
GUI Utilities
Chrome
因为 Chrome 安装包的时候会自动添加 gpg,因此可以参考 Bypass GPG signature checks only for a single repository 执行如下操作
sudo sh -c 'echo "deb [arch=amd64 trusted=yes] https://dl.google.com/linux/chrome/deb/ stable main" > /etc/apt/sources.list.d/google-chrome.list'
sudo apt update
sudo apt install google-chrome-stable
PS:之前直接複製網上的,結果一直報錯,原因在於要寫 https 而非 http。
- Launch Chrome on your computer.
- Type the following in the address bar and pressEnter:
chrome://flags - On the flags screen, put your cursor in the search box and type Password import.
- You should see the Password import flag in the search results.
- To enable this flag, click the dropdown menu next to the flag and select Enabled.
- Click Relaunch at the bottom to relaunch Chrome. This will restore all of your open tabs.
- When Chrome opens, click the three dots in the top-right corner, and select Settings > Passwords on the following screen.
- Click the three dots next to Saved Passwords and select Import.
- Navigate to your CSV passwords file and select it to import it into Chrome.
- [user data dir]
~/.config/google-chrome - [profile dir]
~/.config/google-chrome/Default - [user cache dir]
~/.cache/google-chrome/Default
Dark Mode
注意:以下设置部分在 Android 端依然有效。
设置:
- Appearance => Use GTK:在系统启用 Dark 模式下,会使窗口,标签页等浏览器上部分变黑暗
- 启用
chrome://flags/#enable-force-dark:会使设置页,网页黑暗;在 Google 搜索页面,设置 => 外观 => 深色主题,可以使搜索结果词条访问过的与没有访问过的相区别(如果没有设置就会呈现一个颜色而无法区分)。有些网页也无效,并且完全看不清文字了,解决办法是启用Enable with increased text contrast,例如依云的博客。
其他:
- Dark reader 插件:会使网页黑暗。有些页面不起作用,比如 chrome web store、chrome 的设置页、插件、一些网站(即使该网站有黑暗模式,并且跟随系统,依旧显示为 light 模式)。除了无效的,不会使网页变得更难看。
- 开发工具的暗黑设置:按 F12 => 按 F1 ,设置主题为 Dark。
断点续传
含义:
Pause it with the option built-in to Chrome, and hibernate the computer. If the SERVER that is providing the download supports resuming downloads, then after you resume from hibernation, you should have no issues resuming the download.
After you pause the download, there is no need to touch Chrome. Just pause, and hibernate. By that I mean, don’t close Chrome. Don’t kill it or edit anything. Just pause the download, leave Chrome up and running, and hibernate.
明确需求:我要的不是“断点续传”(即 Pause & Resume),而是类似 aria2 的“始终断点续传”,前面一种在下载失败后会重新开始下载,而后面一种从失败的地方继续下载。
方案如下:
- 旧版
chrome://flags/#enable-download-resumption,新版内置 - Chrono Download Manager 扩展
- 支持断点续传的下载器,如
wge -c link
Chrome 浏览器内置了实时字幕功能,同步将语音转成文字,显示在网页上,对于看英文视频、听英文播客很有用。
PWA(Progressive Web Apps,渐进式 Web 应用)运用现代的 Web API 以及传统的渐进式增强策略来创建跨平台 Web 应用程序。这些应用无处不在、功能丰富,使其具有与原生应用相同的用户体验优势。
Spotify、抖音、 微博等都有 PWA 版,只需打开网页,点击搜索栏中右侧电脑图标安装就行了。
Translate
每次打开页面,都弹出翻译来,真得很烦,可以在 Language 中关闭 Offer to translate pages that aren’t in a language you read,之后再通过右键
Remove history of input in Chrome
To remove autofill data in chrome. You will have to Clear your auto fill data.
- Open the chrome menu using the three dots in the top, right side of your window and click settings, or navigate to
chrome://settingsin your address bar. - Scroll to the bottom and go into the ‘Advanced’ section
- Under ‘Privacy and security’ select ‘Clear browsing data’
- Then make sure only ‘Auto-fill’ form data is selected and press the Clear data button
- Chrome has now removed your auto fill data.
Extensions
-
阅读模式
- Reader View:Access Firefox’s built in reader view from right click context menu
- Reader Mode
-
PixelZoomer:测量设计图中图片的尺寸、像素
-
Download All Images:下载网页所有图片
-
uBlock Origin:禁广告
-
沙拉查词:聚合词典专业划词翻译
-
Infinity New Tab:Chrome Extension,解决 Chrome new tab 加载后会清空搜索栏问题
-
DeepL Translate:评论家对于它的评价普遍正面,认为它的翻译比起 Google 翻译更为准确自然。
-
uBlacklist + Google-Chinese-Results-Blocklist:屏蔽出现在 Google、百度的中文搜索结果中的垃圾站点
用户脚本管理器
桌面端
- Chrome:Tampermonkey 或 Violentmonkey
- Firefox:Greasemonkey、Tampermonkey 或 Violentmonkey
- Safari:Tampermonkey 或 Userscripts
- Microsoft Edge:Tampermonkey
- Opera:Tampermonkey 或 Violentmonkey
- Maxthon:Violentmonkey
- AdGuard:(不需要其他软件)
脚本
- FastGithub 镜像加速访问、克隆和下载
- 秒传链接提取:用于提取和生成百度网盘秒传链接
- 知乎增强:移除登录弹窗
- 网页复制限制解除
- 解锁视频
Chromium
Chromium 是一款来自 “The Chromium Project” 的开源图形网络浏览器,基于 Blink 渲染引擎。它也是商业软件 Google Chrome 浏览器得以组成的基础。
在这里你可以看到 Google Chrome 与 Chromium 浏览器的区别。此外,还有一点重要的不同:2021 年 3 月 2 日发布的 Chromium 89 及其以后版本不再支持 Google 账户同步功能。
注意: 目前,可以通过 使用 Chrome 的 OAuth2 凭证或者 申请一个属于自己的凭证来恢复同步功能, 但是请注意,这不一定是一个长期的解决方案。长期来讲,最好考虑使用 xbrowsersync 来同步书签数据。
Firefox
设置
- Sign In => Sync
- Settings => Proxy => no proxy
- Settings => Search => Bing
- Settings => Home => Firefox Home
- Add-ons => Dark Reader
Multimedia Codecs
主要用于 Firefox,安装媒体解码器来播放 MP3、MPEG4 和其他格式媒体文件。由于各个国家的版权问题, Ubuntu 在默认情况下不会安装它。
sudo proxychains apt install ubuntu-restricted-extras -y
GoldenDict
人一生离不开词典。无论是生活、学习还是工作,当我们遇到不懂的词语时,大部分人的解决方法是使用搜索引擎或者查词软件。作为学习者,我认为查词软件更好用,而且一本或几本好词典能让我们学习事半功倍。而免费查词软件我推荐 GoldenDict。
GoldenDict 的优点:
- 免费
- 纯净无广告 == 专注
- 跨平台:Windows / Mac / Linux
- 支持多种词典格式
- 支持查维基百科 / 支持在线查词 / 支持在线翻译(需配置)
- 支持屏幕取词 == 划词释义
- 支持听取 forvo.com 上的发音
- 详见 GoldenDict 官网 的权威说明。
GoldenDict 的缺点:
- 无 OCR 屏幕取词 / 无截屏翻译
- 无单词本。
知道 GoldenDict 的优缺点后,充分利用其优点的同时,我们想办法补齐短板。
GoldenDict 擅长查词,不擅长文本翻译,可是查词和文本翻译是分不开的,都是我们学习第二语言时经常需要的功能。为此,我引入两个文本翻译程序:CopyTranslator / Saladict。
无论你用什么电脑操作系统,都能利用它们进行高效率的查词和文本翻译。我认为这对用户很重要。只要我在系统里,我就能随时查词和文本翻译。
GoldenDict 擅长查词:
意味着你可以管理多个词典,并利用好的词典对单词进行深度学习。你把 GoldenDict 想成一个书架,上面放了多本纸质词典供你查阅。
CopyTranslator / Saladict 擅长文本翻译:
意味着能极大提高你在文本翻译时的效率。比如拥有多个翻译引擎(Google,Baidu,Youdao 等),方便复制翻译结果等。当然,职业译者肯定使用专业的 CAT 软件。
好,下面开始学习使用 GoldenDict。
安装
- **Windows:**下载安装最新版,当前为 [GoldenDict-1.5.0-RC2-372-*.exe(2019-04-27)](https://sourceforge.net/projects/goldendict/files/early access builds/)。
- **macOS:**下载安装最新版,当前为 [GoldenDict-1.5.0-RC2-372-*.dmg(2019-04-27)](https://sourceforge.net/projects/goldendict/files/early access builds/MacOS/)。
- Linux :终端上执行安装命令
# Ubuntu / Debian
sudo apt install goldendict -y
下面我在 Linux 上做演示操作。(Windows / macOS 大同小异)
打开 GoldenDict
如果你一直用鼠标点击软件图标打开软件,我强烈建议你用更高效的方式——搜索打开应用。按 Super(Win) 键搜索 gold 再按 Enter 键打开程序:
第一次使用,建议阅读两遍 欢迎说明。
为什么搜索打开应用更高效?这就考验你有没有「搜商」了。搜索只依赖键盘,不依赖鼠标,所以能盲开应用。
修改语言
菜单栏选择**【编辑】>【首选项】**:根据需要修改界面语言和显示风格。
管理词典
下载词典
我选了 4 部体积小的词典进行快速演练:
词典来源:星际译王词库 词典下载
存放词典
根据个人情况选择存放位置。我这里放在 /DATA/Software/GoldenDict/dic/ 下。
导入词典
菜单栏选择**【编辑】>【词典】>【词典来源】>【文件】> 添加** 选择上一步的词典位置打开,点击 重新扫描 完成后 Apply 应用,切换到**【群组】**选项卡接着完成下一步词典分组。
词典分组
刚才下载了「四类」词典:英汉、英英、汉英、汉语,需要将它们按类分组。(这里的英汉包括英汉词典和英汉双解词典,同样,汉英包括汉英词典和汉英双解词典。)
选择**【群组】> 添加群组**,然后在左边 可用词典 中选中,点击中间 > 添加到分组,最后 OK 确认:
英汉(En - 中)(自定义快捷键:Ctrl-1):牛津现代英汉双解词典 英英(En - En)(自定义快捷键:Ctrl-2):Oxford Advanced Learner’s Dictionary 汉英(中 - En)(自定义快捷键:Ctrl-3):朗道汉英字典 汉语(Chinese)(自定义快捷键:Ctrl-4):新华字典
为什么需要分组?当词典很多时,提高检索速度和分类检索。所以,你也可以按使用频率进行分组,比如分一个 最常用 群组。你喜欢就好。
使用
复制查词
最笨最原始的方式,就是复制词语再跑到 GoldenDict 窗口粘贴查询。怎么样才叫不笨呢?
菜单栏选择**【编辑】>【首选项】>【热键】**可以看到。
热键 Ctrl+C+C 的意思是,选中需要翻译的词句,按住 Ctrl 再按两下 C 键 ,就能呼唤 GoldenDict 帮你翻译。
所以正确的查词姿势是:选中词句,Ctrl+C+C。
下面我列了两个场景现场操练一下(需要完成前面的步骤):
英文场景: 此时你正趴在屏幕前哭逼地学习英文。
Q:What do I need to plant a flower? A:I need fresh soil and a trowel to dig a hole.
我们可以猜出 Trowel 的意思,现在假设你不知道,赶紧选中 Trowel,Ctrl+C+C,在 牛津现代英汉双解词典 里查到是小铲子的意思。
中文场景: 此时你正趴在屏幕前读苏轼的《赤壁赋》。
客有吹洞箫者,倚歌而和之。 其声呜呜然,如怨如慕,如泣如诉;余音袅袅,不绝如缕。 舞幽壑之潜蛟,泣孤舟之嫠妇。
假设你不知道 嫠 字怎么读,这时候赶紧选中 嫠,Ctrl+C+C,马上就查出来了读嫠(lí)专指寡妇。
取词窗口 上有一些按钮,鼠标悬停在上面会弹出解释,常用的是导航栏中的 查询框 、**将词条发送到主窗口(alt-W)**以及 添加收藏(ctrl-E)。 默认在 全部 群组中查询,可以切换到特定群组进行查询。不要怕,不要懒,多点点看看,就能用好这款神器了。
手动查词:模糊匹配
在查询框中,利用通配符进行词目(headwords)的模糊匹配,可以查询一个记忆模糊的单词。
通配符:? (匹配任意一个字符),*(匹配任意字符数字)。
比如,我要查一下 philosophy 的用法,但是忘记了拼写,我可以搜 ph*phy。使用方法非常简单,不做过多介绍。
如果实在想不起来英文单词,就查查汉英词典。
前面四部词典是为了快速演练。下面我将使用我喜欢的词典进行展示,这些词典内容丰富(体积很大),会有更好的展示效果。这些词典在下文 英语词典推荐 部分有介绍。
调整界面
我们要记住快捷键 Ctrl+M,显示 / 隐藏菜单栏(Menu)。程序窗口中 7 个面板都可以被隐藏,从上到下,从左到右依次为:
- 菜单栏
- 查询面板
- 导航栏
- 词典栏
- 查询结果导航面板
- 收藏面板
- 历史面板
在面板标题上右键,可以选择是否显示该面板。还可以左键拖拽面板调整其位置。我喜欢隐藏菜单栏显示查询面板:
按住 Ctrl 后滑动鼠标滚轮,可以缩放显示界面。也可以使用导航栏上的放大镜按钮调节。
我的这部词典有发音,所以可以点击喇叭图标听发音。如果点击喇叭图标没有声音,菜单栏选择**【编辑】>【首选项】>【音频】> 播放 > 设置播放器**,我这里使用了内部播放器: Qt Multimedia 。当然也可以使用外部播放器:mplayer 。(前提是安装了 mplayer :sudo apt -y install mplayer)
排序词典
查找单词时,会按照词典栏的词典顺序进行检索,现在我想把 The little dict 放到第一的位置:菜单栏选择**【编辑】>【词典】>【词典】**,把 The little dict 拖到第一位。
这里调整的是默认群组 全部 中的词典顺序,要调整自定义群组的词典顺序,切换到【群组】选项卡,拖拽群组中的条目进行排序。
屏幕取词 / 划词释义
Ctrl+C+C 是大多数时候的正常查词姿势,不过在特定场景下,比如阅读生词较多的英文文章、英文书籍时, 打开屏幕取词会使效率提升。点击导航栏中魔法棒图标开启屏幕取词,或者右键托盘图标勾选「屏幕取词」。Windows 上是真的屏幕取词,即鼠标悬停取词;而 Linux 上为划词释义,需要手动选择。
按 F4 打开【首选项】,在屏幕取词选项卡可以对「屏幕取词」进行设置。除非 Ctrl-C-C 快捷键冲突,否则,保持默认就行。
LCinux 上,如果你觉得经常按 Ctrl+C+C 麻烦,更喜欢用 C 鼠标控制取词,你可以勾选「单词被选中时显示扫描旗标」,通过点击旗标进行查词。(Windows 版本没有此选项)
一起看看 GoldenDict 与浏览器翻译扩展程序之间的差别:
- 统一入口,使用同一个程序 / 使用自己喜欢的词典来学习;
- 利用英汉词典快速查看释义,同时可利用其他词典深入学习,边学边用学习效率高(前提是时间允许);
- 有些人说扩展更快速,我没感觉出来;
- 可以跨浏览器、跨软件使用;
- 离线使用,你可以愉快地看电脑上的英文(DOC、PPT、TXT、PDF、EPUB、HTML 等任何电子文档格式);
查词:在线词典
本地词典可以灵活选择适合自己的词典,非常惬意!但是本地词库收词有限,如果你遇到一个没有收录的单词,怎么办?
