的地方挂载一个没权限访问的目录过去。
bwrap 的挂载分为只读和可写挂载。默认是 nodev 的,所以在里边是不能挂载硬盘设备啥的。它也提供最简 /proc 和 /dev,需要手动指定。整个 / 都是通过命令行来一点点填充内容的,所以很容易漏掉部分内容(比如需要联网的时候忘记挂载 resolv.conf 或者 TLS 证书),而不会不小心允许不应当允许访问的地方(当然前提是不偷懒直接把外面的 / 挂载过去啦)。
至于别的命名空间,有 --unshare-all 选项,不用写一堆了。如果需要网络,就加个 --share-net(这个选项文档里没写)。没有别的网络方案,因为没特权,不能对网络接口进行各种操作。--die-with-parent 可以保证不会有残留进程一直跑着。
我目前的打包命令长这样:
alias makepkg='bwrap --unshare-all --share-net --die-with-parent \
--ro-bind /usr /usr --ro-bind /etc /etc --proc /proc --dev /dev \
--symlink usr/bin /bin --symlink usr/bin /sbin --symlink usr/lib /lib --symlink usr/lib /lib64 \
--bind $PWD /build/${PWD:t} --ro-bind /var/lib/pacman /var/lib/pacman --ro-bind ~/.ccache ~/.ccache \
--bind ~/.cache/ccache ~/.cache/ccache --chdir /build/${PWD:t} /usr/bin/makepkg'
以后应该随着问题的出现还会修改的。
其实我学 bwrap 主要不是自己打包啦(毕竟基本上都交给 lilac 了),而是给 lilac 加固。Arch 的打包脚本是 shell 脚本,所以很多时候不执行脚本就没办法获取一些信息、进行某些操作。唉,这些发行版都喜欢糙快猛的风格,然后在上边打各种补丁。deb 和 rpm 的打包也都是基于 shell 脚本的。而 lilac 经常通过脚本编辑打包脚本,或者从 AUR 取,万一出点事情,把不该删的东西给删掉了,或者把私钥给上传了,就不好了。所以前些天我给 lilac 执行 PKGBUILD 的地方全部加上了 bwrap。期间还发现 makepkg --printsrcinfo 不就是读取 PKGBUILD 然后打印点信息嘛,竟然不断要求读取 install 脚本,还要对打包目录可写……
另一个用法是,跑不那么干净的软件。有些软件不得不用,又害怕它在自己家里拉屎,就可以让它在沙盒里放肆了。比如使用反斜杠作为文件路径分隔符写一堆奇怪文件名的 WPS Office。再比如不确定软件会不会到处拉屎,所以事先确认一下。我以前使用的是基于 systemd-nspawn 和 overlayfs 的方案(改进自基于 aufs 和 lxc 的方案所以名字没改),不过显然 bwrap 更轻量一些。跑 GUI 的话,我用的命令长这样:
bwrap --unshare-all --die-with-parent --ro-bind / / \
--tmpfs /sys --tmpfs /home --tmpfs /tmp --tmpfs /run --proc /proc --dev /dev \
--ro-bind ~/.fonts ~/.fonts --ro-bind ~/.config/fontconfig ~/.config/fontconfig \
--bind ~/.cache/fontconfig ~/.cache/fontconfig --ro-bind ~/.Xauthority ~/.Xauthority \
--ro-bind /tmp/.X11-unix /tmp/.X11-unix --ro-bind /run/user/$UID/bus /run/user/$UID/bus \
--chdir ~ /bin/bash
其实还可以用来给别的发行版编译东西,取代我之前使用 systemd-nspawn 的方案。bwrap 在命令行上指定如何挂载,倒是十分方便灵活,很适合这种需要共享工作目录的情况呢。以后有需要的时候我再试试看。(好像一般人都是使用 docker / podman 的,但是我喜欢使用自己建立和维护的 rootfs,便于开发和调试,也更安全。)
和 bwrap 类似的工具还有 SELinux 和 AppArmor。它们是作用于整个系统的,Arch Linux 安装会很麻烦,对于我的需求也过于复杂。Firejail 是面向应用程序的,但是配置起来也挺不容易。bwrap 更偏重于提供底层功能而不是完整的解决方案,具体用法可以让用户自由发挥。
aur-apps
#!/bin/bash
#
# aur-apps,利用 bwrap 沙盒让 ubuntu 能用 aur 和 archlinuxcn 源安装软件运行
#
AUR_DIR="${AUR_DIR:-$HOME/.local/lib/aur-apps/}"
AUR_CACHE_DIR="${ARCH_DIR:-$AUR_DIR/cache/}"
AUR_APP_DATA_DIR="${ARCH_DIR:-$AUR_DIR/data/}"
ARCH_DIR="${ARCH_DIR:-$AUR_DIR/root.x86_64/}"
ARCH_IMAGE_MIRROR="${ARCH_IMAGE_MIRROR:-http://mirrors.163.com/archlinux/iso/latest/}"
#MIRRORLIST='https://mirrors.163.com/archlinux/$repo/os/$arch'
#ARCHLINUXCN='https://mirrors.163.com/archlinux-cn/$arch'
MIRRORLIST='http://mirrors.aliyun.com/archlinux/$repo/os/$arch'
ARCHLINUXCN='https://mirrors.aliyun.com/archlinuxcn/$arch'
AUR_DESKTOP_FILES_DIR="$HOME/.local/share/applications/aur-apps/"
APT_AUR='#!/bin/bash
# fix the poorly designed pacman/yay command
list()(
set -x
yay -Sl "$@"
)
search()(
set -x
yay -Ss "$@"
)
show()(
set -x
yay -Si "$@"
)
showfiles()(
set -x
yay -Fl "$@" || yay -Ql "$@"
)
install()(
set -x
yay -S "$@"
)
remove()(
set -x
yay -Rns "$@"
)
update()(
set -x
yay -Sy "$@" && yay -Fy "$@"
)
upgrade()(
set -x
yay -Syua "$@" && yay -Fy "$@"
)
upgradeable()(
set -x
yay -Pu
)
files()(
set -x
yay -F "$@"
)
autoclean()(
set -x
yay -Yc
)
status()(
set -x
yay -Ps
)
help(){
echo commands:
declare -F | grep -oP ' [a-z]+.*' | sort
}
if [ "$(type -t $1)" = function ] ; then
"$@"
else
help
fi
'
## initialize
init(){
[ ! -e /usr/bin/bwrap ] && echo "+ sudo apt install bwrap" && sudo apt install bubblewrap
mkdir -p "$AUR_DIR"
mkdir -p "$AUR_CACHE_DIR/pacman/pkg/"
mkdir -p "$AUR_CACHE_DIR/_cache/"
mkdir -p "$AUR_APP_DATA_DIR"
mkdir -p "$ARCH_DIR/$HOME/.cache"
cd "$AUR_DIR"
image_name=$(_wget_arch_image)
test -n "$image_name" || { echo "can not download the archlinux-bootstrap image file, exit." ; exit 1 ; }
# root.x86_64
tar xvf "$image_name"
# setup pacman
echo "Server = $MIRRORLIST" >> root.x86_64/etc/pacman.d/mirrorlist
echo -e "\n[archlinuxcn]\nServer = $ARCHLINUXCN" >> root.x86_64/etc/pacman.conf
echo -e "\n[multilib]\nInclude = /etc/pacman.d/mirrorlist" >> root.x86_64/etc/pacman.conf