只能查在线词典了!
为 GoldenDict 添加在线词典非常简单。
菜单栏选择**【编辑】>【词典】>【词典来源】>【网站】> 添加 > 启用** :
# 欧路
https://dict.eudic.net/dicts/en/%GDWORD%
# 有道词典 / 翻译
http://dict.youdao.com/search?q=%GDWORD%&ue=utf8
# Collins Online Dictionary
https://www.collinsdictionary.com/dictionary/english/%GDWORD%
切换到【群组】选项卡,添加到名为 Online Dictionary 的群组(自定义快捷键:Ctrl-5)。
其他在线词典,可通过浏览器访问使用:
查词:维基百科
维基百科绝对是个好东西!
由于国内无法访问到 English Wikipedia,所以这里取消显示。(除非你在【首选项】>【网络】中通过代理访问)
菜单栏选择**【编辑】>【词典】>【词典来源】>【维基百科】**,取消勾选。
查词:搜索引擎
是的,聪明的你一定会想,我可以直接添加搜索引擎吗?可以的。下面是谷歌 / 搜狗 / 百度 / 必应的搜索串:
# Bing 中国:
http://cn.bing.com/search?q=%GDWORD%
# Bing 美国:
http://www.bing.com/search?q=%GDWORD%
# 搜狗
http://www.sogou.com/web?query=%GDWORD%
# 百度搜索
http://www.baidu.com/s?wd=%GDWORD%
# Google
https://google.com/search?q=%GDWORD%
菜单栏选择**【编辑】>【词典】>【词典来源】>【网站】> 添加 > 启用**。切换到【群组】选项卡,将其添加到 Online Dictionary 群组。
这里我添加必应搜索并查询 蜗牛,然后双击结果 snails 进行英文搜索,可查看搜索引擎里的图片,帮助我们理解记忆单词。因为词典里面配图一般比较少,搜索引擎将使你获得更多相关信息,辅助学习(警惕浪费时间)。
文本翻译:谷歌翻译
(Linux 上做演示):如果不显示翻译,可能是代理之类的问题,可以先在终端运行一下 goldendict,之后便没问题了(原因未知)
translate-shell 支持谷歌翻译或者必应翻译,我们可以在 GoldenDict 上利用其进行文本翻译。
第一步:安装 translate-shell
Linux
# Ubuntu
$ sudo apt install translate-shell -y
macOS
# Homebrew
$ brew install translate-shell
# MacPorts
$ sudo port install translate-shell
Windows
- 配置比较繁琐,推荐使用 xinebf/google-translate-for-goldendict(使用方法见后面)。或者使用 CopyTranslator。
第二步:菜单栏选择**【编辑】>【词典】>【词典来源】>【程序】> 添加**,进行如下配置(类型为纯文本):
# Google Translate -> [Chinese]
trans -e google -s auto -t zh-CN -show-original n -show-original-phonetics n -show-translation n -show-translation-phonetics n -show-prompt-message n -show-languages n -show-original-dictionary n -show-dictionary n -show-alternatives n -no-ansi "%GDWORD%"
# Google Translate -> [English]
trans -e google -s auto -t en-US -show-original n -show-original-phonetics n -show-translation n -show-translation-phonetics n -show-prompt-message n -show-languages n -show-original-dictionary n -show-dictionary n -show-alternatives n -no-ansi "%GDWORD%"
-show-originalShow original text or not. (default: yes)-show-original-phoneticsShow phonetic notation of original text or not. (default: yes)-show-translationShow translation or not. (default: yes)-show-translation-phoneticsShow phonetic notation of translation or not. (default: yes)-show-prompt-messageShow prompt message or not. (default: yes)-show-languagesShow source and target languages or not. (default: yes)-show-original-dictionaryShow dictionary entry of original text or not. (default: no) This option is enabled in dictionary mode.-show-dictionaryShow dictionary entry of translation or not. (default: yes)-show-alternativesShow alternative translations or not. (default: yes)-no-ansiDo not use ANSI escape codes.
第三步:切换到**【群组】> 添加群组 > Translate**,并添加 图标,设置群组快捷键为 Shift+T(可选)
{kind=link}
第四步:实践一下,在终端中 Ctrl+C+C,查询框处选择 Translate 群组,就看到翻译结果啦
添加在线翻译后,GoldenDict 就能跨软件快速翻译。无论你是在浏览网页,还是在阅读英文书籍,或者看软件英文手册, Ctrl+C+C 快速查看翻译。你还可以收藏你翻译过的短语。
Windows 上使用 google-translate-for-goldendict:
到 Python 官网下载最新版安装包,当前为 python-3.8.2-amd64.exe,安装时勾选 Add Python 3.8 to PATH 就行。
打开 CMD 运行:
> python -m pip install --upgrade pip
> pip3 install google-translate-for-goldendict
先升级 pip 至最新版,然后再安装。
按 F3 打开 GoldenDict 词典配置界面, 进入【程序】选项卡:
| key | value |
|---|---|
| Enabled | ✓ |
| Type | Html |
| Name | Google Translate |
| Command Line | python -m googletranslate.googletranslate zh-CN %GDWORD% -s “translate.google.cn” |
| Icon | H:\PathTo\google_translate.png |
切换到**【群组】> 添加群组 > Translate**,并添加 图标,设置群组快捷键为 Shift+T。
文本翻译:有道翻译
在 Linux 上,利用 easeflyer 开发的 gd_plugin 添加有道翻译。
将项目克隆下来:
cd ~
git clone git@github.com:easeflyer/gd_plugin.git
按 F3 打开 GoldenDict 词典配置界面, 进入【程序】选项卡(路径替换为自己的绝对路径):
| key | value |
|---|---|
| Enabled | ✓ |
| Type | Html |
| Name | Youdao Translate |
| Command Line | /home/YOUR_USER_NAME/gd_plugin/youdao/youdao_get.py %GDWORD% |
| Icon | /home/YOUR_USER_NAME/gd_plugin/youdao/youdao.svg |
下载图标 Youdao icons。
切换到【群组】选项卡,将其添加到 Translate 群组。
文本翻译:CopyTranslator
CopyTranslator 是复制即翻译的外文辅助阅读翻译解决方案,支持 Windows、Mac、Linux 三大平台,翻译引擎包括 Google,Baidu,Youdao,Sogou,Caiyun,Tencent。
下载 CopyTranslator 安装包 进行安装后,使用方法请阅读 CopyTranslator 官方文档。
CopyTranslator 擅长文本翻译,可是与 GoldenDict 交互使用时不够高效。所以,使用 GoldenDict 能满足需求时,就没必要打开 CopyTranslator。
有一款叫做 多译 的软件与 CopyTranslator 有相同功能,但是有字数限制,有兴趣可以了解一下。
文本翻译:Saladict
Saladict 沙拉查词(Chrome / Firefox)插件天生适合浏览器,Saladict 插件可以在线翻译、在线查词、在线语音朗读、添加单词本、页面翻译等。
使用方法参阅官方文档 沙拉查词使用方式。以及:
OCR 屏幕取词 / 截屏翻译
GoldenDict 默认无 OCR 屏幕取词,无截屏翻译。先介绍一种三个平台都通用的方法,使用 Utools + 扩展:讯飞 OCR + 扩展:沙拉查词。步骤为,将要翻译的文本截图粘贴到 Utools 中,然后选择「讯飞 OCR」识别内容,最后点击翻译按钮调用「沙拉查词」进行翻译。操作起来还是比较快的。
或者使用其他软件:
Windows
- 使用 Quicker 效率神器。(与 Utools 相似)
- 使用 nonwill 发布的 GoldenDict OCR 划词版。
macOS
- 使用有道词典 Mac 版。打开取词(CTRL + 鼠标取词)。
- 欧路词典。
Linux
- 利用 words-picker 进行截屏翻译。在 GNOME 桌面环境中,打开 words-picker 程序,然后使用系统截图快捷键 shift-ctrl-Print 将区域复制到剪贴板,完成截屏翻译。
- 使用有道词典 Linux 版。打开取词(CTRL + 鼠标取词)。
- 使用 CuteTranslation 进行截屏翻译。
对于那些无法复制的单词,如果查词频率高,就使用具有 OCR 屏幕取词的软件;如果偶尔查询,手动输入也不是什么坏事。
文本语音朗读
你可能会说:我不需要语音朗读。那是因为你没意识到它的用处或者说你忽略了它。你一定很喜欢词典中的例句发音,对听力和练习口语都有帮助。例句发音 = 句子 + 语音朗读,发散一下你的思维,当你翻译一个句子时,出于学习目的,你是不是同样希望能够听到它的语音朗读。而且学习英语不能太依赖眼睛,要多用耳朵听。
Windows 上按 F3 打开词典配置, 在【语音合成】选项卡进行配置;Linux 版本暂时没有 text-to-speech (TTS) 功能。Saladict 够用,我就不折腾了。
这里再推荐两款优秀的浏览器插件:
还有一个 灵云语音云服务:
- 它可以 文字转音频 / 录音转文字。
- 它更加侧重于应用场景,不过现在已经收费了。
总之,根据自己的需求,去寻找好资源。
背单词
GoldenDict 无单词本,意味着你不能像欧路词典那样,将单词添加到单词本中进行背诵。所以,只能「曲线救国」,将单词添加到收藏,隔一段时间(星期 / 月)就将收藏 导出至列表,然后放到 Anki 或 欧路词典中进行背诵复习。如有必要,付钱换取方便远离折腾。
将收藏 导入欧路词典单词本:菜单栏选择**【帮助】>【配置文件夹】**,可以看到收藏文件:favorites。
备份配置文件
换机或者重装系统时,需要备份你的 GoldenDict 配置文件。否则,一切将从头再来,你会很痛苦。
菜单栏选择**【帮助】>【配置文件夹】**,直接将整个文件夹进行备份。
新机或者新系统上,将整个文件夹拷贝到原来的位置,完成配置恢复。
恭喜!你会使用 GoldenDict 了
前面主要介绍了 GoldenDict 的使用方法。为提高文本翻译效率,引入了 CopyTranslator / Saladict 两款程序。为补足 GoldenDict OCR 屏幕取词和截屏翻译的缺失,也引入了相应的软件。我们期望有那么一款软件能聚合这些功能,但这样的软件我还没发现,或者说还没有。
现在的 GoldenDict 具备了离线查词、在线查词和在线翻译的能力,完全能满足我们的需求。而且 GoldenDict 的离线词库拥有最强的学习效果,所以你应该主要使用 GoldenDict 进行查词和文本翻译,而 CopyTranslator / Saladict 作为备用软件,主要用于增强文本翻译。同时也是为了统一入口,避免分散你的学习精力。具体怎么配合,多多使用,慢慢摸索。
细心的你不难发现,查词和文本翻译里面最核心的是词典和翻译引擎。
这里我们讨论一下词典。选用什么词典?我们需要做功课来回答。
我不打算直接甩几本词典放这里,对于新手,看了一定是云里雾里。
因为词典是每个人必须会用的东西,所以值得深入学习。
English Dictionary = 英语词典
字典和词典是两个不同的概念,不要乱叫。中国正式使用“字典”一词始于《康熙字典》。根据《说文解字》,典是五帝的书本,神圣尊贵的大册。
字典和词典的区别:
- 字典是为单字提供音韵、意思解释、例句、用法等等的工具书。使用字母文字作为文字的人群没有字典这个概念。字典收字为主,亦会收词。
- 词典(Dictionary),或称辞典,是为词语提供音韵、释义、例句用法等等的工具书。在东方社会中,词典收词为主,也会收字。为了配合社会发展需求,词典收词数量激增并发展出不同对象、不同行业及不同用途的词典。随着吸收百科全书的元素,更有百科辞典的出现。
如果你把 English Dictionary 翻译成「英语字典」,我只能安慰你:没文化不是你的错!
掌握词典行情,便于做出选择
通过了解词典的行情,了解词典应该为学习者提供哪些东西,我们就能选择适合自己的词典。如果同学 / 同事 / 朋友 / 小孩需要词典,也能轻松推荐。做「以其昏昏,使人昭昭」的事,心理没底不说还会被内行笑话。
下面主要讨论一下英语词典,对于汉语词典或者其他外语词典(日语、法语、德语、俄语或西班牙语等),自行了解。
提醒:后面的内容可能需要阅读多遍。
浅谈英语词典版本
我们主要以 出身、体例、功用 以及 规模 四个方面对英语词典进行分类。
一、出身
从出身上讲,英语词典大致可分为本土词典和引进词典两类。
- 本土词典主要是中国人编给中国人用的英汉词典,典型如译文社《英汉大词典》(陆谷孙主编)、《新英汉词典》(第 4 版)、商务《新时代英汉大词典》(张柏然主编)等。
- 引进词典又分为英系和美系两大类。目前英系词典占据中国市场的主导地位,著名的品牌如牛津、朗文、剑桥、麦克米伦、柯林斯,简称“牛朗剑麦柯”(谐音“牛郎见迈克”)合称“英国五虎”,除此还有一部词典叫做“钱伯斯”,对英国人意义非凡。美系词典主要有《美国传统词典》(The American Heritage Dictionary)和“韦氏词典”两大品牌。
二、体例
以体例划分,英语词典可分为英汉、英英、英汉双解、汉英、汉英双解以及其他类别等五种。
- 英汉词典 一般为(wéi)中国人所编写,如译文社《新英汉词典》;
- 英英词典 都是原版引进词典,如《牛津高阶英语词典》(OALD)、《朗文当代高级英语辞典》(Longman Dictionary of Contemporary English,简称 LDOCE);
- 英汉双解词典 是目前英语学习词典的主流,最重要的即是牛朗两部词典,英汉双解词典都译自英语原版词典,但并非真正全文翻译,大多数词目的英语释义以对应的汉语词语。
- 汉英词典 大多是本土词典,如外研社《新世纪汉英词典》、商务《新时代汉英词典》;
- 汉英双解词典 比较特殊,它是以国内原版的汉语词典编译而成,据我所知,目前只有外研社《现代汉语词典(双语版)》以及商务印书馆国际有限公司《新华字典(双语版)》两种;
- 除此以外,其他类别指的是国内引进少量英语与其他语种词典,如译文社引进的兰登系列词典《德英—英德小词典》(Random House Webster’s Pocket German Dictionary)以及外教社引进的《柯林斯英德—德英词典》等。
注:所谓双解词典,是一个英文单词,用英文解释一遍意思,再用中文解释一遍意思;用英文来解释是最准确的,中文可以辅助你去理解。 如果想通过中文查英文,需要一本汉英词典。
三、功用
首先从功用方面,将英语词典分为描述型、学习型和中和型三大类。
- 描述型
描述型英语词典又称为学术型英语词典,实际上描述型英语词典是最常见的英语词典,换作汉语工具书,诸如《新华字典》《现代汉语词典》都属于描述型词典,相反汉语工具书真正缺乏的学习型词典,除了一些给低幼学童使用的学习词典外,也就只有吕叔湘先生主编的《现代汉语八百词》等寥寥几部辞书。
我们进一步将描述型英语词典分为一般性、百科性和专业性三种。一般性描述词典典型如《牛津简明英语词典》《英汉大词典》,这类词典收词详备并且释义简明;百科性描述词典则有《牛津当代百科大词典》《牛津英美文化词典》等,主要收录文化百科类词条;专业性描述词典则是局限于某一学科或行业的词典,如《牛津哲学词典》和《牛津商务英语词典》。
- 学习型
学习型英语词典是专为英语学习者(多为非英语母语人士)设计的,注重英语实际应用时的用法说明,第一部学习型词典始于 1948 年由牛津大学出版社出版、霍恩比(A S Hornby)主编的《现代英语学习词典》(A Learner’s Dictionary of Current English),此即如今闻名于世的《牛津高阶英语词典》(OALD)的前身。
我们进一步将学习型英语词典分为一般性、多功能和专门性三种。
一般性英语学习型词典是我们最熟悉的品种,著名的“英国五虎”——“牛朗剑麦柯”都有自己品牌的学习型词典。(划重点)
最新版次,出版年份,出版社
- 《牛津高阶英汉双解词典》第 9 版,2018,商务
- Oxford Advanced Learner’s Dictionary (OALD) 9th Edition , 2015 , Oxford
- 《朗文当代高级英语辞典》第 6 版,2019,外研社
- Longman Dictionary of Contemporary English (LDOCE) 6th Edition , 2015 , Pearson
- 《剑桥高阶英汉双解词典》第 2? 版 , 2008,外研社
- Cambridge Advanced Learner’s Dictionary (CALD) 4th Edition , 2013 , Cambridge
- 《麦克米伦高阶英汉双解词典》第 1 版,2018,外研社
- MacMillan English Dictionary for Advanced Learners (MED) 2nd Edition , 2012 , MacMillan
- 《柯林斯高阶英汉双解学习词典》第 8 版,2017,外研社
- Collins COBUILD Advanced Learner’s Dictionary (CCALD) 9th Edition , 2018 , Collins
注: 关于书籍版次:第一次出版印刷的书写有“某年某月第一版,第一次印刷”,这叫初版,如内容不变动,第二次印就注明第一版第二次印刷,这种书叫重印书。如第三次印刷发行时内容经过重大修改,版次就要重新算,要称为:“第二版第三次印刷”。不过这个问题一般人不用想那么多,只需看自己是否喜欢这本词典,喜欢的话买国内最新版即可,毕竟每家词典各有特色。英语水平好的话,直接购买英文原版就行了。
- 中和型
中和型词典兼具学习型词典和描述型词典的部分特点,是当前英语词典编纂的新趋势,典型代表为《朗文当代英语大辞典》,在 2000 词限定释词的基础上收录了 15,000 百科词条,是融合释义、用法说明、文化注释以及百科知识于一体的文化学习词典。与此相类的另有《美国传统词典》。
四、规模
这是对英语词典最直观的分类,一般而言我们可以根据收词量和总字数将英语词典简单分为巨、大、中、小、微型五大类。
- 巨型词典
英语世界中的巨型词典主要有两部,一部即是由英国语言学家默里(James A.H.Murray)主编的久负盛名的《牛津英语词典》(The Oxford English Dictionary,简称 OED),另一部则是最初由美国词典编纂家韦伯斯特(Noah.Webster)主编的《韦氏新世界词典》(Webster Third New International Dictionary,简称 WTNID)。这两部词典是其他各类英语词典的母本,但却因其规模过大并不适合学习者案头使用。
- 大型词典
因此 20 世纪下半叶英语国家出版了大量单卷本供高阶学习者案头使用的大型词典,典型的有《牛津简明英语词典》(Concise Oxford Dictionary,简称 COD)、《柯林斯 COBUILD 英语词典》(Collins COBUILD English Dictionary,简称 CCED)以及《朗文当代英语大辞典》(Longman Dictionary of English Language & Culture,简称 LDELC);
- 中型词典
后来又有供中阶学习者使用的中型词典,主要有《牛津袖珍英语词典》(Pocket Oxford Dictionary,简称 POD)、《朗文活用英语词典》(Longman Active Study Dictionary,简称 LASD);
- 小型词典
其实除了案头常备的大中型词典,人们更为喜爱和常用的或许是那些便携的小型词典,如《牛津英语小词典》(Little Oxford Dictionary,简称 LOD);
- 微型词典
除此以外,还有一种更其小巧的微型词典,释义极尽简洁,如《牛津英语微型词典》(The Oxford Minidictionary,简称 OMD),但这类词典一般用于速查,不适合英语学习者日常使用。
词典应该为学习者提供哪些东西
用一本好词典你可以做到以下几点:
- 查找你看到或听到的英语单词的意思
- 找出如何说一个词
- 用你的语言找到一个单词的英文翻译
- 检查单词的拼写
- 检查动词的名词或过去时态的复数形式
- 找出一个单词的其他语法信息
- 找出一个词的同义词或反义词
- 查找单词的搭配
- 检查单词的词性
- 找出单词的语域
- 查找自然语言中单词的用法示例
- 听到例句的真人发音
- 查看配图学习单词
- 查看单词错误用法
- 观看单词在线教学视频(想象一下,当你查一个单词,一位美女 / 帅哥马上跳出来教你。恐怕你要天天抱着词典睡觉喽。)
所以,按照类型我们需要四种电子词典:英汉、英汉双解、英英、汉英。
英汉词典:
英汉词典主要是快速查看英语单词的中文释义。
英汉双解词典:
英汉双解词典对中级学习者当然非常友好,可以借助汉语翻译快速理解。如果查询一个单词需要耗费大量时间阅读英文解释,有时候是不明智的做法,并且,如果查一个单词里面又出现一大堆不认识的单词,太打击学习积极性了!另外,英汉双解词典是双向的,一般人是借助汉语理解英文,也有情况是借助英文查看对应的汉语翻译。所以,每个人必须有一本英汉双解词典。
英英词典:
当你英语到了一定水平(中高级水平)后,就应该主要使用英英词典。
英英词典分两种:ESL 词典(ESL: English as a second language)以及 Non-ESL 词典(又称母语词典)。Non-ESL 词典是指英美国家人士使用的词典,特点是收词量大,释义用词精确,范围广,无上限,很多词典例句很少或没有,有点类似于我们用的《新华字典》和《汉语大词典》 。ESL 词典就是上小节提到的学习型英语词典,专为英语学习者(多为非英语母语人士)设计,其优点是简单易懂,但其缺点也比较明显,由于释义用词所限,部分单词的解释比较啰嗦或者不精确,理解起来也不顺畅。
至于使用 ESL 词典还是 Non-ESL 词典,或者两者混合使用,就看你的需求了。
汉英词典:
使用汉语查找英文翻译或英文表达。
翻译软件的词库就来自于这些「英汉词典」和「汉英词典」。
有了上面的介绍,我可以推荐几本词典了。
英语词典推荐
1. 英汉词典:The Little Dict
用来提供快速翻译,还能聆听多个发音以及查看词频。「硬核之作,真香推荐,居家旅行沉迷学习必备,建议日常置顶食用。」下载
2. 英英·英汉双解词典(ESL)
- 朗文当代高级英语辞典(释义用词 2000 个)
- 柯林斯高阶英语学习词典(释义用词 2500 个)
- 牛津高阶英语词典(释义用词 3000 个)
2.1 朗文当代高级英语辞典
英英原版
- Longman Dictionary of Contemporary English 6th Edition (En-En),En-En_LDOCE6。
- 《朗文当代高级英语辞典(英英)(第六版)》,包含英式发音、美式发音、大部分例句朗读,带图片详解。这本词典收录单词量最大,例句最多,搭配和用法也最全。例句是真人原声,非常自然。
- 英语老师都会倡导学生尽量使用英英词典,营造英语环境,用英文解释英文,用英文理解英文,用英文对世界编码,有利于养成英语思维,对听说读写都有帮助。全英文解释,不会因为英汉差别而导致理解上的偏差。当然,英汉双解词典我们也是需要的。
英汉双解版
- En-Cn_LDOCE5++ V1.35 / V2.15。下载
- 《朗文当代高级英语辞典(英英·英汉双解)(第五版)》
- 这本词典默认是英英版,可以通过点击轻松查看汉语翻译。对于直接使用英英有些吃力的同学,可以设置默认展开汉语,立马就是一本英汉双解词典。释义用词仅 2000 个,让你轻松看懂。大量例句都有真人发音,让你爱上听例句。
PDF 版
- 《朗文当代高级英语辞典(英汉双解)(第五版)》。下载
朗文在线词典
2.2 柯林斯高阶英语学习词典
英英原版
- Collins COBUILD Advanced Learner’s Dictionary 9th Edition (En-En),En-En_CCALD9。
英汉双解版
- Collins COBUILD advanced learner’s English-Chinese dictionary 8th Edition。
- 《柯林斯 COBUILD 高阶英汉双解学习词典》(第 8 版)中的全部释义、例证及专栏均基于收词规模达 45 亿词的柯林斯英语语料库;所有单词及短语均采用整句释义,凸显词汇在典型语境中的典型用法。
- 强烈推荐!可以直接背诵单词及短语的整句释义,这就好比一个外国人在跟你交谈,对英语思维以及口语表达都有莫大的帮助。
柯林斯在线词典
2.3 牛津高阶英语词典
英英原版
- Oxford Advanced Learner’s Dictionary 9th edition (En-En),En-En_OALD9。下载
- 包含英式发音、美式发音,例句发音,带图片详解等。
英汉双解版
- Oxford Advanced Learner’s English-Chinese Dictionary 9th Edition,En-zh_CN_OALD9。下载
- 《牛津高阶英语词典》为世所公认的权威英语学习词典,惠及世界各地一代又一代学子。到第九版编者将会话与写作功能融入学习型词典。 释义简明,义项划分清晰;提供系统的语法信息,如搭配模式、用法说明框等;提供插图及主题图片,直观释义。新加牛津口语指南,详解日常及应试等场景会话用语。
- 纸质版配套光盘中提供 iWriter + iSpeaker 互动式写作和口语指导学习程序。
牛津在线词典
3. 汉英词典(任选一部)
- 汉英大词典(第 3 版)
- 新汉英大辞典
一般人上面几部词典基本够用。如果链接失效,可以试试 网盘搜索(超能搜 等)或者 逛论坛。
英语构词法规则
GoldenDict 安装的时候没有附带 构词法规则,查找一些单词的复数等变位变格形式的单词有时会查不到(比如有些词典查不到 Books,不会自动跳转到 Book),为了让 GoldenDict 更好地工作,我们添加 英语构词法规则库。
进入 SourceForge 上 GoldenDict 的项目地址,依次选择 Files > [better morphologies](https://sourceforge.net/projects/goldendict/files/better morphologies/) > [1.0](https://sourceforge.net/projects/goldendict/files/better morphologies/1.0/) > [en_US_1.0.zip](https://sourceforge.net/projects/goldendict/files/better morphologies/1.0/en_US_1.0.zip/download) 下载英语构词法规则库。
菜单栏选择**【编辑】>【词典】>【词典来源】>【构词法规则库】**,添加 英语构词法规则库。
朗文 5 ++:自动展开音节(Syllable)及汉语(Chinese)
我是 En-Cn_LDOCE5++ 和 En-En_LDOCE6 一起使用,所以把 LDOCE5++ 设置为自动展开音节及汉语。
下面介绍一下设置方法,适用于 En-Cn_LDOCE5++(V1.35 / V2.00 / V2.15)。
自动展开音节(Syllable)
打开文件 LM5style.css 搜索 show/hide syllable 注释掉以下代码块:
/* -------------- show/hide syllable -------------
.HWD .HYP {
display: none;
}*/
调整手机中悬浮球高度
手机欧路词典中 LDOCE5++ 的悬浮球会与控制按钮重叠,需要调整其高度。搜索 .mobile .lm5pp_popup 设置距离底部为 90px:
.mobile .lm5pp_popup {
bottom: 90px;
right: 10px;
}
自动展开汉语(Chinese)
打开 LM5style_switch.css 注释掉以下代码块:
/*.EXAMPLE .cn_txt, .Error .cn_txt,.cn_txt {
display: none;
}*/
可以偷懒直接删除 LM5style_switch.css(或者重命名为 LM5style_switch.css.bak)。但是,你将不能在悬浮球上控制隐藏/显示汉语。
如果你直接修改手机中的 CSS 文件,需要清除软件缓存再重启 App 才能生效。 如果你在电脑上修改,Ctrl+F5 可以快速刷新词典查看效果。 更多调整参见 FF 朗文 5++重排 DIY / 改版 fearfare 大的朗文。
GoldenDict 进阶技巧
效率提升:快捷键
除了全局热键外,GoldenDict 还支持许多程序快捷键。按 F1 快捷键打开 GoldenDict 帮助, 查看 13 Shortcuts。
第一次使用,按照快捷键列表操作一遍。主要是感受一下快捷键的功能,不要求强行记忆它们,当你经常进行某项操作时,再翻阅一下 13 Shortcuts,用几次就记住了。
常用快捷键:
| Shortcut | Action |
|---|---|
| Alt+Left | (In main and popup windows) history navigation: show previous founded results |
| Alt+Right | (In main and popup windows) history navigation: show next founded results |
| Alt+Down | Jump to article from next dictionary |
| Alt+Up | Jump to article from previous dictionary |
| Alt+S | (In main and popup windows) playback pronunciation for current word |
| Alt+W | (In popup window) transfer word from search line to main window |
| Alt+PgDown | (In main and popup windows) switch to next dictionaries group |
| Alt+PgUp | (In main and popup windows) switch to previous dictionaries group |
| Ctrl++ | Increase articles font size |
| Ctrl+– | Decrease articles font size |
| Ctrl+0 | Set default articles font size |
| Ctrl+E | Add current tab to Favorites |
| Ctrl+F | (In main and popup windows) search in page / (In dictionaries dialog) go to filter line |
| Ctrl+M | Show/hide main menu |
| Ctrl+Q | (In main window) close GoldenDict |
| Ctrl+S | Show/hide search pane |
| Ctrl+Shift+F | Open/switch to full-text search dialog |
| Esc | (In main window) go to search line (the action for Esc key can be changed in preferences) / (in popup window) close popup window |
| F1 | GoldenDict reference |
| F3 | Dictionaries dialog |
| F4 | GoldenDict preferences |
查句:全文搜索
按 F1 打开 GoldenDict 帮助, 查看 09 Full-text search。
可以通过菜单“搜索”或按“Ctrl+Shift+F”键来调用全文搜索对话框。通过全文搜索,可以在当前词典组的词典文本中而不是在词典 headwords(词目)中搜索单词和表达式。
**提醒:**如果 GoldenDict 占用 CPU (%) 超高,请关闭全文搜索索引。看一下文章 GoldenDict 全文搜索几例。
利用「全文搜索」查找英文表达,显然比直接将一句中文放到翻译软件中翻译更靠谱,比如下面这句摘自 牛津高阶英汉双解词典(第 9 版) 的例句:
I’ll ask my boss if I can have the day off. 我要问一下老板我能不能请一天假。
现在我复制中文到谷歌翻译中翻译,结果如下: I have to ask the boss if I can take a day off.
很显然翻译出来的英文枯燥无味。
下面举例简单介绍一下,使用「全文搜索」查找地道的英文表达。
例子:我想知道请假的的英文表达,包括日假周假年假。我该如何搜索?
快捷键 Ctrl+Shift+F 打开全文搜索,模式选择 正则表达式。
如果直接检索 请假 这个关键词,会因范围太大,需要更多检索时间,最后还会出来很多无用结果,所以我们需要缩小检索范围。
先检索日假。直接输入 请一天假,这个地球人都会,但「请两天假」的表达式就搜不到。现在,我们要一次检索出「请天假」的表达式,输入正则表达式:请.{1,3}天假(中间匹配 1-3 个字符)。
理论上,我们可以匹配出:请一天假 请两天假 请几天假 请过一天假 请了十五天假 ...