# fix the poorly designed pacman/run yay command
echo "$APT_AUR" > root.x86_64/usr/local/bin/apt-aur
chmod +x root.x86_64/usr/local/bin/apt-aur
# use snapctl xdg-open
echo -e '#!/bin/sh
test -a /usr/bin/snapctl && exec snapctl user-open "$@" || exec /usr/bin/xdg-open "$@" ' > root.x86_64/usr/local/bin/xdg-open
chmod +x root.x86_64/usr/local/bin/xdg-open
# init arch
# init locale
echo zh_CN.UTF-8 UTF-8 >> root.x86_64/etc/locale.gen
bwrap_root locale-gen
# fix makepkg, pacman with bwrap
sed -i 's/^CheckSpace/##CheckSpace/' root.x86_64/etc/pacman.conf
_fix_files
# add user
bwrap_root useradd -u $(id -u) "$USER"
# setup pacman
bwrap_root pacman-key --init
bwrap_root pacman-key --populate archlinux
bwrap_root pacman -Sy
bwrap_root pacman -Fy
bwrap_root pacman --noconfirm -S fakeroot which
bwrap_root cp /usr/bin/fakeroot /usr/local/bin/sudo # use fakeroot as sudo
echo "+ sudo arch-chroot"
arch_chroot pacman --noconfirm -S archlinuxcn-keyring ; sudo chown -R $USER: "$ARCH_DIR"
# makepkg expect base-devel
#bwrap_root pacman --noconfirm -S base-devel git make patch yay xdg-desktop-portal-kde xdg-desktop-portal-gtk extra/breeze-gtk extra/noto-fonts-cjk
bwrap_root pacman --noconfirm -S base-devel git make patch yay xdg-desktop-portal-gtk extra/breeze-gtk fcitx fcitx-qt5 fcitx-qt6
##
cd -
}
# fix files
_fix_files(){
grep -q 'EUID == 0' "$ARCH_DIR/usr/bin/makepkg" &&
sed -i 's/EUID == 0/EUID == 1/' "$ARCH_DIR/usr/bin/makepkg"
}
# like apt list
list(){
bwrap_user yay -Sl "$@"
}
# like apt search
search(){
bwrap_user yay -Ss "$@"
}
# like apt show
show(){
bwrap_user yay -Si "$@"
}
# like apt-file list or dpkg -L
showfiles(){
bwrap_user yay -Fl "$@" || bwrap_user yay -Ql "$@"
}
# like apt install
install(){
_fix_files
bwrap_user yay -S "$@" && update_desktop_menu
}
# like apt remove
remove(){
_fix_files
bwrap_user yay -Rns "$@" && update_desktop_menu
}
# like apt update
update(){
bwrap_user yay -Sy "$@" && bwrap_root yay -Fy "$@"
}
# like apt upgrade
upgrade(){
_fix_files
bwrap_user yay -Syua "$@" && bwrap_root yay -Fy "$@"
}
# apt list --upgradable
upgradeable(){
bwrap_user yay -Pu
}
# like apt-file search
files(){
bwrap_user yay -F "$@"
}
# like apt autoclean
autoclean(){
_fix_files
bwrap_root yay -Yc
}
# like apt policy
status(){
bwrap_user yay -Ps
}
# download archlinux-bootstrap image
_wget_arch_image()(
image_name=$(wget -O- "$ARCH_IMAGE_MIRROR" | grep -m 1 -oP 'archlinux-bootstrap-20.*?x86_64\.tar\.gz' | head -1)
wget -c "$ARCH_IMAGE_MIRROR/$image_name" && echo $image_name
)
# gen .menu file
_gen_desktop_file_menu_file(){
DIR=$(basename $AUR_DESKTOP_FILES_DIR)
echo '<!DOCTYPE Menu PUBLIC "-//freedesktop//DTD Menu 1.0//EN"
"http://www.freedesktop.org/standards/menu-spec/menu-1.0.dtd">
<!-- Do not edit manually - generated and managed by xdg-desktop-menu -->
<Menu>
<Name>Applications</Name>
<Menu>
<Name>aur-apps</Name>
<Directory>aur-apps.directory</Directory>
<Include>'
ls "$AUR_DESKTOP_FILES_DIR" | while read fn ; do
echo " <Filename>$DIR-$fn</Filename>"
done
echo ' </Include>
</Menu>
</Menu>'
}
# update start menu
update_desktop_menu(){
mkdir -p "$AUR_DESKTOP_FILES_DIR"
ln -s "$ARCH_DIR/usr/share/pixmaps/"* ~/.local/share/pixmaps/ 2>/dev/null
rm "$AUR_DESKTOP_FILES_DIR"/*
cp "$ARCH_DIR/usr/share/applications/"* "$AUR_DESKTOP_FILES_DIR"
sed -i 's/Exec=/Exec=aur-apps run /' "$AUR_DESKTOP_FILES_DIR/"*
echo '[Desktop Entry]
Version=1.0
Type=Directory
Name=Aur Apps
Icon=applications-multimedia' > ~/.local/share/desktop-directories/aur-apps.directory
_gen_desktop_file_menu_file > ~/.config/menus/applications-merged/aur-apps.menu
xdg-desktop-menu forceupdate
xdg-icon-resource forceupdate
}
_get_bind_try_args()(
quote ()
{
local quoted=${1//\'/\'\\\'\'};
printf '%s' "$quoted"
}
# --bind-try args
{
for i in DESKTOP DOWNLOAD TEMPLATES PUBLICSHARE DOCUMENTS MUSIC PICTURES VIDEOS ; do xdg-user-dir $i ; done
} | while read i
do
bind_try=$(quote "$i")
echo -n " --bind $bind_try $bind_try "
done
)
# fix environment variable
_fix_env(){
}
# run command
run(){
bwrap_user "$@"
}
# user bwrap
bwrap_user()(
if [ ! -e "$ARCH_DIR/usr/bin/pacman" ] ; then