.:一个点,匹配任意单字符(不包括换行符){n,m}:m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?'。请注意在逗号和两个数之间不能有空格。
现在,我们要把请日假 / 周假 / 年假的表达式一次搜出来。
给搜索框写入正则表达式:请.{1,3}(天|周|年)假,就查出来了。
():标记一个子表达式的开始和结束位置。()?匹配前面的子表达式零次或一次,()+匹配前面的子表达式一次或多次。|:代表 或
正则表达式学习资源:
多读几遍 GoldenDict 帮助,掌握更多使用技巧。
其他
参考文章
- GoldenDict 中文用户手册
- 新手上路:GoldenDict——英语爱好者必备词典
- [使用教程] Linux 上最好用的词典 GoldenDict
- 在 GoldenDict 中添加谷歌翻译
- Ubuntu 安装 GoldenDict
- 英语词典版本浅谈(讲稿版)
- Linux 下非常好用的字典 GoldenDict!
- GoldenDict 添加构词法规则库
- GoldenDict 词典的超级实用高级玩法——全文搜索功能
Dark Theme
官方教程。
这个主题有个全黑暗模式,即显示词典结果部分也会黑暗,但是效果不好,看不清。
- Download GoldenDict-Full-Dark-Theme
- Move
stylesandfontsfolders to theGD Configuration Folder. IfGoldenDictis installed by default, theGD Configuration Folderis located at the~/.goldendict - Move the
iconsfolder to theGoldenDictprogram folder/usr/share/goldendict - Open GoldenDict menu “Preferences… → Interface”: set “Add-on style” to
dark-theme; set “Display style” toLingoes. - set “Display style” to
Default.
startup & silent start
-
startup:将 goldendict 添加到 gnome-session-properties,默认生成的是
$ cat ~/.config/autostart/goldendict.desktop [Desktop Entry] Type=Application Terminal=false Categories=Office;Dictionary; Name=GoldenDict GenericName=Multiformat Dictionary Comment=A feature-rich dictionary lookup program Icon=goldendict Exec=goldendict -
silent start:Edit => Preferences => start to system tray 就是静默启动
Audio Player
Installed FFmpeg, then set as follows: Edit > Preferences > Audio > Use external program
ffplay -nodisp -autoexit
crow-translate
Flameshot
Powerful, yet simple to use open-source screenshot software.
| Keys | Description |
|---|---|
| ←, ↓, ↑, → | Move selection 1px |
| Shift + ←, ↓, ↑, → | Resize selection 1px |
| Esc | Quit capture |
| Ctrl + C | Copy to clipboard |
| Ctrl + S | Save selection as a file |
| Ctrl + Z | Undo the last modification |
| Right Click | Show color picker |
| Mouse Wheel | Change the tool’s thickness |
- On ‘Name’, name it ‘
Flameshot’ - Define the command as ‘
flameshot gui’. - Select ‘Define shortcut…‘and click your keyboard
win+shift+Prt Sckey.
PPSSPP
A PSP emulator.
sudo add-apt-repository ppa:ppsspp/stable
sudo apt-get update
sudo apt install ppsspp
Graphics:
- Rendering Mode
- set the Backend from OpenGL to Vulkan.
- Framework Control
- Frameskipping is Off
- Auto-Frameskip is Off
- set the Alternative Speed to Unlimited
- Postprocessing effects
- Postprocessing shader should be off.
- Performance
- If your Device is Powerful, high rendering resolution will work. Its recommended to first try with 2x Rendering resolution as It brings impressive graphics and supports stable gameplay too
- Hardware transform, Software skinning, Vertex cache and Lazy texture caching should be checked.
- Retain changed textures should be unchecked while keeping Disable slower effects and Hardware Installation checked.
- Overlay Information
- Select FPS in Show FPS counter.
System:
- Make sure Fast memory is checked
- Set I/O timing method, to Simulate UMD delays or Fast
Cemu
教程:[cemu模拟器扫盲超级小白目录]Wiiu游戏之路的问题整理 - 知乎
Cemu: Experimental software to emulate Wii U applications.(已开源)
对于 Ubuntu(Linux):参考 Current State Of Linux Builds安装
对于 Windows 平台:为避免闪退等问题,到Cemu 官网下载最新版本软件和 Microsoft Visual C++ 2017 X64 Redistributable。更新:2024 年下载 2.x 无法正确安装游戏 BOTW,报错 Unable to Mount Title,1.x 可以玩。
获取游戏:
- WIIU中文游戏下载-WIIU汉化游戏全集-WIIU经典游戏 | OldmanEmu(解压密码
oldmanemu.net) - OldmanEmu 下载的都是 UWP 格式文件,有一堆 .app .h3 还有三个 title.xxx,Cemu 无法识别。可参考『教程』WUP格式转Loadiine最简单的方法【cemu吧】_百度贴吧。可在 Installing Games | Cemu Guide 中下载 CDecrypt,转换命令参考 decrypt.bat,如
D:\Downloads\Cdecrypt_v2.0b\CDecrypt_v2.0b.exe .\title.tmd .\title.tik
安装游戏:导航到 Options > General settings > General,在 Game Paths 中添加游戏 .rpx 文件所在根目录(如 D:\wiiu\games\botw\code\U-King.rpx,则添加 D:\wiiu\games 就行),刷新后游戏就会显示在列表之中。
安装 DLC:通过 File > Install game title, update or DLC 安装
Cemu vs Yuzu (Zelda BOTW) 说:At this moment, the Wii U version played on Cemu is the superior one in both performance and quality. 实际体验也确实如此。
根据 Zelda BOTW runs way better for me on Yuzu than on Cemu 讨论,为更好性能,需要安装并启用 Graphic packs。导航到 Options > Graphic packs,启用对应游戏的(保持默认配置就行):
- Enhancements
- Graphics
- Mods.Extended Memory
- Mods.FPS++
运行游戏会发现,在实时编译 shaders 和 vkpipeline 时会卡顿:
- 搜索 “Shader caches” 可解决这个问题;每次启动游戏都会加载 cache,首次加载比较慢,下次就快多了。
- shaders 通过 transferable shader cache 解决。首先需要在网上找对应游戏他人分享的 Shader caches,不同地区(日版、美版、欧版)的 shader cache 是通用的,Shader caches 越全越好(越大越好)。先运行一下游戏,会在
cemu\shaderCache\transferable建立两个 bin 文件,如 xxx_shaders.bin 和 xxx_vkpipeline.bin,将下载解压后的 bin 文件重命名为游戏创建的 xxx_shaders.bin 文件并替换该文件。再次运行游戏,如果显示 complie cache shader 并且cemu\shaderCache\transferable\xxx_shaders.bin大小没有变为 0 的话,说明成功了。 - vkpipeline 可通过启用 Options > General settings > Graphics > Async shader complie 解决。启用该功能可能需要安装最新 NVIDIA 显卡驱动(看报不报错)。
你会发现不能退出游戏 go back to the Cemu main menu,这是可能原因:I would think they did it that way for easeof development. For example on yuzu if you exit to main menu it will not allocate the ram correctly. Meaning if you launch a game and it uses 8gb of ram then exit to a new one, without fully closing yuzu, yuzu would use and extra 8gb of ram on top of that.
在 [汉化] 【91Wii 索引】WiiU 游戏汉化补丁及中文游戏资源索引帖 下载解压汉化包后,覆盖掉原游戏根目录中对应的原文件就可以使用了。
攻略本(Strategy guide),或称攻略,是指收录特定电子游戏提示或完整解的说明书,内容环绕一款或多款电子游戏的过关方法、注意点等。塞尔达传说:旷野之息专区_攻略及图文秘籍_电玩帮
游戏模组,这个游戏术语源自英文缩略词“MOD”、“Mod”(全称“Modification”,本意为“修改”),多指游戏厂商或者热心玩家对于原版电子游戏在功能方面的修改。
yuzu
yuzu 是 Citra的制作者写的一个开源NS模拟器,用C++编写,特点包括Vulkan API的支持、灵活的模拟器配置以及游戏配置等等。
玩了 super mario odyssey,过场动画很卡顿,可以软配置的很少,主要看硬件配置,我的配置玩 BOTW 是不可能了。
安装
-
选择 File -> Open yuzu Folder
-
在打开的目录下,新建 keys 文件夹(如果没有),然后进入 keys 文件夹,放入 key 文件 prod.keys,内容如下
aes_kek_generation_source = 4d870986c45d20722fba1053da92e8a9 aes_key_generation_source = 89615ee05c31b6805fe58f3da24f7aa8 bis_kek_source = 34c1a0c48258f8b4fa9e5e6adafc7e4f bis_key_00 = 374e0e2ab275141f811badcb0fefd881b71d6af540de58895901aa0c01663bc8 bis_key_01 = 0b08f19a42ac5ae590b3373ad9698344a571f35165663536dae0842b5221b31c bis_key_02 = 38f0936f33bacedc0c0a159ffbbeee0f40bb08386915bdd0c6730349b99081ec bis_key_03 = 38f0936f33bacedc0c0a159ffbbeee0f40bb08386915bdd0c6730349b99081ec bis_key_source_00 = f83f386e2cd2ca32a89ab9aa29bfc7487d92b03aa8bfdee1a74c3b6e35cb7106 bis_key_source_01 = 41003049ddccc065647a7eb41eed9c5f44424edab49dfcd98777249adc9f7ca4 bis_key_source_02 = 52c2e9eb09e3ee2932a10c1fb6a0926c4d12e14b2a474c1c09cb0359f015f4e4 device_key = bd16c45b2647d842c5ee3c869e3a9607 device_key_4x = 2078900c6bb36fff1fdad57a7dd1b66e eticket_rsa_kek = 19c8b441d318802bad63a5beda283a84 eticket_rsa_kek_source = dba451124ca0a9836814f5ed95e3125b eticket_rsa_kekek_source = 466e57b74a447f02f321cde58f2f5535 header_kek_source = 1f12913a4acbf00d4cde3af6d523882a header_key = aeaab1ca08adf9bef12991f369e3c567d6881e4e4a6a47a51f6e4877062d542d header_key_source = 5a3ed84fdec0d82631f7e25d197bf5d01c9b7bfaf628183d71f64d73f150b9d2 key_area_key_application_00 = ef979e289a132c23d39c4ec5a0bba969 key_area_key_application_01 = cdedbab97b69729073dfb2440bff2c13 key_area_key_application_02 = 75716ed3b524a01dfe21456ce26c7270 key_area_key_application_03 = f428306544cf5707c25eaa8bc0583fd1 key_area_key_application_04 = 798844ec099eb6a04b26c7c728a35a4d key_area_key_application_05 = a57c6eecc5410ada22712eb3ccbf45f1 key_area_key_application_06 = 2a60f6c4275df1770651d5891b8e73ec key_area_key_application_07 = 32221bd6ed19b938bec06b9d36ed9e51 key_area_key_application_08 = fb20aa9e3dbf67350e86479eb431a0b3 key_area_key_application_09 = ce8d5fa79e220d5f48470e9f21be018b key_area_key_application_0a = 38b865725adcf568a81d2db3ceaa5bcc key_area_key_application_0b = bbddfd40a59d0ff555c0954239972213 key_area_key_application_0c = 3fee7204e21c6b0ff1373226c0c3e055 key_area_key_application_source = 7f59971e629f36a13098066f2144c30d key_area_key_ocean_00 = b33813e4c9c4399c75fabc673ab4947b key_area_key_ocean_01 = c54166efa8c9c0f6511fa8b580191677 key_area_key_ocean_02 = 3061ce73461e0b0409d6a33da85843c8 key_area_key_ocean_03 = 06f170025a64921c849df168e74d37f2 key_area_key_ocean_04 = dc857fd6dc1c6213076ec7b902ec5bb6 key_area_key_ocean_05 = 131d76b70bd8a60036d8218c15cb610f key_area_key_ocean_06 = 17d565492ba819b0c19bed1b4297b659 key_area_key_ocean_07 = 37255186f7678324bf2b2d773ea2c412 key_area_key_ocean_08 = 4115c119b7bd8522ad63c831b6c816a6 key_area_key_ocean_09 = 792bfc652870cca7491d1685384be147 key_area_key_ocean_0a = dfcc9e87e61c9fba54a9b1c262d41e4d key_area_key_ocean_0b = 66fe3107f5a6a8d8eda2459d920b07a1 key_area_key_ocean_0c = b79b6bf3d6cdc5ec10277fc07a4fec93 key_area_key_ocean_source = 327d36085ad1758dab4e6fbaa555d882 key_area_key_system_00 = 6dd02aa15b440d6231236b6677de86bc key_area_key_system_01 = 4ab155e7f29a292037fd147592770b12 key_area_key_system_02 = b7a74adeaf89c2a198c327bdff322d7d key_area_key_system_03 = d5aab1acd23a8aec284a316df859d377 key_area_key_system_04 = 9b44b45b37de9d14754b1d22c2ca742c key_area_key_system_05 = 0012e957530d3dc7af34fbbe6fd44559 key_area_key_system_06 = 01744e3b0818445cd54ee9f89da43192 key_area_key_system_07 = d0d30e46f5695b875f11522c375c5a80 key_area_key_system_08 = bd06cb1b86bd5c433667470a09eb63de key_area_key_system_09 = e19f788f658eda8bbf34a1dd2a9503a9 key_area_key_system_0a = 7070e7ff5cfe448630143a9874903c38 key_area_key_system_0b = 3fa471d4483e58b8f7756fcb64f63890 key_area_key_system_0c = 7bfd381df3369407ab1c6bdd9fabf522 key_area_key_system_source = 8745f1bba6be79647d048ba67b5fda4a keyblob_00 = f759024f8199101dddc1ef91e6eecf37e24b95ac9272f7ae441d5d8060c843a48322d21cdd06d4fc958c68d3800eb4db939ffbec930177f77d136144ff615aa8835e811bb958deda218f8486b5a10f531b30cb9d269645ac9fc25c53fc80525e56bd3602988a9fcf06bbf99ca910ad6530791d512c9d57e17abf49220de6419bf4eca1685c1e4df77f19db7b44a985ca keyblob_01 = bd27264ae07e979756411d0c66e679e3c50851f3e902d9c2cd1a438b948159a517ec1566c10570326ea2697ee62da46f14bb5d581bfc06fd0c9387ea33d2d4dc63e7809ba90f03dd2c7112ffbfa548951b9b8c688b5e4f2951d24a73da29c668154a5d4838dba71ee068ace83fe720e8c2a495c596f73525dc3c05994b40ad27f8c60322f75cd548b821af9162e16f76 keyblob_02 = a3d4a8e153b8e6ae6e6aef3e8f219cb4b7790f47856accc76268f9afa99a1ff8b1a72f63d1f99f480a3c1532078bb59abdd25203cfb12a38b33e9ba6a09afb6f24283b3ba76a0161230a73669ddf5493c2b7919d094fd795b484794854f71e4f4c672245d7770e29397722444d111b4229cdbf35707b70634ea8f140766e884cc580cb1e2d9aa9866ffef920010fc409 keyblob_03 = 1558f525ae8c5be9243fb6d8a8b0a8ee0e886a59035668740a936619b7a5c83e821198b171d18e51445054df68688e45703b936818a827d8e540dd6bef2e11ec9ddc6cfe5fc736dd769b9f6e0a23a62e2e5f49e86143646a04ec3a23f828373a336a5c224a91f8a0c6c6a7b5844dd6415804209f83c943aeca9cfd856db6bd4ec32009c8cb268ed053052c9237dfd8bc keyblob_04 = 9fbeb1957fc1629e08b753a9086d6e01ffb4f11466b7417e3fa7f5f1efb754406704fd75afaf91a408a0b524c1fc80d36c2046fa4757412efe4c11e382f72e8a10d90ed580017d9deb87af2549b6b02661af48ff94f6072c0fef7fc2833b8bdae503898e2e927ac0663e8b6391dd4f1d685313935e2c48ece7d177c88bc9c883ede36c3677495784b838d7265c6ba7a1 keyblob_05 = 94a92da1d73c2b3e165c891ced5607fc6628ca2a0654f3fbc05711c063377c6e9c96a9d0192e530dd510e4fd41aa62ef4213c5f6e059e7e21db098a9b22d1e6c29bee148aaef15c52549d9165de96e85b0d029ecdc5843e2f32cb18be707eec61909cf3385d45bc2a4c8d76e9bfad5a40c4b92dcb982aa50d474897ac9ebb5351a7015dcc277a08f1214ad41384d7941 keyblob_key_00 = 839944c8a38df6791020b38147e906b0 keyblob_key_01 = b9e6fbde828b5f42c897ade8fd14c625 keyblob_key_02 = b6988a0795d294ef522908692d5db7ca keyblob_key_03 = 0e57d7777171d125d3fe3af5b397d009 keyblob_key_04 = b55a282d698fabeb4e03c67ff2026bc5 keyblob_key_05 = fdb542c1f1bdf134ec20b1fda02bc9e1 keyblob_key_source_00 = df206f594454efdc7074483b0ded9fd3 keyblob_key_source_01 = 0c25615d684ceb421c2379ea822512ac keyblob_key_source_02 = 337685ee884aae0ac28afd7d63c0433b keyblob_key_source_03 = 2d1f4880edeced3e3cf248b5657df7be keyblob_key_source_04 = bb5a01f988aff5fc6cff079e133c3980 keyblob_key_source_05 = d8cce1266a353fcc20f32d3b517de9c0 keyblob_mac_key_00 = 604422526723e541a849fa4c18660e0b keyblob_mac_key_01 = 279481456b1dc259d35599e6392e01e5 keyblob_mac_key_02 = dbbfb8096b676c2a54b5d9c61b423a94 keyblob_mac_key_03 = 48b7aef6d9b1edb132b8901a245a7750 keyblob_mac_key_04 = 544c082e9f8602c736dc0732d4319f88 keyblob_mac_key_05 = a540ec8ba84bd31eaaa9ce9f95226875 keyblob_mac_key_source = 59c7fb6fbe9bbe87656b15c0537336a5 mariko_master_kek_source_05 = 77605ad2ee6ef83c3f72e2599dac5e56 mariko_master_kek_source_06 = 1e80b8173ec060aa11be1a4aa66fe4ae mariko_master_kek_source_07 = 940867bd0a00388411d31adbdd8df18a mariko_master_kek_source_08 = 5c24e3b8b4f700c23cfd0ace13c3dc23 mariko_master_kek_source_09 = 8669f00987c805aeb57b4874de62a613 mariko_master_kek_source_0a = 0e440cedb436c03faa1daebf62b10982 mariko_master_kek_source_0b = e541acecd1a7d1abed0377f127caf8f1 mariko_master_kek_source_0c = 52719bdfa78b61d8d58511e48e4f74c6 master_kek_00 = f759024f8199101dddc1ef91e6eecf37 master_kek_01 = bd27264ae07e979756411d0c66e679e3 master_kek_02 = a3d4a8e153b8e6ae6e6aef3e8f219cb4 master_kek_03 = 1558f525ae8c5be9243fb6d8a8b0a8ee master_kek_04 = 9fbeb1957fc1629e08b753a9086d6e01 master_kek_05 = 94a92da1d73c2b3e165c891ced5607fc master_kek_08 = e42f1ec8002043d746575ae6dd9f283f master_kek_09 = cec2885fbeef5f6a989db84a4cc4b393 master_kek_0a = dd1a730232522b5cb4590cd43869ab6a master_kek_0b = fc6f0c891d42710180724ed9e112e72a master_kek_0c = 43f7fc20fcec22a5b2a744790371b094 master_kek_source_06 = 374b772959b4043081f6e58c6d36179a master_kek_source_07 = 9a3ea9abfd56461c9bf6487f5cfa095c master_kek_source_08 = dedce339308816f8ae97adec642d4141 master_kek_source_09 = 1aec11822b32387a2bedba01477e3b67 master_kek_source_0a = 303f027ed838ecd7932534b530ebca7a master_kek_source_0b = 8467b67f1311aee6589b19af136c807a master_kek_source_0c = 683bca54b86f9248c305768788707923 master_key_00 = c2caaff089b9aed55694876055271c7d master_key_01 = 54e1b8e999c2fd16cd07b66109acaaa6 master_key_02 = 4f6b10d33072af2f250562bff06b6da3 master_key_03 = 84e04ec20b9373818c540829cf147f3d master_key_04 = cfa2176790a53ff74974bff2af180921 master_key_05 = c1dbedcebf0dd6956079e506cfa1af6e master_key_06 = 0aa90e6330cdc12d819b3254d11a4e1e master_key_07 = 929f86fbfe4ef7732892bf3462511b0e master_key_08 = 23cfb792c3cb50cd715da0f84880c877 master_key_09 = 75c93b716255319b8e03e14c19dea64e master_key_0a = 73767484c73088f629b0eeb605f64aa6 master_key_0b = 8500b14bf4766b855a26ffc614097a8f master_key_0c = b3c503709135d4b35de31be4b0b9c0f7 master_key_source = d8a2410ac6c59001c61d6a267c513f3c package1_key_00 = f4eca1685c1e4df77f19db7b44a985ca package1_key_01 = f8c60322f75cd548b821af9162e16f76 package1_key_02 = c580cb1e2d9aa9866ffef920010fc409 package1_key_03 = c32009c8cb268ed053052c9237dfd8bc package1_key_04 = ede36c3677495784b838d7265c6ba7a1 package1_key_05 = 1a7015dcc277a08f1214ad41384d7941 package2_key_00 = a35a19cb14404b2f4460d343d178638d package2_key_01 = a0dd1eacd438610c85a191f02c1db8a8 package2_key_02 = 7e5ba2aafd57d47a85fd4a57f2076679 package2_key_03 = bf03e9889fa18f0d7a55e8e9f684323d package2_key_04 = 09df6e361e28eb9c96c9fa0bfc897179 package2_key_05 = 444b1a4f9035178b9b1fe262462acb8e package2_key_06 = 442cd9c21cfb8914587dc12e8e7ed608 package2_key_07 = 70c821e7d6716feb124acbac09f7b863 package2_key_08 = 8accebcc3d15a328a48365503f8369b6 package2_key_09 = f562a7c6c42e3d4d3d13ffd504d77346 package2_key_0a = 0803167ec7fc0bc753d8330e5592a289 package2_key_0b = 341db6796aa7bdb8092f7aae6554900a package2_key_0c = 4e97dc4225d00c6ae33d49bddd17637d package2_key_source = fb8b6a9c7900c849efd24d854d30a0c7 per_console_key_source = 4f025f0eb66d110edc327d4186c2f478 retail_specific_aes_key_source = e2d6b87a119cb880e822888a46fba195 rsa_oaep_kek_generation_source = a8ca938434127fda82cc1aa5e807b112 rsa_private_kek_generation_source = ef2cb61a56729b9157c38b9316784ddd save_mac_kek_source = d89c236ec9124e43c82b038743f9cf1b save_mac_key = 71a917f1bac8f4f04d732e734c90e2ec save_mac_key_source = e4cd3d4ad50f742845a487e5a063ea1f save_mac_sd_card_kek_source = 0489ef5d326e1a59c4b7ab8c367aab17 save_mac_sd_card_key_source = 6f645947c56146f9ffa045d595332918 sd_card_custom_storage_key_source = 370c345e12e4cefe21b58e64db52af354f2ca5a3fc999a47c03ee004485b2fd0 sd_card_kek_source = 88358d9c629ba1a00147dbe0621b5432 sd_card_nca_key_source = 5841a284935b56278b8e1fc518e99f2b67c793f0f24fded075495dca006d99c2 sd_card_save_key_source = 2449b722726703a81965e6e3ea582fdd9a951517b16e8f7f1f68263152ea296a sd_seed = fdb479221c43741a118fb5475374d2f7 secure_boot_key = 208de9b9de94ff698d00657a6a82a973 ssl_rsa_kek = b011100660d1dccbad1b1b733afa9f95 ssl_rsa_kek_source_x = 7f5bb0847b25aa67fac84be23d7b6903 ssl_rsa_kek_source_y = 9a383bf431d0bd8132534ba964397de3 titlekek_00 = 62a24d6e6d0d0e0abf3554d259be3dc9 titlekek_01 = 8821f642176969b1a18021d2665c0111 titlekek_02 = 5d15b9b95a5739a0ac9b20f600283962 titlekek_03 = 1b3f63bcb67d4b06da5badc7d89acce1 titlekek_04 = e45c1789a69c7afbbf1a1e61f2499459 titlekek_05 = ddc67f7189f4527a37b519cb051eee21 titlekek_06 = b1532b9d38ab036068f074c0d78706ac titlekek_07 = 81dc1b1783df268789a6a0edbf058343 titlekek_08 = 47dfe4bf0eeda88b17136b8005ab08ea titlekek_09 = adaa785d90e1a9c182ac07bc276bf600 titlekek_0a = 42daa957c128f75bb1fda56a8387e17b titlekek_0b = d08903363f2c8655d3de3ccf85d79406 titlekek_0c = be2682599db34caa9bc7ebb2cc7c654c titlekek_source = 1edc7b3b60e6b4d878b81715985e629b tsec_key = 53ec4ac7c6c32ff2abff3eeff4f84f36 tsec_root_key_02 = 4b4fbcf58e23cf4902d478b76c8048ecyuzu以及Ryujinx都需要prod.keys,里面包含了NS设备需要的key,需要通过Hekate等一些列工具生成。yuzu 不需要单独安装固件,只要把 key 文件放好就可以启动游戏了。 -
关闭模拟器,重新打开 yuzu ,若没有弹窗,则配置成功
设置
General
确保勾选 Multicore CPU Emulation 和 Confirm exit while emulation is runing。
Limit Speed percent:游戏运行速度,默认即可,可加快或限速
Pause emulation when inbackground:退到后台模拟器暂停运行
Hide mouse inactivity:运行时鼠标隐藏
Prompt for user for game boot:游戏启动时选择哪个账户游玩
Web
yuzu web service:填了用户名和令牌以后可以向官网报告游戏兼容性
Telemetry:开了以后能让 yuzu 开发者查看你的使用情况,以便改善模拟器
Discord Presence:在 discord 中显示你的游戏状态
系统
System 页面,Language 选择 Simplified Chinese,Region 选择 China。这个设置的是系统语言,很多游戏会根据系统语言自动切换游戏内显示的语言。当然前提是游戏本身包含中文,如果游戏本身无中文只能通过打补丁的方式显示中文。
Custom RTC:修改系统时间,可以触发某些游戏的特定彩蛋之类的功能。
RNG seed:随机数种子,一般情况别改改。
Profile Manager:这里可以改 switch 用户名称、头像。可以设置多个用户
CPU
图形
API设置:支持OpenGL和Vulkan。Use disk shader cache:磁盘着色器缓存,建议开启,这样就不用每次都重新编译,而是直接从磁盘加载到内存Use asynchronous GPU emulation:GPU异步模拟,yuzu重写了GPU显存管理器,加速了缓存机制,使得帧数得到明显提示,同时性能提升 40%-400%(来自BSoD Gaming的测试数据)Use NVDEC emulation:NVDEC是一项硬件转码技术,能减少转码期间计算密集型任务中 CPU 的负担,这是Nvidia的一个技术,有了它,过场动画的播放会畅顺很多
Advanced
Accuracy Level:即模拟器左下角状态栏的 GPU NORMAL。是处理图形绘制精确度,开启 High 可能会修复一些图形错误,但是速度可能会变慢,一般选默认 Normal 即可Use Vysnc (OpenGL Only):开启垂直同步Use Fast GPU time: 使用 GPU 加速渲染Anisotropic Filtering:是各项异性过滤,是用来处理图形纹理错误的,可以选 2x-16x
声音
默认。
控制
连接手柄,选择该设备。
管理
游戏格式分为两种,.xci 格式和 .nsp 格式。简单一点说,.xci 格式是卡带版,.nsp 格式是数字版。因此基本上所有的 DLC 基本都是 .nsp 格式,但也有 .xci 里集成了 DLC 的情况。
添加游戏
双击模拟器中间,添加游戏目录,游戏目录也不要有中文。添加完就可以看到游戏了。
安装 Update 和 DLC
选择 File ->Install Files to NAND…,选中 Update 和 DLC 文件,Update 安装最新就行,DLC 需要全部安装(可以不按顺序)。
安装 Mod
Mod 用于修改游戏,如解决一些 bug 以及优化性能等。右键单击要为其添加模组的游戏。然后将整个 mod 文件夹粘贴到那里。你可以从 Switch Mods 获得一些基本的 yuzu 模组。
注意:您可以通过右键单击游戏并单击属性来检查您拥有的游戏模组。
放入着色器缓存
放入着色器缓存(shader cache)可以明显提升游戏的流畅性,建议找找别人的着色器缓存。
具体放入步骤:右键某个游戏,选择打开可转移着色器缓存,即可弹出缓存所在文件夹,然后放入你下载的别人的缓存就行了,比如 vulkan.bin 和 opengl.bin
rubick
基于 electron 的开源工具箱,自由集成丰富插件。
uTools
uTools 是一个极简、插件化的现代桌面软件,通过自由选配丰富的插件,打造得心应手的工具集合。
Albert
Linux 下的快捷启动工具。
| 应用 / 功能 | 查找应用 | 查找文件 | 查找网页 | 扩展程序 |
|---|---|---|---|---|
| Albert | ✓ | ✓ | ✓ | - |
| Synapse | ✓ | ✓ | - | - |
| Utools | ✓ | ✗ | ✓ | ✓ |
| Ulauncher | ✓ | ✓ | ✓ | ✓ |
| FSearch | ✗ | ✓ | ✗ | ✗ |
简单说,Albert 最好用,Ulauncher 综合能力强,而 FSearch 严重偏科。
Calibre
calibre is a powerful and easy to use e-book manager. Users say it’s outstanding and a must-have. It’ll allow you to do nearly everything and it takes things a step beyond normal e-book software. It’s also completely free and open source and great for both casual users and computer experts.
Open terminal and run the following command to install Calibre.
sudo apt update
sudo apt install calibre
Calibre software is referred to as ebook-convert command. Here is the command to convert epub file to pdf file.
ebook-convert <file>.epub <file>.pdf
If your PDF doesn’t appear to be properly readable, try converting the epub file again using –enable-heuristics option.
ebook-convert /home/ubuntu/test.epub /home/ubuntu/test.pdf --enable-heuristics
FBReader
中文乱码需要在 Options => CSS 中启用 Always Use My Own Fonts
Ventoy
简单来说,Ventoy 是一个制作可启动 U 盘的开源工具。
有了 Ventoy 你就无需反复地格式化 U 盘,你只需要把 ISO/WIM/IMG/VHD(x)/EFI 等类型的文件直接拷贝到 U 盘里面就可以启动了,无需其他操作。
balenaEtcher
Supported Operating Systems
- Linux (most distros)
- macOS 10.10 (Yosemite) and later
- Microsoft Windows 7 and later
UNetbootin
UNetbootin installs Linux/BSD distributions to a partition or USB drive
WoeUSB-ng
WoeUSB-ng is a simple tool that enable you to create your own usb stick windows installer from an iso image or a real DVD. This is a rewrite of original WoeUSB.