echo "aur for ubuntu was not initialized, please run init"
read -e -p "would you like to initialize now? [Y/n] " ret
[ "$ret" = y -o "$ret" = Y ] || exit 1
init
fi
#xdg_open_file=$(ls /snap/core/*/usr/bin/xdg-open | head -1)
bind_try_args=`_get_bind_try_args`
[ "$1" = which ] || set -x
bwrap --bind "$ARCH_DIR" / \
--bind-try "$AUR_APP_DATA_DIR" "$HOME" \
--bind-try "$AUR_CACHE_DIR/pacman/pkg/" /var/cache/pacman/pkg/ \
--bind-try "$AUR_CACHE_DIR/_cache/" "$HOME/.cache" \
$bind_try_args \
--ro-bind /etc/resolv.conf /etc/resolv.conf --ro-bind /etc/hosts /etc/hosts \
--dev-bind /dev /dev --dev-bind /proc /proc --dev-bind /sys /sys --bind /tmp /tmp --dev-bind /run /run \
--ro-bind-try /usr/share/fonts/opentype/noto/ /usr/share/fonts/noto \
--ro-bind-try /usr/bin/snapctl /usr/bin/snapctl \
--ro-bind-try /usr/share/themes/Yaru /usr/share/themes/Yaru \
--share-net --die-with-parent "${@:-bash}"
)
# fakeroot bwrap
#bwrap_fakeroot(){
# bwrap_user fakeroot "$@"
#}
# root bwrap
bwrap_root()(
set -x
bwrap --bind "$ARCH_DIR" / \
--bind-try "$AUR_APP_DATA_DIR" "$HOME" \
--bind-try "$AUR_CACHE_DIR/pacman/pkg/" /var/cache/pacman/pkg/ \
--bind-try "$AUR_CACHE_DIR/_cache/" "$HOME/.cache" \
--ro-bind /etc/resolv.conf /etc/resolv.conf --ro-bind /etc/hosts /etc/hosts \
--dev-bind /dev /dev --dev-bind /proc /proc --dev-bind /sys /sys --bind /tmp /tmp --dev-bind /run /run \
--ro-bind-try /usr/share/fonts/opentype/noto/ /usr/share/fonts/noto \
--ro-bind-try /usr/bin/snapctl /usr/bin/snapctl \
--ro-bind-try /usr/share/themes/Yaru /usr/share/themes/Yaru \
--share-net --die-with-parent --uid 0 --gid 0 --unshare-user "${@:-bash}"
)
# sudo arch-chroot
arch_chroot()(
set -x
sudo "$ARCH_DIR/usr/bin/arch-chroot" "$ARCH_DIR" "$@"
)
# list commands
help(){
echo commands:
declare -F | grep -oP ' [a-z]+.*' | sort
}
# interactive cmd
_cmd_main()(
_fix_env
if [ -n "$1" ] ; then
if [ "$(type -t $1)" = function ] ; then
"$@"
exit
elif bwrap_user which "$1" ; then
bwrap_user "$@"
exit
else
echo "command not found."
help
exit
fi
fi
while read -e -p 'aur> ' CMD ; do
if [ "$CMD" = q -o "$CMD" = quit ] ; then
exit
elif [ "$(type -t ${CMD/ */})" = function ] ; then
$CMD
elif bwrap_user which "${CMD/ */}" ; then
bwrap_user $CMD
continue
else
echo "command not found."
help
fi
done
)
_cmd_main "$@"
权限
ugo
Linux 系统中文件的 ugo 权限是 Linux 进行权限管理的基本方式。
所有者和组
Linux 文件的 ugo 权限把对文件的访问者划分为三个类别:文件的所有者、组和其他人。所谓的 ugo 就是指 user(也称为 owner)、group 和 other 三个单词的首字母组合。
用户和组的信息分别记录在 /etc/passwd、/etc/group 文件中,这两个文件的内容是任何人都有权查看的,可以直接以读取文本文件的方式查看其内容,其中的每一行代表一个用户。
文件的所有者
文件的所有者一般是创建该文件的用户,对该文件具有完全的权限。在一台允许多个用户访问的 Linux 主机上,可以通过文件的所有者来区分一个文件属于某个用户。当然,一个用户也无权查看或更改其它用户的文件。
文件所属的组
假如有几个用户合作开发同一个项目,如果每个用户只能查看和修改自己创建的文件就太不方便了,也就谈不上什么合作了。所以需要一个机制允许一个用户查看和修改其它用户的文件,此时就用到组的概念的。我们可以创建一个组,然后把需要合作的用户都添加都这个组中。在设置文件的访问权限时,允许这个组中的用户对该文件进行读取和修改。
其他人
如果我想把一个文件共享给系统中的所有用户该怎么办?通过组的方式显然是不合适的,因为需要把系统中的所有用户都添加到一个组中。并且系统中添加了新用户该怎么办,每添加一个新用户就把他添加到这个组中吗?这个问题可以通过其他人的概念解决。在设置文件的访问权限时,允许其他人户对该文件进行读取和修改。
文件属性
使用 ll 命令可以查看文件的属性信息:
$ ll Desktop
drwxr-xr-x 2 nick nick 4.0K Mar 2 15:06 Desktop
- drwxr-xr-x 指明文件的类型和 ugo 权限信息。
- 2 是对文件的引用计数。
- nick 是文件的所有者,文件的所有者一般是创建该文件的用户,对该文件具有完全的权限。
- nick 是文件所属的组,我们通过 adduser 命令创建用户时一般会创建一个同名的组,该用户就属于与他同名的组(比如笔者机器上的用户 nick 就属于 nick 组)。当我们创建文件和目录时,其默认所属的组就是所有者所在的组。
其它的信息我们暂时忽略。
文件类型
drwxr-xr-x 的第一个字符描述文件的类型,常见的类型有如下几种:
- d 表示目录
- - 表示普通文件
- l 表示链接文件
- b 表示块设备文件
- c 表示字符设备文件
- s 表示 socket 文件
ugo 权限信息
10 个字符,除去第一个表示文件类型的字符,其它 9 个字符表示文件的 ugo 权限信息
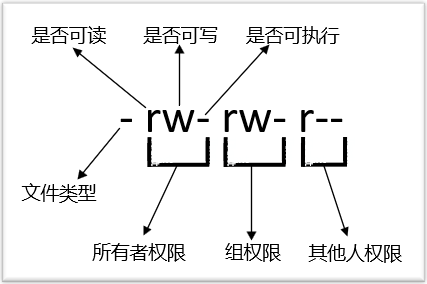
这 9 个字符以三个为一组,都是 rwx 或 - 的组合。其中,r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)。 这三个权限的位置不会改变,如果没有对应的权限,就会以 -(减号)代替。
*第一组为文件所有者的权限,第二组为文件所属组的权限,第三组为其他人的权限。*其表示的具体含义为:文件所有者具有对文件的读写权限,文件所属组的用户具有对文件读写的权限,而其他人只有读取文件的权限。
下面详细的解释一下文件读写执行的权限:
- r (read):可以读取文件的实际内容,比如读取文本文件内的文字等。
- w (write):可以编辑、增加、删除文件的内容(但不含删除该文件)。
- x (execute):该文件具有可以被系统执行的权限。
可以看出,对于文件来说,rwx 主要针对的是文件的内容。
对目录而言,目录中存储的主要是目录下文件名称的列表,这与普通文件是有些不同的:
- r (read contents in directory) 表示具有读取目录下文件名称的权限,也就是说你可以通过 ls 命令把目录下的文件列表查询出来。
- w (modify contents of directory) 具有 w 权限表明你可以在该目录下执行如下的操作:
- 创建新的文件和目录
- 删除已经存在的文件与目录(不论该文件的权限为何!)