Timeshift
System restore tool for Linux.
Todoist
Plank
Plank is meant to be the simplest dock on the planet.
latte-dock
Steam
sudo apt install steam
在 Windows 上运行神秘代码: Win + R,输入 steam://install/2026560。等同于在 Ubuntu 终端敲:xdg-open steam://install/2026560
`YACReader
Tachidesk
Tachidesk 是一个免费的开源漫画阅读器,可运行为 Tachiyomi 构建的扩展。Tachidesk 是独立的,但与 Tachiyomi 兼容的开源软件,它不是 Tachiyomi 的下游分支。你可以在任何支持 Java 的设备上运行这个软件。
如果你熟悉 Tachiyomi,那你也会对 Tachidesk 的用户界面倍感熟悉。
Tachidesk 主要分为两部分:Tachidesk-server (后端)和 Tachidesk 图形化前端。Tachidesk 有多个图形化前端。直接从下文的 GitHub 链接下载的文件会自动集成一个 Tachidesk-WebUI。
hakuneko
work_crawler
Download comics novels
dingtalk
钉钉桌面版,基于 electron 和钉钉网页版开发
howdy
Windows Hello™ style facial authentication for Linux
向日葵
向日葵远程控制软件是一款免费的集远程控制电脑手机、远程桌面连接、远程开机、远程管理、支持内网穿透的一体化远程控制管理工具软件。
KeePassXC
words-picker
有 OCR 功能的开源取词软件
CopyQ
Clipboard manager with advanced features
XnViewMP
图片浏览器。速度快,并且可以进行一些简单的图片操作,比如图片压缩、图片格式转换、图片剪裁等等。
Zeal
离线 API 文档查找阅读工具。
XMind
XMind 是一款全功能的思维导图和头脑风暴软件。像大脑的瑞士军刀一般,助你理清思路,捕捉创意。已成为上亿用户喜爱的全平台效率工具。
快捷键:
- shift:左右移动
- tab:subtopic
- del:delete topic
- blank:input text
XMind 8 使用 Java,提供更好的跨平台性,注意 xmind.ini 用的是相对路径,要么改为绝对路径,要么将工作目录切换到执行目录。
如果平时没有导出需求的话, 可以选用 xmind 和 mindmaster, 如果突然需要导出 pdf 了, 可以将 xmind 和 mindmaster 的文件导出为 mindmanager 文件, 然后导入到 freeplane 中, 稍作调整与美化, 然后导出成 pdf 就可以了.
desktop
[Desktop Entry]
Name=Xmind
Exec=/home/kurome/.opt/xmind/XMind.AppImage %U
Terminal=false
Type=Application
Icon=xmind
StartupWMClass=Xmind
StartupNotify=true
Comment=Xmind - The most popular mind mapping software.
MimeType=application/xmind;x-scheme-handler/xmind;x-scheme-handler/xmind-zen;
Categories=Office;
在 Gnome 中的 Nautilus 中的 Open With Other Application 列表只会显示 Exec 的值带 %U 的程序,在 KDE 中则显示所有 desktop 文件。
Add new file extension to existing (MIME) type
问题描述:将 zip 文件默认打开设置为 File,点击 xmind 文件会被解压;设置 xmind 默认打开 .xmind 文件,zip 文件会被 xmind 打开,xmind 的 mime 类型为 zip,那么要如何区分 zip 文件与 xmind 文件呢?
Use freedesktop’s unified system to define a new association. Write a new source xml file e.g.
gedit ~/.local/share/mime/packages/x-xmind.xml
with the following content:
<?xml version="1.0"?>
<mime-info xmlns='http://www.freedesktop.org/standards/shared-mime-info'>
<mime-type type="application/x-xmind">
<comment>XMind mindmap</comment>
<generic-icon name="package-x-generic"/>
<glob pattern="*.xmind"/>
</mime-type>
</mime-info>
then update your mime database
update-mime-database ~/.local/share/mime
or you can register a new MIME entry by using xdg-mime instead of update-mime-database:
# register
$ xdg-mime install x-xmind.xml
# unregister
$ xdg-mime uninstall x-xmind.xml
Query:
$ xdg-mime query filetype my.xmind
application/x-xmind
给 XMind 脑图文件添加 Gnome 缩略图显示 [Ubuntu]
CLI Utilities
PostgreSQL
是 macOS Server 的默认数据库。
安装
sudo apt install postgresql postgresql-contrib
postgresql-contrib 或者说 contrib 包,包含一些不属于 PostgreSQL 核心包的实用工具和功能。
通过 service 命令,你可以启动、关闭或重启 postgresql。输入 service postgresql 并按回车将列出所有选项
默认情况下,PostgreSQL 会创建一个拥有所权限的特殊用户 postgres。要实际使用 PostgreSQL,你必须先登录该账户,使用 psql 来启动 PostgreSQL Shell:
sudo -i -u postgres # sudo -login -user postgres
psql
使用 \l 用于查看已经存在的数据库
postgres=# \l
使用 \c + 数据库名 来进入数据库
postgres=# \c shop
\d 查看表格信息
postgres=# \d [TableName]
查找配置文件
select name, setting from pg_settings where category='File Locations' ;
Questions
psql: error: FATAL: Peer authentication failed for user “postgres”
psql 的连接建立于 Unix Socket 上默认使用 peer authentication(对等体认证;对等实体认证),所以必须要用和数据库用户相同的系统用户进行登录。
# su - postgres
# psql
或者将 peer authentiction 改为 md5,需先做上面步骤,更改密码:
postgres=# ALTER USER db_user with password 'db_password';
$ find / -name 'pg_hba.conf' 2>/dev/null
$ sudo vi /etc/postgresql/12/main/postgresql.conf
local all postgres md5
$ systemctl restart postgresql.service
$ psql -U postgres -d shop
Ansible
安装 Ansible 之后,不需要启动或运行一个后台进程,或是添加一个数据库.只要在一台电脑(可以是一台笔记本)上安装好,就可以通过这台电脑管理一组远程的机器.在远程被管理的机器上,不需要安装运行任何软件,因此升级 Ansible 版本不会有太多问题.
fdupes
You can call it like fdupes -r /dir/ect/ory and it will print out a list of dupes. fdupes has also a simple Homepage and a Wikipedia article, which lists some more programs.
digiKam
可用于查找重复相片,然后根据需要删除重复内容。
bypy
bypy info 认证特别慢,而授权码又只有 10 分钟,导致后面授权码过期 Heroku server 认证失败失败。
如此,可以通过手动认证。
-
通过
bypy info -dv查看详细输出,得到 Full URL,如https://bypyoauth.herokuapp.com/auth?code=...&bypy_version=1.7.2&redirect_uri=oob,在浏览器中打开,获得 token。 -
将其放在
~/.bypy/bypy.json中。
源码仓库也有示例。
我下载一个大文件,总共 12G 左右,已用了两个晚上,中途没关(由于不是立马就要的东西,就用时间换金钱了),一次看进度时,Terminal 就卡退了,重新运行后,bypy 会继续上次下载,而不是重新开始(这样话太可怕了)。
FRP
frp 是一个专注于内网穿透的高性能的反向代理应用,支持 TCP、UDP、HTTP、HTTPS 等多种协议。可以将内网服务以安全、便捷的方式通过具有公网 IP 节点的中转暴露到公网。
Git
sync-repos
#!/usr/bin/bash
TIME="$(date '+%Y%m%d%H%M%S')"
SAMATOMO_SOURCE=$HOME/Documents/SakamotoKuromeSource
SAKAMOTO_PUBLIC=$SAMATOMO_SOURCE/public
VNOTEBOOK=$HOME/Documents/vNotebook
function Git_Sync() {
cd $1
echo '========================= STATUS ========================='
git status
echo '========================= PULL ========================='
git pull
echo '========================= PUSH ========================='
cat .gitignore_default > .gitignore
find . -size +100M | sed 's|^./||g' | cat >> .gitignore
git add .
git commit -m "Update-${TIME}"
git push -v
echo -e "\n\n\n\n"
}
function Sync_All() {
echo '############### (SAMATOMO_SOURCE) ###############'
Git_Sync $SAMATOMO_SOURCE
echo '############### (SAKAMOTO_PUBLIC) ###############'
rm -rf $SAKAMOTO_PUBLIC/*
hugo
Git_Sync $SAKAMOTO_PUBLIC
echo '############### (vNotebook) ###############'
Git_Sync $VNOTEBOOK
}
Sync_All
exit 0
- A collection of useful .gitignore templates
- Ignore files >100MB in your Git repos
- About large files on GitHub
GitHub Desktop
Focus on what matters instead of fighting with Git. Whether you’re new to Git or a seasoned user, GitHub Desktop simplifies your development workflow.
GitHub520
# GitHub520 Host Start
140.82.113.26 alive.github.com
140.82.113.26 live.github.com
185.199.108.154 github.githubassets.com
140.82.112.22 central.github.com
185.199.108.133 desktop.githubusercontent.com
185.199.108.153 assets-cdn.github.com
185.199.108.133 camo.githubusercontent.com
185.199.108.133 github.map.fastly.net
199.232.69.194 github.global.ssl.fastly.net
140.82.114.4 gist.github.com
185.199.108.153 github.io
140.82.113.4 github.com
192.0.66.2 github.blog
140.82.114.5 api.github.com
185.199.108.133 raw.githubusercontent.com
185.199.108.133 user-images.githubusercontent.com
185.199.108.133 favicons.githubusercontent.com
185.199.108.133 avatars5.githubusercontent.com
185.199.108.133 avatars4.githubusercontent.com
185.199.108.133 avatars3.githubusercontent.com
185.199.108.133 avatars2.githubusercontent.com
185.199.108.133 avatars1.githubusercontent.com
185.199.108.133 avatars0.githubusercontent.com
185.199.108.133 avatars.githubusercontent.com
140.82.114.10 codeload.github.com
52.217.201.185 github-cloud.s3.amazonaws.com
54.231.132.81 github-com.s3.amazonaws.com
52.217.225.9 github-production-release-asset-2e65be.s3.amazonaws.com
52.217.161.97 github-production-user-asset-6210df.s3.amazonaws.com
52.216.134.35 github-production-repository-file-5c1aeb.s3.amazonaws.com
185.199.108.153 githubstatus.com
64.71.144.202 github.community
23.100.27.125 github.dev
140.82.112.22 collector.github.com
13.107.42.16 pipelines.actions.githubusercontent.com
185.199.108.133 media.githubusercontent.com
185.199.108.133 cloud.githubusercontent.com
185.199.108.133 objects.githubusercontent.com
# Update time: 2022-03-19T14:06:28+08:00
# Update url: https://raw.hellogithub.com/hosts
# Star me: https://github.com/521xueweihan/GitHub520
# GitHub520 Host End
libguestfs
libguestfs 支持几乎所有类型的磁盘镜像。
在基于 Debian 的系统上:
apt-get install libguestfs-tools
我们可以像下面这样挂载一个 qcow2 格式的磁盘镜像:
guestmount -a /path/to/qcow2/image -m <device> /path/to/mount/point
要卸载它,则执行:
guestunmount qcow2_mount_poin
Oracle JDK
-
解压缩到目录
tar -zxv -f jdk-7u60-linux-x64.gz -C dir -
修改环境变量
$ vi ~/.bashrc export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60 # 这里换成自己解压的jdk 目录 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH -
使环境变量生效
source ~/.bashrc
Snapper
Snapper 是一个由 openSUSE 的 Arvin Schnell 开发的工具,用于管理 Btrfs 子卷和 LVM 精简配置(thin-provisioned)卷。它可以创建和比较快照,在快照间回滚,并支持自动按时间序列创建快照。
列出子卷列表
$ sudo btrfs subvolume list -p /
ID 256 gen 7746 parent 5 top level 5 path @
ID 258 gen 7746 parmount -n -o remount,rw /ent 5 top level 5 path @home
安装 snapper
sudo apt install snapper
创建配置文件,启用自动快照
sudo snapper -c root create-config /
Snapshots on boot
sudo systemctl status snapper-boot.timer
管理 snapshot
sudo snapper-gui
grub-btrfs
Include btrfs snapshots at boot options. (Grub menu)
教程:Install Ubuntu 21.04 with btrfs + snapper + grub-btrfs
Fail2Ban
Fail2Ban 是一款入侵防御软件,可以保护服务器免受暴力攻击。 它是用 Python 编程语言编写的。 Fail2Ban 基于 auth 日志文件工作,默认情况下它会扫描所有 auth 日志文件,如 /var/log/auth.log、/var/log/apache/access.log 等,并禁止带有恶意标志的 IP,比如密码失败太多,寻找漏洞等等标志。
通常,Fail2Ban 用于更新防火墙规则,用于在指定的时间内拒绝 IP 地址。 它也会发送邮件通知。 Fail2Ban 为各种服务提供了许多过滤器,如 ssh、apache、nginx、squid、named、mysql、nagios 等。
Fail2Ban 能够降低错误认证尝试的速度,但是它不能消除弱认证带来的风险。 这只是服务器防止暴力攻击的安全手段之一。
Syncthing
Syncthing是一款开源免费跨平台的文件同步工具,是基于P2P 技术实现设备间的文件同步,所以它的同步是去中心化的,即你并不需要一个服务器,故不需要担心这个中心的服务器给你带来的种种限制,而且类似于 torrent 协议,参与同步的设备越多,同步的速度越快。针对隐私问题,Syncthing 软件只会将数据存储于个人信任的设备上,不会存储到服务器上。设备之间的通信均通过 TLS 进行,Syncthing 还使用了完全正向保密技术来进一步保障你的数据安全。对于处于不同局域网之中的设备之间的文件同步,Syncthing 也提供了支持。
masscan
Masscan号称是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。
ImageMagick
Use ImageMagick to create, edit, compose, or convert digital images. It can read and write images in a variety of formats (over 200) including PNG, JPEG, GIF, WebP, HEIC, SVG, PDF, DPX, EXR and TIFF. ImageMagick can resize, flip, mirror, rotate, distort, shear and transform images, adjust image colors, apply various special effects, or draw text, lines, polygons, ellipses and Bézier curves.
p7zip
7-Zip is a file archiver with a high compression ratio.
p7zip 是 7-Zip 的 POSIX 系统移植,支持 Linux。
警告: 不要将 7z 格式用于备份目的,因为它不会保存文件的所有者/组。有关更多详细信息,请参见7z(1)。
添加文件或目录至已有的存档(或创建一个新的存档):
7z a <archive name> <file name>
也可以通过参数-p 设置密码,并通过标志-mhe = on 隐藏存档的结构:
7z a <archive name> <file name> -p -mhe=on
更新存档内已有的文件或添加新文件:
7z u <archive name> <file name>
列出存档内容:
7z l <archive name>
从存档中解压文件至当前文件夹,不使用存档内的目录结构:
7z e <archive name>
如果需要恢复存档内的目录结构,使用:
7z x <archive name>
解压至新的目录:
7z x -o<folder name> <archive name>
校验存档完整性:
7z t <archive name>
Differences between 7z, 7za and 7zr binaries
The package includes three binaries, /usr/bin/7z, /usr/bin/7za, and /usr/bin/7zr. Their manual pages explain the differences:
- 7z(1) uses plugins to handle archives.
- 7za(1) is a stand-alone executable that handles fewer archive formats than 7z.
- 7zr(1) is a stand-alone executable. It is a “light-version” of 7za that only handles 7z archives. In contrast to 7za, it cannot handle encrypted archives.
分卷压缩与解压缩
rar
# rar a -vSIZE 压缩后的文件名 被压缩的文件或者文件夹
# 最大限制为 12M
$ rar a -m5 -v12m myarchive myfiles
#解压
$ rar e myarchive.part1.rar
zip
How to unzip a multipart (spanned) ZIP on Linux?
The Linux unzip utility doesn’t really support multipart zips. From the manual:
Multi-part archives are not yet supported, except in conjunction with zip. (All parts must be concatenated together in order, and then
zip -F(for zip 2.x) orzip -FF(for zip 3.x) must be performed on the concatenated archive in order to “fix” it. Also, zip 3.0 and later can combine multi-part (split) archives into a combined single-file archive usingzip -s- inarchive -O outarchive. See the zip 3 manual page for more information.)
So you need to first concatenate the pieces, then repair the result. cat test.zip.* concatenates all the files called test.zip.* where the wildcard * stands for any sequence of characters; the files are enumerated in lexicographic order, which is the same as numerical order thanks to the leadings zeroes. >test.zip directs the output into the file test.zip.
cat test.zip.* > test.zip
zip -FF test.zip --out test-full.zip
unzip test-full.zip
If you created the pieces by directly splitting the zip file, as opposed to creating a multi-part zip with the official Pkzip utility, all you need to do is join the parts.
cat test.zip.* > test.zip
unzip test.zip
总结:使用 zip -s- inarchive -O outarchive,例如:
$ ls
archive.zip archive.z01 archive.z02 archive.z03
$ zip -s- archive.zip -O archive-full.zip
$ unzip archive-full.zip
tar
要将目录 logs 打包压缩并分割成多个 1M 的文件,可以用下面的命令:
tar cjf - logs/ | split -b 1m - logs.tar.bz2.
完成后会产生下列文件:
logs.tar.bz2.aa, logs.tar.bz2.ab, logs.tar.bz2.ac
要解压的时候只要执行下面的命令就可以了:
cat logs.tar.bz2.a* | tar xj
7z
压缩:
7z a name.7z filename -v10m
这里 a 是添加文件到压缩卷,name.7z 是压缩后文件,然后 filename 可以是文件夹或文件,-v10m 是限制每个包大小不超过 10m.
解压到当前目录:
7z x film.7z.001
Wudao-dict
有道词典的命令行版本,支持英汉互查和在线查询。
ascii-image-converter
ttyd
Share your terminal over the web
progress
Linux tool to show progress for cp, mv, dd, … (formerly known as cv)
vosk-api
Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node
convert MP3 to text
The software you can use is Vosk-api, a modern speech recognition toolkit based on neural networks. It supports 7+ languages and works on variety of platforms including RPi and mobile.
First you convert the file to the required format and then you recognize it:
ffmpeg -i file.mp3 -ar 16000 -ac 1 file.wav
Then install vosk-api with pip:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple vosk
Then use these steps:
git clone https://github.com/alphacep/vosk-api
cd vosk-api/python/example
curl -O http://alphacephei.com/vosk/models/vosk-model-small-en-us-0.15.zip
unzip vosk-model-small-en-us-0.15.zip
mv vosk-model-small-en-us-0.15 model
python3 ./test_simple.py test.wav > result.json
The result will be stored in json format.
The same directory also contains an srt subtitle output example, which is easier to evaluate and can be directly useful to some users:
python3 -m pip install srt
python3 ./test_srt.py test.wav
The example given in the repository says in perfect American English accent and perfect sound quality three sentences which I transcribe as:
one zero zero zero one
nine oh two one oh
zero one eight zero three
The “nine oh two one oh” is said very fast, but still clear. The “z” of the before last “zero” sounds a bit like an “s”.
The SRT generated above reads:
1
00:00:00,870 --> 00:00:02,610
what zero zero zero one
2
00:00:03,930 --> 00:00:04,950
no no to uno
3
00:00:06,240 --> 00:00:08,010
cyril one eight zero three
so we can see that several mistakes were made, presumably in part because we have the understanding that all words are numbers to help us.
Next I also tried with the vosk-model-en-us-0.22.zip which was a 1.8G download compared to 40M of vosk-model-small-en-us-0.15 and is listed at https://alphacephei.com/vosk/models:
mv model vosk-model-small-en-us-0.15
curl -O http://alphacephei.com/vosk/models/vosk-model-en-us-0.22.zip
unzip vosk-model-en-us-0.22.zip
mv vosk-model-en-us-0.22 model
and the result was:
1
00:00:00,840 --> 00:00:02,610
one zero zero zero one
2
00:00:04,026 --> 00:00:04,980
i know what you window
3
00:00:06,270 --> 00:00:07,980
serial one eight zero three
which got one more word correct.
inxi
inix 是一个用于获取 Linux 系统信息的终端命令。能够获取软件和硬件的详细信息,比如计算机型号、内核版本、发行版号以及桌面环境等信息,甚至可以读取主存模块占用主板的哪块 RAM 卡槽等详细信息。
inxi 还可以用于监控系统中正在消耗 CPU 或者内存资源的进程。
在 Ubuntu/Debian 发行版系统中,安装命令:
sudo apt install inxi
用 -F 参数可以获取详细的系统信息。几乎囊括了所有层次的系统信息。
inxi -F
BusyBox
BusyBox 是一个开源(GPL)项目,提供了近 400 个常用命令的简单实现,包括 ls、mv、ln、mkdir、more、ps、gzip、bzip2、tar 和 grep。它还包含了编程语言 awk、流编辑器 sed、文件系统检查工具 fsck、软件包管理器rpm 和 dpkg ,当然还有一个可以方便的访问所有这些命令的 shell(sh)。简而言之,它包含了所有 POSIX 系统需要的基本命令,以执行常见的系统维护任务以及许多用户和管理任务。
事实上,它甚至包含一个 init 命令,可以作为 PID 1 启动,以作为所有其它系统服务的父进程。换句话说,BusyBox 可以作为 systemd、OpenRC、sinit、init 和其他初始化系统的替代品。
BusyBox 非常小。作为一个可执行文件,它不到 1MB,所以它在嵌入式、边缘计算 和物联网领域很受欢迎,因为这些场景的存储空间是很宝贵的。在容器和云计算的世界里,它作为精简的 Linux 容器镜像的基础镜像也很受欢迎。
极简主义
BusyBox 的部分魅力在于它的极简主义。它的所有命令都被编译到一个二进制文件里(busybox),它的手册只有 81 页(根据我对 man 送到 pr 管道的计算),但它涵盖了近 400 条命令。
作为一个例子的比较,这是 “原版” 的 useradd —help 的输出:
-b, --base-dir BASE_DIR base directory for home
-c, --comment COMMENT GECOS field of the new account
-d, --home-dir HOME_DIR home directory of the new account
-D, --defaults print or change the default config
-e, --expiredate EXPIRE_DATE expiration date of the new account
-f, --inactive INACTIVE password inactivity
-g, --gid GROUP name or ID of the primary group
-G, --groups GROUPS list of supplementary groups
-h, --help display this help message and exit
-k, --skel SKEL_DIR alternative skeleton dir
-K, --key KEY=VALUE override /etc/login.defs
-l, --no-log-init do not add the user to the lastlog
-m, --create-home create the user's home directory
-M, --no-create-home do not create the user's home directory
-N, --no-user-group do not create a group with the user's name
-o, --non-unique allow users with non-unique UIDs
-p, --password PASSWORD encrypted password of the new account
-r, --system create a system account
-R, --root CHROOT_DIR directory to chroot into
-s, --shell SHELL login shell of the new account
-u, --uid UID user ID of the new account
-U, --user-group create a group with the same name as a user
而这是是同一命令的 BusyBox 版本:
-h DIR Home directory
-g GECOS GECOS field
-s SHELL Login shell
-G GRP Group
-S Create a system user
-D Don't assign a password
-H Don't create home directory
-u UID User id
-k SKEL Skeleton directory (/etc/skel)
这种差异是一种特性还是一种限制,取决于你是喜欢你的命令拥有 20 个选项还是 10 个选项。对于一些用户和某些用例来说,BusyBox 的极简主义刚刚满足所需。对于其他人来说,它是一个很好的最小化环境,可以作为一个后备工具,或者作为安装更强大的工具的基础,比如 Bash、Zsh、GNU Awk 等等。
Lynis
使用这个全面的开源安全审计工具检查你的 Linux 机器的安全性。
你有没有想过你的 Linux 机器到底安全不安全?Linux 发行版众多,每个发行版都有自己的默认设置,你在上面运行着几十个版本各异的软件包,还有众多的服务在后台运行,而我们几乎不知道或不关心这些。
要想确定安全态势(指你的 Linux 机器上运行的软件、网络和服务的整体安全状态),你可以运行几个命令,得到一些零碎的相关信息,但你需要解析的数据量是巨大的。
如果能运行一个工具,生成一份关于机器安全状况的报告,那就好得多了。而幸运的是,有一个这样的软件:Lynis。它是一个非常流行的开源安全审计工具,可以帮助强化基于 Linux 和 Unix 的系统。根据该项目的介绍:
“它运行在系统本身,可以进行深入的安全扫描。主要目标是测试安全防御措施,并提供进一步强化系统的提示。它还将扫描一般系统信息、易受攻击的软件包和可能的配置问题。Lynis 常被系统管理员和审计人员用来评估其系统的安全防御。”
安装 Lynis
你的 Linux 软件仓库中可能有 Lynis。如果有的话,你可以用以下方法安装它:
sudo apt install lynis
然而,如果你的仓库中的版本不是最新的,你最好从 GitHub 上安装它。事实上,Lynis 主要是用 shell 脚本来实现的。
运行 Lynis
通过给 Lynis 一个 -h 选项来查看帮助部分,以便有个大概了解:
sudo lynis -h
你会看到一个简短的信息屏幕,然后是 Lynis 支持的所有子命令。
接下来,尝试一些测试命令以大致熟悉一下。要查看你正在使用的 Lynis 版本,请运行:
$ sudo lynis show version
3.0.0
要查看 Lynis 中所有可用的命令:
$ sudo lynis show commands
Commands:
lynis audit
lynis configure
lynis generate
lynis show
lynis update
lynis upload-only
审计 Linux 系统
要审计你的系统的安全态势,运行以下命令:
sudo lynis audit system
这个命令运行得很快,并会返回一份详细的报告,输出结果可能一开始看起来很吓人,但我将在下面引导你来阅读它。这个命令的输出也会被保存到一个日志文件中,所以你可以随时回过头来检查任何可能感兴趣的东西。
Lynis 将日志保存在这里:
Files:
- Test and debug information : /var/log/lynis.log
- Report data : /var/log/lynis-report.dat
你可以验证是否创建了日志文件。它确实创建了:
$ ls -l /var/log/lynis.log
-rw-r-----. 1 root root 341489 Apr 30 05:52 /var/log/lynis.log
$ ls -l /var/log/lynis-report.dat
-rw-r-----. 1 root root 638 Apr 30 05:55 /var/log/lynis-report.dat
探索报告
Lynis 提供了相当全面的报告,所以我将介绍一些重要的部分。作为初始化的一部分,Lynis 做的第一件事就是找出机器上运行的操作系统的完整信息。之后是检查是否安装了什么系统工具和插件:
[+] Initializing program
------------------------------------
- Detecting OS... [ DONE ]
- Checking profiles... [ DONE ]
---------------------------------------------------
Program version: 3.0.0
Operating system: Linux
Operating system name: Red Hat Enterprise Linux Server 7.8 (Maipo)
Operating system version: 7.8
Kernel version: 3.10.0
Hardware platform: x86_64
Hostname: example
---------------------------------------------------
<<截断>>
[+] System Tools
------------------------------------
- Scanning available tools...
- Checking system binaries...
[+] Plugins (phase 1)
------------------------------------
Note: plugins have more extensive tests and may take several minutes to complete
- Plugin: pam
[..]
- Plugin: systemd
[................]
接下来,该报告被分为不同的部分,每个部分都以 [+] 符号开头。下面可以看到部分章节。(哇,要审核的地方有这么多,Lynis 是最合适的工具!)