- 重命名已存在的文件或目录
- 移动该目录内文件、目录的位置
- x (access directory) 目录虽然不能被执行,但是却具有可以执行的权限。目录的 x 权限表示用户是否可以进入该目标并成为当前的工作目录。注意,如果用户对目录没有 x 权限,则无法查看该目录下的文件的内容(注意与 r 权限的区别)。
综上,如果要允许目录被其他人浏览时,至少要给予 r 和 x 的权限。
改变权限
在新建文件时会根据创建者的身份和其它的一些设置为文件生成默认的权限。
接下来我们介绍如何通过命令修改文件权限相关的信息。
改变文件所有者
通过 chown 命令可以改变文件的所有者:
sudo chown tester testfile
改变文件所属的组
通过 chgrp 命令可以改变文件所属的组:
sudo chgrp tester testfile
改变文件的权限
通过 chmod 命令可以改变文件的权限。对于文件的 rwx 权限,有两种表示方法,数字表示法和字符表示法。
以数字表示权限的方式如下:
- r: 4
- w: 2
- x: 1
如果是 rwx 权限就是 4 + 2 + 1 = 7 ,r-x 就是 4 + 1 = 5 ,— 则为 0。所以 rw-rw-r– 就可以用 664 来表示。如果我们想把文件的权限修改为 rwxrwxrwx,可以使用下面的命令:
chmod 777 testfile
以字符表示权限的方式如下:用字符 u, g, o 分别代表文件所有者(user)、文件所属的组(group)和其他人(other),这就是 ugo 权限叫法的由来。只不过还有一个 a 可以表示全部的身份(all)。具体更改权限的语法如下:
chmod [ugoa][+-=][rwx] 文件/目录
比如我们可以通过下面的命令把 testfile 的权限设为 rw-rw-r–:
chmod ug=rw,o=r testfile
如果想去掉组的 w 权限并给其他人添加 x 权限可以执行下面的命令:
chmod g-w,o+x testfile
我们还可通过 a 为全部身份设置权限,比如 rwx:
chmod a=rwx testfile
特殊权限
setuid 和 setgid 分别是 set uid ID upon execution 和 set group ID upon execution 的缩写。我们一般会再次把它们缩写为 suid 和 sgid。它们是控制文件访问的权限标志(flag),它们分别允许用户以可执行文件的 owner 或 owner group 的权限运行可执行文件。
SUID
在 Linux 中,所有账号的密码记录在 /etc/shadow 这个文件中,并且只有 root 可以读写入这个文件:
$ ll /etc/shadow
-rw-r----- 1 root shadow 1.5K Feb 25 12:46 /etc/shadow
如果另一个普通账号 tester 需要修改自己的密码,就要访问 /etc/shadow 这个文件。但是明明只有 root 才能访问 /etc/shadow 这个文件,这究竟是如何做到的呢?事实上,tester 用户是可以修改 /etc/shadow 这个文件内的密码的,就是通过 SUID 的功能。让我们看看 passwd 程序文件的权限信息:
$ ll /usr/bin/passwd
-rwsr-xr-x 1 root root 67K Jul 15 2021 /usr/bin/passwd
上图红框中的权限信息有些奇怪,owner 的信息为 rws 而不是 rwx。当 s 出现在文件拥有者的 x 权限上时,就被称为 SETUID BITS 或 SETUID ,其特点如下:
- SUID 权限仅对二进制可执行文件有效
- 如果执行者对于该二进制可执行文件具有 x 的权限,执行者将具有该文件的所有者的权限
- 本权限仅在执行该二进制可执行文件的过程中有效
下面我们来看 tester 用户是如何利用 SUID 权限完成密码修改的:
- tester 用户对于 /usr/bin/passwd 这个程序具有执行权限,因此可以执行 passwd 程序
- passwd 程序的所有者为 root
- tester 用户执行 passwd 程序的过程中会暂时获得 root 权限
- 因此 tester 用户在执行 passwd 程序的过程中可以修改 /etc/shadow 文件
但是如果由 tester 用户执行 cat 命令去读取 /etc/shadow 文件确是不行的:
$ ll /bin/cat
-rwxr-xr-x 1 root root 43K Sep 5 2019 /bin/cat
原因很清楚,tester 用户没有读 /etc/shadow 文件的权限,同时 cat 程序也没有被设置 SUID。我们可以通过下图来理解这两种情况:
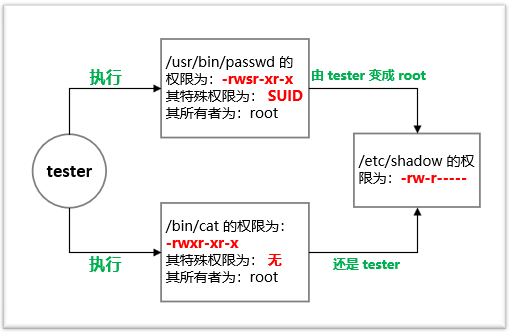
SGID
当 s 标志出现在用户组的 x 权限时称为 SGID。SGID 的特点与 SUID 相同,我们通过 /usr/bin/mlocate 程序来演示其用法。mlocate 程序通过查询数据库文件 /var/lib/mlocate/mlocate.db 实现快速的文件查找。 mlocate 程序的权限如下图所示:
$ ll /usr/bin/mlocate
-rwxr-sr-x 1 root mlocate 39520 Nov 18 2014 /usr/bin/mlocate*
很明显,它被设置了 SGID 权限。下面是数据库文件 /var/lib/mlocate/mlocate.db 的权限信息:
$ ll /var/lib/mlocate/mlocate.db
-rw-r----- 1 root mlocate 12101109 Aug 13 07:35 /var/lib/mlocate/mlocate.db
普通用户 tester 执行 mlocate 命令时,tester 就会获得用户组 mlocate 的执行权限,又由于用户组 mlocate 对 mlocate.db 具有读权限,所以 tester 就可以读取 mlocate.db 了。程序的执行过程如下图所示:

除二进制程序外,SGID 也可以用在目录上。当一个目录设置了 SGID 权限后,它具有如下功能:
- 用户若对此目录具有 r 和 x 权限,该用户能够进入该目录
- 用户在此目录下的有效用户组将变成该目录的用户组
- 若用户在此目录下拥有 w 权限,则用户所创建的新文件的用户组与该目录的用户组相同
SBIT
其实 SBIT 与 SUID 和 SGID 的关系并不大。SBIT 是 the restricted deletion flag or sticky bit 的简称。
SBIT 目前只对目录有效,用来阻止非文件的所有者删除文件。比较常见的例子就是 /tmp 目录:
$ ls -ld /tmp
drwxrwxrwt 22 root root 4096 Mar 2 20:57 /tmp
权限信息中最后一位 t 表明该目录被设置了 SBIT 权限。SBIT 对目录的作用是:当用户在该目录下创建新文件或目录时,仅有自己和 root 才有权力删除。
设置权限
以数字的方式设置权限
SUID、SGID、SBIT 权限对应的数字如下:
SUID->4
SGID->2
SBIT->1
所以如果要为一个文件权限为 “-rwxr-xr-x” 的文件设置 SUID 权限,需要在原先的 755 前面加上 4,也就是 4755:
chmod 4755 filename
同样,可以用 2 和 1 来设置 SGID 和 SBIT 权限。设置完成后分别会用 s, s, t 代替文件权限中的 x。
其实,还可能出现 S 和 T 的情况。s 和 t 是替代 x 这个权限的,但是,如果它本身没有 x 这个权限,添加 SUID、SGID、SBIT 权限后就会显示为大写 S 或大写 T。比如我们为一个权限为 666 的文件添加 SUID、SGID、SBIT 权限:
$ chmod 666 nickfile
$ ll nickfile
-rw-rw-rw- 1 nick nick 0 Mar 2 21:03 nickfile
$ chmod 7666 nickfile
$ ll nickfile
-rwSrwSrwT 1 nick nick 0 Mar 2 21:03 nickfile
通过符号类型改变权限
除了使用数字来修改权限,还可以使用符号:
chmod u+s testfile # 为 testfile 文件加上 SUID 权限。
chmod g+s testdir # 为 testdir 目录加上 SGID 权限。
chmod o+t testdir # 为 testdir 目录加上 SBIT 权限。
umask
默认权限
为了查看用户创建的文件和目录的默认权限,我们用一个普通的用户创建文件 myfile 和目录 mydir 并查看它们的默认权限:
$ touch myfile
$ mkdir mydir
$ ll
total 4.0K
drwxrwxr-x 2 nick nick 4.0K Mar 2 21:09 mydir
-rw-rw-r-- 1 nick nick 0 Mar 2 21:09 myfile
目录的权限为 775,文件的权限为 664。默认情况下对于目录来说最大的权限是 777,对于文件来说最大的权限一般为 666(只有可以执行的文件才添加可执行权限)。所以我们创建的文件和目录的共同特点是从最大权限中减其他用户的写权限。而这个被减去的值就是我们常说的 umask。umask 还是 bash 的一个内置命令,默认输出当前用户的 umask 值:
$ umask
002
注意,umask 显示的值为从默认的最大权限中减去的值。
默认策略
系统在用户登录时通过 login 程序调用 pam_umask 模块设置用户默认的 umask。从 login 程序的配置文件 /etc/login.defs 中我们可以找到 umask 相关的配置:
...
UMASK 022
...
USERGROUPS_ENAB yes
...
用户的默认 umask 应该是 022,但当 USERGROUPS_ENAB 被设置为 yes 时(默认值),对于 uid 和 gid 相同且用户名和主组名相同的用户,系统会把其 umask 改为 002。
于 root 用户的特殊性,它默认的 umask 与其它用户是不同的,其值为 022:
# umask
0022
第一个 0 表示 8 进制,这里我们可以暂时忽略它。
命令
umask 是 bash 的一个内置命令,用来显示或设置新建文件/目录的权限掩码(umask)。前面我们以数字的方式输出了用户默认的 umask 值,这次我们以符号的方式进行输出:
$ umask -S
u=rwx,g=rwx,o=rx
以符号输出的就是用户创建目录时的默认权限,也就是 775。
为了改变用户创建的文件/目录的默认值,我们可以改变 umask 的默认值。
设置 umask 值
最简单的方式就是为 umask 命令指定一个数字:
umask 026
026 的含义为:去掉 group 中的写权限,去掉 other 中的读写权限。
这时创建的文件权限为 640,目录权限为 751。注意,修改 umask 后只有新建的文件和目录受影响,已经存在的文件和目录的权限不会被影响。
以符号的方式设置 umask 值
比如下面的命令:
umask u=,g=w,o=rwx
上面的命令表示从 group 中去掉写权限,从 other 中去掉读写执行的权限。
注意:"=" 号在 umask 命令和 chmod 命令中的作用恰恰相反。在 chmod 命令中,利用它来设置指定的权限,而其余权限则被删除。但是在 umask 命令中,将在原有权限的基础上删除指定的权限。
在 ~/.bashrc 文件中为用户设置默认的 umask
如果让用户每次登陆后都执行 umask 命令修改默认的 umask 值是不科学的,我们可以在用户的 ~/.bashrc 文件中执行 umask 命令,这样用户登录后 umask 的值自动就变成了设置的值。把下面的命令添加到 ~/.bashrc 文件的最后一行:
umask 026
与 ACL
如果一个目录没有被设置 default ACL,那么将由 umask 决定新文件的 ACL 权限。这种情况其实就是我们常见的没有 ACL 权限时的情况。比如我们设置 umask 为 026,那么创建的文件和目录的权限就是由它决定的。
如果一个目录被设置了 default ACL,那么将会由文件创建函数的 mode 参数和目录的 default ACL 共通决定新文件的 ACL 权限,此时 umask 被忽略。还以 umask 026 为例,我们创建一个目录 dir2 并设置 default ACL 权限:
$ setfacl -m d:u:tester:rwx dir2
$ getfacl dir2
# file: dir2
# owner: nick
# group: nick
user::rwx
group::r-x
other::--x
default:user::rwx
default:user:tester:rwx
default:group::rwx
default😷:rwx
default:other::r-x
然后在 dir2 目录中创建文件 testfile:
$ dir2 touch testfile
$ dir2 ll testfile
-rw-rw-r--+ 1 nick nick 0 Mar 2 21:26 testfile
这次 testfile 的权限已经不受 umask 的影响了!
ACL
ACL的全称是 Access Control List (访问控制列表) ,一个针对文件/目录的访问控制列表。它在UGO权限管理的基础上为文件系统提供一个额外的、更灵活的权限管理机制。它被设计为UNIX文件权限管理的一个补充。ACL允许你给任何特定的用户或用户组设置任何文件/目录的访问权限。
ACL需要Linux内核和文件系统的配合才能工作,大多数Linux发行版本默认都是支持的。但最好还是能够先检查一下:
$ sudo tune2fs -l /dev/sda1 | grep "Default mount options:"
Default mount options: user_xattr acl
设置权限
可以使用setfacl和getfacl命令来设置或观察文件/目录的acl权限。
当前用户是 nick,再创建两个用户 tester 和 tester1 用来进行测试:
sudo adduser tester
创建文件 aclfile,检查其默认的权限信息:
$ touch aclfile
$ ll aclfile
-rw-rw-r-- 1 nick nick 0 Mar 2 21:40 aclfile
$ getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
group::rw-
other::r--
把用户切换为 tester,发现没有写文件的权限:
$ echo "hello" >> aclfile
bash: aclfile: Permission denied
这是因为 other 没有写 aclfile 文件的权限。
下面我们为 tester 用户赋予读写 aclfile 文件的权限:
setfacl -m u:tester:rw aclfile
修改成功后再次以 tester 用户的身份向 aclfile 文件写入数据,这次已经可以正常写入了。查看 aclfile 文件的权限:
$ getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
user:tester:rw-
group::rw-
mask::rw-
other::r--
多出了一些信息,其中比较重要的是 user:tester:rw-,就是它让用户 tester 具有了读写 aclfile 的权限。
针对用户组来设置权限和针对用户的设置几乎一样,只是把小写的 u 换成小写的 g 就行了。
继承权限
acl 能让创建的子文件或者子文件夹继承父文件夹的权限设置!
$ mkdir mydir
$ ll -d mydir
drwxrwxr-x 2 nick nick 4.0K Mar 2 21:09 mydir
$ setfacl -m d:u:tester:rwx mydir
$ getfacl mydir
# file: mydir
# owner: nick
# group: nick
user::rwx
group::rwx
other::r-x
default:user::rwx
default:user:tester:rwx
default:group::rwx
default😷:rwx
default:other::r-x
这次多出了一些以 default 开头的行,这些 default 权限信息只能在目录上设置,然后会被目录中创建的文件和目录继承。下面分别在 mydir 目录下创建文件 testfile 和目录 testdir,并查看它们的 acl 权限:
$ touch testfile
$ mkdir testdir
$ getfacl testfile
# file: testfile
# owner: nick
# group: nick
user::rw-
user:tester:rwx
group::rwx
mask::rw-
other::r--
从上面可以看到文件 testfile 继承了父目录的 acl 权限,因此用户 tester 对它有读写权限。下面再看看 testdir 目录:
$ getfacl testdir
# file: testdir
# owner: nick
# group: nick
user::rwx
user:nick:rwx
group::rwx
mask::rwx
other::r-x
default:user::rwx
default:user:tester:rwx
default:group::rwx
default😷:rwx
default:other::r-x
从图中可以看出,testdir 目录不仅继承了 tester 的访问权限,还继承了父目录上的 default 权限。也就是说我们通过这种方式设置在目录上的权限可以被子目录递归的继承下去。
操作权限
更改
-m 选项其实是在更改文件和目录的 ACL 权限
- 当一个用户或组的 ACL 权限不存在时,-m 选项执行的是添加操作,
- 如果一个用户或组的 ACL 权限已经存在时,-m 选项执行的是更新操作。
setfacl -m u:tester:rwx aclfile
setfacl -m u:tester:rw aclfile
-set 选项会先清除掉原有的 ACL 权限,然后添加新的权限
$ setfacl --set u::rw,u:tester:rwx,g::r,o::- aclfile
$ getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
user:tester:rwx
group::r--
mask::rwx
other::---
需要注意的是一定要包含 UGO 权限的设置,不能象 -m 一样只包含 ACL 权限。o::- 是另一个需要注意的地方,其完整的写法是 other::-,就像 u::rw 的完整写法是 user::rw- 一样。通常我们可以把 “-” 省略,但是当权限位只包含 “-” 时,就至少要保留一个。如果写成了o::,就会报错。
删除
通过 setfacl 命令的 -x 选项来删除指定用户或组的 ACL 权限,还可以通过 -b 选项来清除文件和目录上所有的 ACL 权限。
下面通过 -x 选项删除 user tester 的 ACL 权限,注意命令中只指定了用户的名称而没有指定权限信息:
$ getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
user:tester:rwx
group::rw-
mask::rwx
other::r--
$ setfacl -x u:tester aclfile
$ getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
group::rw-
mask::rw-
other::r--
下面通过 -b 选项一次性删除 aclfile 上所有的 ACL 权限:
$ setfacl -b aclfile
getfacl aclfile
# file: aclfile
# owner: nick
# group: nick
user::rw-
group::rw-
other::r--
备份和恢复
常见的文件操作命令 cp 和 mv 等都支持 ACL 权限,只是 cp 命令需要加上 -p 参数。但是 tar 等常见的备份工具不会保留目录和文件的 ACL 权限信息。如果希望备份和恢复带有 ACL 权限的文件和目录,可以先把 ACL 权限信息备份到一个文件里,然后再用 -restore 选项来恢复这些信息。
使用下面的命令导出 acldir 目录的 ACL 权限信息并保存到文件 acldir.acl 文件中:
getfacl -R acldir > acldir.acl
通过下面的命令把它们的 ACL 权限都恢复回来:
setfacl --restore acldir.acl
实现原理
ACL 条目

进程权限
ugo 权限信息是文件的属性,它指明了用户与文件之间的关系。但是真正操作文件的却是进程,也就是说用户所拥有的文件访问权限是通过进程来体现的。
概念:
-
用户 对于支持多任务的 Linux 系统来说,用户就是获取资源的凭证。
-
权限 权限用来控制用户对计算机资源(CPU、内存、文件等)的访问,一般会分为认证和授权两步。比如用户先经过认证机制(authentication)登录系统,然后由授权系统(authorization)对用户的操作进行授权。
-
进程 进程是任何支持多道程序设计的操作系统中的基本概念。通常把进程定义为
程序执行时的一个实例。因此,如果有 10 个用户同时运行 vi,就会有 10 个独立的进程(尽管它们共享同一份可执行代码)。实际上,是进程在帮助我们完成各种任务。进程就是用户访问计算机资源的代理,用户执行的操作其实是带有用户身份信息的进程执行的操作。
-
进程权限 既然是进程在为用户执行具体的操作,那么当用户要访问系统的资源时就必须给进程赋予权限。也就是说进程必须携带发起这个进程的用户的身份信息才能够进行合法的操作。
登陆过程
在 Linux 系统启动后,init 系统会 fork 出子进程执行 /sbin/getty 程序等待用户登录。当用户进行登录操作时,该子进程通过 exec 函数开始执行 /bin/login 程序(此时该进程已经变成了 login 进程)。由 login 进程验证我们的用户名和密码并查询 /etc/passwd 和 /etc/shadow 确定其合法性。如果是合法的用户,该进程再次通过 exec 函数执行用户的默认 shell 程序,此时的 login 进程就变成了 shell 进程(笔者机器上是 bash 进程)。并且**该 shell 进程的有效身份被设置成为该用户的身份,之后 fork 此 shell 进程的子进程都会继承该有效身份。**我们可以通过下图来理解用户从 tty 登录系统的过程:
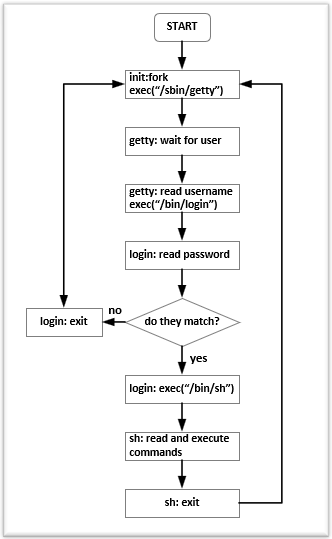
简单点说就是:用户登录后, shell 进程的有效用户就是该用户。
user id
通过 cat /proc/<PID>/status 命令,我们可以查看到进程所属的用户和组相关的信息:
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
通过 man proc 可以查询到第一行的四个数字分别是 real user id, effective user id, saved set user id 和 filesystem UID,第二行则是对应的组 ID。
real user id
real user id 是执行进程者的 user id,一般情况下就是用户登录时的 user id。子进程的 real user id 从父进继承。通常这个是不更改的,也不需要更改。比如我以用户 nick 登录 Linux 系统,我接下来运行的所有命令的进程的 real user id 都是 nick 的 user id。
effective user id
如果要判断一个进程是否对某个文件有操作权限,验证的是进程的 effective user id,而不是 real user id。
通常不建议直接使用 root 用户进行操作的,但是在很多情况下,程序可能需要特殊的权限。比如 passwd 程序需要 root 权限才能够为普通用户修改密码,一些 services 程序的操作也经常需要特殊的权限。为此,Linux 中设计了一些特殊的权限(SUID/SGID/SBIT)。这里我们以 passwd 程序为例,为二进制可执行文件 /usr/bin/passwd 设置 set-user-id bit=ON,这个可执行文件被用 exec 启动之后的进程的 effective user id 就是这个可执行文件的 owner id,而并非父进程的 real user id。如果 set-user-id bit=OFF 的时候,这个被 exec 起来的进程的 effective user id 应该是等于进程的 user id 的。
其实我们通过 ps aux 查看的结果中,第一列显示的就是进程的 effective user。
saved set user id
saved set user id 相当于是一个 buffer,在 exec 函数启动之后,它会拷贝 effective user id 位的信息覆盖自己。
对于非 root 用户来说,可以在未来使用 setuid() 函数将 effective user id 设置成为 real user id 或 saved set user id 中的任何一个。但是不允许非 root 用户用 setuid() 函数把 effective user id 设置成为任何第三个 user id。
对于 root 用户来说,调用 setuid() 的时候,将会设置所有的这三个 user id。
外部命令
在 shell 中执行的命令分为内部命令和外部命令两种。
- 内部命令:内建的,相当于 shell 的子函数
- 外部命令:在文件系统的某个路径下的一个可执行文件
外部命令的执行过程如下:
- Shell 通过 fork() 函数建立一个新的子进程,新的子进程为当前 shell 进程的一个副本。
- 在新的进程里,从 PATH 变量所列出的目录中寻找指定的命令程序。当命令名称包含有斜杠(/)符号时,将略过路径查找步骤。
- 在新的进程里,通过 exec 系列函数,以所找到的新程序替换 shell 程序并执行。
- 子进程退出后,最初的 shell 会接着从终端读取并执行下一条命令。
我们通过下面的例子来理解在 shell 中执行外部命令的过程,例子很简单就是通过 cat 命令查看一个文本文件 test.log:
cat test.log
我们先来检查一下当前用户以及相关文件的权限:
$ uid=1000(nick) gid=1000(nick) groups=1000(nick),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),120(lpadmin),132(lxd),133(sambashare)
$ ll /bin/cat
-rwxr-xr-x 1 root root 43K Sep 5 2019 /bin/cat
$ ll test.log
-rw-rw-r-- 1 nick nick 0 Mar 2 23:25 test.log
当前用户 nick 的 real user id 为 1000,/bin/cat 文件的所有者为 root,但是所有人都有执行权限,test.log 文件的所有者为 nick。我们结合下图来介绍 cat test.log 命令的执行过程:
当我们在 shell 中执行一个外部程序的时候,默认情况下进程的 effective user ID 等于 real user ID,进程的 effective group ID 等于 real group ID(接下来的介绍中省略 group ID)。当我们以用户 nick 登录系统,并在 bash 中键入 cat test.log 命令并回车后。Bash 先通过 fork() 建立一个新的子进程,这个新的子进程是当前 bash 进程的一个副本。新的进程在 PATH 变量指定的路径中搜索 cat 程序,找到 /bin/cat 程序后检查其权限。/bin/cat 程序的所有者为 root,但是其他人具有读和执行的权限,所以新进程可以通过 exec 函数用 cat 程序的代码段替换当前进程中的代码段(把 /bin/cat 程序加载到了内存中,此时的进程已经变成了 cat 进程,cat 进程会从 _start 函数开始执行)。由于 cat 进程是由用户 nick 启动的,所以 cat 进程的 effective user ID 是 1000(nick)。同时 cat 进程的 effective user ID 和 test.log 文件的 owner ID 相同(都是 1000),所以 cat 进程拥有对此文件的 rw- 权限,那么顺理成章地就可以读写 test.log 文件的内容了。
脚本
在 shell 中执行脚本的方式和执行外部命令的方式差不多,比如我们要执行下面的脚本:
/bin/bash ./test.sh
这时同样会 fork 出一个子进程。只不过脚本与程序相比没有代码段,也没有 _start 函数,此时 exec 函数就会执行另外一套机制。比如我们在 test.sh 文件的第一行通过 #!/bin/bash 指定了一个解释器,那么解释器程序的代码段会用来替换当前进程的代码段,并且从解释器的_start 函数开始执行,而这个文本文件被当作命令行参数传给解释器。所以上面的命令执行过程为:Bash 进程 fork/exec 一个子 bash 进程用于执行脚本,子 bash 进程继承父进程的环境变量、用户信息等内容,父进程等待子 bash 进程终止。
- 权限
- cgroub
- sudo
- fdisk
- 自动更新
- LVM
- 进程
Capabilities
为了执行权限检查,Linux 区分两类进程:特权进程(其有效用户标识为 0,也就是超级用户 root)和非特权进程(其有效用户标识为非零)。 特权进程绕过所有内核权限检查,而非特权进程则根据进程凭证(通常为有效 UID,有效 GID 和补充组列表)进行完全权限检查。
以常用的 passwd 命令为例,修改用户密码需要具有 root 权限,而普通用户是没有这个权限的。但是实际上普通用户又可以修改自己的密码,这是怎么回事?在 Linux 的权限控制机制中,有一类比较特殊的权限设置,比如 SUID(Set User ID on execution)。因为程序文件 /bin/passwd 被设置了 SUID 标识,所以普通用户在执行 passwd 命令时,进程是以 passwd 的所有者,也就是 root 用户的身份运行,从而修改密码。
SUID 虽然可以解决问题,却带来了安全隐患。当运行设置了 SUID 的命令时,通常只是需要很小一部分的特权,但是 SUID 给了它 root 具有的全部权限。因此一旦 被设置了 SUID 的命令出现漏洞,就很容易被利用。也就是说 SUID 机制在增大了系统的安全攻击面。
Linux 引入了 capabilities 机制对 root 权限进行细粒度的控制,实现按需授权,从而减小系统的安全攻击面。
简介
从内核 2.2 开始,Linux 将传统上与超级用户 root 关联的特权划分为不同的单元,称为 capabilites。Capabilites 作为线程(Linux 并不真正区分进程和线程)的属性存在,每个单元可以独立启用和禁用。如此一来,权限检查的过程就变成了:在执行特权操作时,如果进程的有效身份不是 root,就去检查是否具有该特权操作所对应的 capabilites,并以此决定是否可以进行该特权操作。比如要向进程发送信号(kill()),就得具有 capability CAP_KILL;如果设置系统时间,就得具有 capability CAP_SYS_TIME。
下面是从 capabilities man page 中摘取的 capabilites 列表:
| capability 名称 | 描述 |
|---|---|
| CAP_AUDIT_CONTROL | 启用和禁用内核审计;改变审计过滤规则;检索审计状态和过滤规则 |
| CAP_AUDIT_READ | 允许通过 multicast netlink 套接字读取审计日志 |
| CAP_AUDIT_WRITE | 将记录写入内核审计日志 |
| CAP_BLOCK_SUSPEND | 使用可以阻止系统挂起的特性 |
| CAP_CHOWN | 修改文件所有者的权限 |
| CAP_DAC_OVERRIDE | 忽略文件的 DAC 访问限制 |
| CAP_DAC_READ_SEARCH | 忽略文件读及目录搜索的 DAC 访问限制 |
| CAP_FOWNER | 忽略文件属主 ID 必须和进程用户 ID 相匹配的限制 |
| CAP_FSETID | 允许设置文件的 setuid 位 |
| CAP_IPC_LOCK | 允许锁定共享内存片段 |
| CAP_IPC_OWNER | 忽略 IPC 所有权检查 |
| CAP_KILL | 允许对不属于自己的进程发送信号 |
| CAP_LEASE | 允许修改文件锁的 FL_LEASE 标志 |
| CAP_LINUX_IMMUTABLE | 允许修改文件的 IMMUTABLE 和 APPEND 属性标志 |
| CAP_MAC_ADMIN | 允许 MAC 配置或状态更改 |
| CAP_MAC_OVERRIDE | 覆盖 MAC(Mandatory Access Control) |
| CAP_MKNOD | 允许使用 mknod() 系统调用 |
| CAP_NET_ADMIN | 允许执行网络管理任务 |
| CAP_NET_BIND_SERVICE | 允许绑定到小于 1024 的端口 |
| CAP_NET_BROADCAST | 允许网络广播和多播访问 |
| CAP_NET_RAW | 允许使用原始套接字 |
| CAP_SETGID | 允许改变进程的 GID |
| CAP_SETFCAP | 允许为文件设置任意的 capabilities |
| CAP_SETPCAP | 参考 capabilities man page |
| CAP_SETUID | 允许改变进程的 UID |
| CAP_SYS_ADMIN | 允许执行系统管理任务,如加载或卸载文件系统、设置磁盘配额等 |
| CAP_SYS_BOOT | 允许重新启动系统 |
| CAP_SYS_CHROOT | 允许使用 chroot() 系统调用 |
| CAP_SYS_MODULE | 允许插入和删除内核模块 |
| CAP_SYS_NICE | 允许提升优先级及设置其他进程的优先级 |
| CAP_SYS_PACCT | 允许执行进程的 BSD 式审计 |
| CAP_SYS_PTRACE | 允许跟踪任何进程 |
| CAP_SYS_RAWIO | 允许直接访问 /devport、/dev/mem、/dev/kmem 及原始块设备 |
| CAP_SYS_RESOURCE | 忽略资源限制 |
| CAP_SYS_TIME | 允许改变系统时钟 |
| CAP_SYS_TTY_CONFIG | 允许配置 TTY 设备 |
| CAP_SYSLOG | 允许使用 syslog() 系统调用 |
| CAP_WAKE_ALARM | 允许触发一些能唤醒系统的东西(比如 CLOCK_BOOTTIME_ALARM 计时器) |
程序文件的 capabilities
在可执行文件的属性中有三个集合来保存三类 capabilities,它们分别是:
- Permitted
- Inheritable
- Effective
在进程执行时,Permitted 集合中的 capabilites 自动被加入到进程的 Permitted 集合中。
Inheritable 集合中的 capabilites 会与进程的 Inheritable 集合执行逻辑与操作,以确定进程在执行 execve 函数后哪些 capabilites 被继承。
Effective 只是一个 bit。如果设置为开启,那么在执行 execve 函数后,Permitted 集合中新增的 capabilities 会自动出现在进程的 Effective 集合中。
进程的 capabilities
进程中有五种 capabilities 集合类型,分别是:
- Permitted
- Inheritable
- Effective
- Bounding
- Ambient
相比文件的 capabilites,进程的 capabilities 多了两个集合,分别是 Bounding 和 Ambient。
/proc/[pid]/status 文件中包含了进程的五个 capabilities 集合的信息,我们可以通过下面的命名查看当前进程的 capabilities 信息:
$ cat /proc/$$/status | grep 'Cap'
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 000003ffffffffff
CapAmb: 0000000000000000
但是这中方式获得的信息无法阅读,我们需要使用 capsh 命令把它们转义为可读的格式:
capsh --decode=0000003fffffffff
使用
getcap 命令和 setcap 命令分别用来查看和设置程序文件的 capabilities 属性。下面我们演示如何使用 capabilities 代替 ping 命令的 SUID。
因为 ping 命令在执行时需要访问网络,这就需要获得 root 权限,常规的做法是通过 SUID 实现的(和 passwd 命令相同):
$ ll /bin/ping
-rwsr-xr-x 1 root root 72K Jan 31 2020 /bin/ping
$ ll /usr/bin/passwd
-rwsr-xr-x 1 root root 67K Jul 15 2021 /usr/bin/passwd
红框中的 s 说明应用程序文件被设置了 SUID,这样普通用户就可以执行这些命令了。
移除 ping 命令文件上的 SUID 权限:
$ sudo chmod 755 /bin/ping
$ ping baidu.com
ping: socket: Operation not permitted
在移除 SUID 权限后,普通用户在执行 ping 命令时碰到了 “ping: socket: Operation not permitted” 错误。
为 ping 命令文件添加 capabilities
执行 ping 命令所需的 capabilities 为 cap_net_admin 和 cap_net_raw,通过 setcap 命令可以添加它们:
$ sudo setcap cap_net_admin,cap_net_raw+ep /bin/ping
$ getcap /bin/ping
/bin/ping = cap_net_admin,cap_net_raw+ep
$ ping baidu.com
PING baidu.com (220.181.38.148) 56(84) bytes of data.
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=46 time=33.3 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=46 time=40.9 ms
被赋予合适的 capabilities 后,ping 命令又可以正常工作了,相比 SUID 它只具有必要的特权,在最大程度上减小了系统的安全攻击面。
如果要移除刚才添加的 capabilities,执行下面的命令:
$ sudo setcap cap_net_admin,cap_net_raw-ep /bin/ping
$ getcap /bin/ping
/bin/ping =
命令中的 ep 分别表示 Effective 和 Permitted 集合,+ 号表示把指定的 capabilities 添加到这些集合中,- 号表示从集合中移除(对于 Effective 来说是设置或者清除位)。