[+] Boot and services
[+] Kernel
[+] Memory and Processes
[+] Users, Groups and Authentication
[+] Shells
[+] File systems
[+] USB Devices
[+] Storage
[+] NFS
[+] Name services
[+] Ports and packages
[+] Networking
[+] Printers and Spools
[+] Software: e-mail and messaging
[+] Software: firewalls
[+] Software: webserver
[+] SSH Support
[+] SNMP Support
[+] Databases
[+] LDAP Services
[+] PHP
[+] Squid Support
[+] Logging and files
[+] Insecure services
[+] Banners and identification
[+] Scheduled tasks
[+] Accounting
[+] Time and Synchronization
[+] Cryptography
[+] Virtualization
[+] Containers
[+] Security frameworks
[+] Software: file integrity
[+] Software: System tooling
[+] Software: Malware
[+] File Permissions
[+] Home directories
[+] Kernel Hardening
[+] Hardening
[+] Custom tests
Lynis 使用颜色编码使报告更容易解读。
- 绿色。一切正常
- 黄色。跳过、未找到,可能有个建议
- 红色。你可能需要仔细看看这个
在我的案例中,大部分的红色标记都是在 “Kernel Hardening” 部分找到的。内核有各种可调整的设置,它们定义了内核的功能,其中一些可调整的设置可能有其安全场景。发行版可能因为各种原因没有默认设置这些,但是你应该检查每一项,看看你是否需要根据你的安全态势来改变它的值:
[+] Kernel Hardening
------------------------------------
- Comparing sysctl key pairs with scan profile
- fs.protected_hardlinks (exp: 1) [ OK ]
- fs.protected_symlinks (exp: 1) [ OK ]
- fs.suid_dumpable (exp: 0) [ OK ]
- kernel.core_uses_pid (exp: 1) [ OK ]
- kernel.ctrl-alt-del (exp: 0) [ OK ]
- kernel.dmesg_restrict (exp: 1) [ DIFFERENT ]
- kernel.kptr_restrict (exp: 2) [ DIFFERENT ]
- kernel.randomize_va_space (exp: 2) [ OK ]
- kernel.sysrq (exp: 0) [ DIFFERENT ]
- kernel.yama.ptrace_scope (exp: 1 2 3) [ DIFFERENT ]
- net.ipv4.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.all.bootp_relay (exp: 0) [ OK ]
- net.ipv4.conf.all.forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.conf.all.mc_forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.proxy_arp (exp: 0) [ OK ]
- net.ipv4.conf.all.rp_filter (exp: 1) [ OK ]
- net.ipv4.conf.all.send_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.default.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.icmp_echo_ignore_broadcasts (exp: 1) [ OK ]
- net.ipv4.icmp_ignore_bogus_error_responses (exp: 1) [ OK ]
- net.ipv4.tcp_syncookies (exp: 1) [ OK ]
- net.ipv4.tcp_timestamps (exp: 0 1) [ OK ]
- net.ipv6.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv6.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.default.accept_source_route (exp: 0) [ OK ]
看看 SSH 这个例子,因为它是一个需要保证安全的关键领域。这里没有什么红色的东西,但是 Lynis 对我的环境给出了很多强化 SSH 服务的建议:
[+] SSH Support
------------------------------------
- Checking running SSH daemon [ FOUND ]
- Searching SSH configuration [ FOUND ]
- OpenSSH option: AllowTcpForwarding [ SUGGESTION ]
- OpenSSH option: ClientAliveCountMax [ SUGGESTION ]
- OpenSSH option: ClientAliveInterval [ OK ]
- OpenSSH option: Compression [ SUGGESTION ]
- OpenSSH option: FingerprintHash [ OK ]
- OpenSSH option: GatewayPorts [ OK ]
- OpenSSH option: IgnoreRhosts [ OK ]
- OpenSSH option: LoginGraceTime [ OK ]
- OpenSSH option: LogLevel [ SUGGESTION ]
- OpenSSH option: MaxAuthTries [ SUGGESTION ]
- OpenSSH option: MaxSessions [ SUGGESTION ]
- OpenSSH option: PermitRootLogin [ SUGGESTION ]
- OpenSSH option: PermitUserEnvironment [ OK ]
- OpenSSH option: PermitTunnel [ OK ]
- OpenSSH option: Port [ SUGGESTION ]
- OpenSSH option: PrintLastLog [ OK ]
- OpenSSH option: StrictModes [ OK ]
- OpenSSH option: TCPKeepAlive [ SUGGESTION ]
- OpenSSH option: UseDNS [ SUGGESTION ]
- OpenSSH option: X11Forwarding [ SUGGESTION ]
- OpenSSH option: AllowAgentForwarding [ SUGGESTION ]
- OpenSSH option: UsePrivilegeSeparation [ OK ]
- OpenSSH option: AllowUsers [ NOT FOUND ]
- OpenSSH option: AllowGroups [ NOT FOUND ]
我的系统上没有运行虚拟机或容器,所以这些显示的结果是空的:
[+] Virtualization
------------------------------------
[+] Containers
------------------------------------
Lynis 会检查一些从安全角度看很重要的文件的文件权限:
[+] File Permissions
------------------------------------
- Starting file permissions check
File: /boot/grub2/grub.cfg [ SUGGESTION ]
File: /etc/cron.deny [ OK ]
File: /etc/crontab [ SUGGESTION ]
File: /etc/group [ OK ]
File: /etc/group- [ OK ]
File: /etc/hosts.allow [ OK ]
File: /etc/hosts.deny [ OK ]
File: /etc/issue [ OK ]
File: /etc/issue.net [ OK ]
File: /etc/motd [ OK ]
File: /etc/passwd [ OK ]
File: /etc/passwd- [ OK ]
File: /etc/ssh/sshd_config [ OK ]
Directory: /root/.ssh [ SUGGESTION ]
Directory: /etc/cron.d [ SUGGESTION ]
Directory: /etc/cron.daily [ SUGGESTION ]
Directory: /etc/cron.hourly [ SUGGESTION ]
Directory: /etc/cron.weekly [ SUGGESTION ]
Directory: /etc/cron.monthly [ SUGGESTION ]
在报告的底部,Lynis 根据报告的发现提出了建议。每项建议后面都有一个 “TEST-ID”(为了下一部分方便,请将其保存起来)。
Suggestions (47):
----------------------------
* If not required, consider explicit disabling of core dump in /etc/security/limits.conf file [KRNL-5820]
https://cisofy.com/lynis/controls/KRNL-5820/
* Check PAM configuration, add rounds if applicable and expire passwords to encrypt with new values [AUTH-9229]
https://cisofy.com/lynis/controls/AUTH-9229/
Lynis 提供了一个选项来查找关于每个建议的更多信息,你可以使用 show details 命令和 TEST-ID 号来访问:
sudo lynis show details TEST-ID
这将显示该测试的其他信息。例如,我检查了 SSH-7408 的详细信息:
$ sudo lynis show details SSH-7408
2020-04-30 05:52:23 Performing test ID SSH-7408 (Check SSH specific defined options)
2020-04-30 05:52:23 Test: Checking specific defined options in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: added additional options for OpenSSH < 7.5
2020-04-30 05:52:23 Test: Checking AllowTcpForwarding in /tmp/lynis.k8JwazmKc6
2020-04-30 05:52:23 Result: Option AllowTcpForwarding found
2020-04-30 05:52:23 Result: Option AllowTcpForwarding value is YES
2020-04-30 05:52:23 Result: OpenSSH option AllowTcpForwarding is in a weak configuration state and should be fixed
2020-04-30 05:52:23 Suggestion: Consider hardening SSH configuration [test:SSH-7408] [details:AllowTcpForwarding (set YES to NO)] [solution:-]
试试吧
如果你想更多地了解你的 Linux 机器的安全性,请试试 Lynis。如果你想了解 Lynis 是如何工作的,可以研究一下它的 shell 脚本,看看它是如何收集这些信息的。
How can I protect against single user mode
Potential Attacks
Single User Mode
This is the easiest way to gain unauthorised access to a Linux system is to boot the server into Single User Mode because it does not, by default, require a root password to gain root level access. Single User Mood can be accessed by power cycling the machine and interrupting the boot process. To boot into single user mode where the GRUB bootloader is used perform the following; interrupt the boot process, press e to edit the boot configuration file, append to the line starting Linux one of either s, S, 1 or systemd. unit=[rescue.target, emergency.target, rescue] to change the argument being passed to the kernel during boot to boot into Single User Mode, then press ctrl+x.
Protecting Against Single User Mode
For a traditional init based system
As root edit the file /etc/sysconfig/init then on the line SINGLE=/sbin/sushell change sushell TO sulogin.
For a systemd based system
The target configuration need to be altered for the root password to be prompted for. The targets are located in /lib/systemd/system the files which need alteration are emergency.service and rescue.service. Alter the line starting ExecStart=-/bin/sh –c “/usr/sbin/sushell; ……” and change the /usr/sbin/sushell to/usr/sbin/sulogin in both emergency.service and rescue.service.
To check this has taken affect
Then save changes and reboot to confirm the alteration has taken affect, if the alteration was success when booting into single user mode it shall ask for the root password.
Root Password
By default, some Linux distributions do not have root password sets, this can be checked by running the command head -1 /etc/shadow and if the second column, using a colon as a delimiter, is an exclamation mark then no password has been set. If no root password is set, then regardless of if the system is set to prompt for a password for Single User Mode or not it will just load root access.
Securing Bootloader
Insecure bootloaders can result in the bootloader being bypassed completely and a shell being used to gain direct root level access to the system. This is done by interrupting the GRUB boot process and appending init=/bin/bas to the line beginning linux16. This will tell the kernel to use bash instead of init.
Protecting against bootloader side loading
The GRUB bootloader can be password protected by placing the configuration in /etc/grub.d/40_custom file because this file will remain un touched by updates and upgrades to the boot loader. In /etc/grub.d/40_custom add set superusers=”admin” then password admin after that save and exit the file and run the following command grub2-mkpasswd-… (allow tab completion to finish this command so that the system compatible script is run) the output of this command from grub2. Onwards need to be added to the end of the line password admin in /etc/grub.d/40_custom. After that the grub file need to be recompiled by running the command grub2-mkconfig –o /boot/grub2/grub.cfg for centos or update-grub¬ on debian.
To check this has taken affect
Then save changes and reboot to confirm the alteration has taken affect, if the alteration was success when booting and wanting to change the grub setting you will need to supply the username admin and the encrypted password.
Protecting Against Recovery Attack
These measures can aid in protection however, if a disk is used the recover Linux feature on the disk can be used to mount the file system and alter the GRUB setting from the disk. To protect against make any removable media have a lower boot priority than the boot drive and password protect the BIOS and boot option menu to stop someone who hasn’t got access altering the boot order and booting into a disk to make changes to the system.
CheckInstall
如果你已经从它的源码运行“make install”安装了 linux 程序。想完整移除它将变得真的很麻烦,除非程序的开发者在 Makefile 里提供了 uninstall 的目标设置。否则你必须在安装前后比较你系统里文件的完整列表,然后手工移除所有在安装过程中加入的文件。
这时候 Checkinstall 就可以派上使用。Checkinstall 会跟踪 install 命令行所创建或修改的所有文件的路径(例如:“make install”、“make install_modules”等)并建立一个标准的二进制包,让你能用你发行版的标准包管理系统安装或卸载它,请参考其官方文档。
安装 Checkinstall:
# apt install checkinstall
一旦 checkinstall 安装好,你就可以用下列格式创建一个特定的软件包
# checkinstall <install-command>
如果没有参数,默认安装命令“make install”将被使用。
在这个例子里,我们将创建一个 htop 包,这是一个 linux 交互式文本模式进程查看器(类似 top)。
首先,让我们从项目的官方网站下载源代码,作为一个好的习惯,我们存储源码包到/usr/local/src 下,并解压它。
# cd /usr/local/src
# wget http://hisham.hm/htop/releases/1.0.3/htop-1.0.3.tar.gz
# tar xzf htop-1.0.3.tar.gz
# cd htop-1.0.3
让我们看看 htop 的安装命令是什么,以便我们能用 Checkinstall 命令调用它,如下面所示,htop 用“make install”命令安装。
# ./configure
# make install
因此,要创建一个 htop 安装包,我们可以不带任何参数的调用 checkinstall,这将使用“make install”命令创建一个包。在这个过程中, checkinstall 命令会问你几个问题。
简而言之,如下命令会创建一个 htop 包:
# ./configure
# checkinstall
然后 checkinstall 将根据你的 linux 系统是什么,自动地创建一个.rpm 或者.deb 包。
gksudo/kdesudo
Taken from here:
You should never use normal
sudoto start graphical applications as root. You should usegksudo(kdesudoon Kubuntu) to run such programs.gksudosetsHOME=/root, and copies.Xauthorityto atmpdirectory. This prevents files in your home directory becoming owned by root.
Please note that this is primarily about configuration files. If you run Nautilus as root, even with gksu/gksudo, and you create a file or folder anywhere with it (including in your home directory), that file or folder will be owned by root. But if you run Nautilus (or most other graphical applications) as root with sudo, they may save their configuration files in your home directory (rather than root’s home directory). Those configuration files may be owned by root and inaccessible when you’re not running as root, which can severely mess up your settings, and may even keep some applications from working altogether.
The solution, once you have made this mistake, is to find the configuration files and delete them or chown them back to belonging your non-root user. Many such files start with a . or are contained in a directory that starts with a .. Some are located inside the .config folder in your home directory. To see files and folders that start with a . in Nautilus, press Ctrl+H (this shows hidden files.) To see them with ls, use the -a (or -A) flag.
To find if there are files not owned by you in your home directory, you can use the following command in a terminal:
find $HOME -not -user $USER -exec ls -lad {} \;
which will list all files under the home directory not owned by the user.
man
手册页(man pages),即参考手册页(reference manual pages)的简称,是你进入 Linux 的钥匙。你想知道的一切都在那里,包罗万象。这套文档永远不会赢得普利策奖,但这套文档是相当准确和完整的。手册页是主要信源,其权威性是众所周知的。
虽然它们是源头,但阅读起来并不是最令人愉快的。有一次,在很久以前的哲学课上,有人告诉我,阅读 亚里士多德 是最无聊的阅读。我不同意:说到枯燥的阅读,亚里士多德远远地排在第二位,仅次于手册页。
乍一看,这些页面可能看起来并不完整,但是,不管你信不信,手册页并不是为了隐藏信息 —— 只是因为信息量太大,这些页面必须要有结构,而且信息是以尽可能简短的形式给出的。这些解释相当简略,需要一些时间来适应,但一旦你掌握了使用它们的技巧,你就会发现它们实际上是多么有用。
入门
这些页面是通过一个叫做 man 的工具查看的,使用它的命令相当简单。在最简单的情况下,要使用 man,你要在命令行上输入 man,后面加一个空格和你想查询的命令,比如 ls 或 cp,像这样:
man ls
man 会打开 ls 命令的手册页。
你可以用方向键上下移动,按 q 退出查看手册页。通常情况下,手册页是用 less 打开的,所以 less 命令的键盘快捷键在 man 中也可以使用。
例如,你可以用 /search_term 来搜索一个特定的文本,等等。
有一个关于手册页的介绍,这是一篇值得阅读介绍。它非常详细地说明了手册页是如何布局和组织的。
要看这个页面,请打开一个终端,然后输入:
man man
节
在你开始更深入地研究手册页之前,知道手册页有一个固定的页面布局和一个归档方案会有帮助。这可能会让新手感到困惑,因为我可以说:“看手册页中关于 ls 的 NAME 节(section)”,我也可以说:“看第 5 节(section)中的 passwd 的手册页。”
这个词,“节(section)” 被用于两种不同的方式,但并不总是向新人解释其中的区别。
我不确定为什么会出现这种混淆,但我在培训新用户和初级系统管理员时看到过几次这种混淆。我认为这可能是隧道视野,专注于一件事会使一个人忘记另一件事。一叶障目,不见泰山。
对于那些已经知道其中的区别的人,你可以跳过这一小节。这一部分是针对那些刚接触到手册页的人。
这就是区别:
对于手册页
单独的手册页是用来显示信息块的。例如,每个手册页都有一个“NAME”节,显示命令的名称和简短的描述。还会有另一个信息块,称为“SYNOPSIS”,显示该命令是如何使用的,以此类推。
每个手册页都会有这些,以及其他的标题。这些在各个手册页上的节,或者说标题,有助于保持事情的一致性和信息的分工。
对于手册
使用“节”,如 “查看第 5 节中的 passwd 的手册页”,是指整个手册的内容。当我们只看一页时,很容易忽略这一点,但是 passwd 手册页是同一本手册的一部分,该手册还有 ls、rm、date、cal 等的手册页。
整个 Linux 手册是巨大的;它有成千上万的手册页。其中一些手册页有专门的信息。有些手册页有程序员需要的信息,有些手册页有网络方面的独特信息,还有一些是系统管理员会感兴趣的。
这些手册页根据其独特的目的被分组。想想看,把整个手册分成几个章节 —— 每章有一个特定的主题。有 9 个左右的章节(非常大的章节)。碰巧的是,这些章节被称为“节”。
总结一下:
- 手册中单页(我们称之为“手册页”)的节是由标题定义的信息块。
- 这个大的手册(所有页面的集合)中的章节,刚好被称为“节”。
现在你知道区别了,希望本文的其余部分会更容易理解。
手册页的节
你将会看到不同的手册页,所以让我们先研究一下各个页面的布局。
手册页被分成几个标题,它们可能因提供者不同而不同,但会有相似之处。一般的分类如下:
NAME(名称)SYNOPSIS(概要)DESCRIPTION(描述)EXAMPLES(例子)DIAGNOSTICS(诊断)FILES(文件)LIMITS(限制)PORTABILITY(可移植性)SEE ALSO(另见)HISTORY(历史)WARNING(警告)或BUGS(错误)NOTES(注意事项)
NAME - 在这个标题下是命令的名称和命令的简要描述。
SYNOPSIS - 显示该命令的使用方法。例如,这里是 cal 命令的概要:
cal [Month] [Year]
概要以命令的名称开始,后面是选项列表。概要采用命令行的一般形式;它显示了你可以输入的内容和参数的顺序。方括号中的参数([])是可选的;你可以不输入这些参数,命令仍然可以正常工作。不在括号内的项目必须使用。
请注意,方括号只是为了便于阅读。当你输入命令时,不应该输入它们。
DESCRIPTION - 描述该命令或工具的作用以及如何使用它。这一节通常以对概要的解释开始,并说明如果你省略任何一个可选参数会发生什么。对于长的或复杂的命令,这一节可能会被细分。
EXAMPLES - 一些手册页提供了如何使用命令或工具的例子。如果有这一节,手册页会尝试给出一些简单的使用例子,以及更复杂的例子来说明如何完成复杂的任务。
DIAGNOSTICS - 本节列出了由命令或工具返回的状态或错误信息。通常不显示不言自明的错误和状态信息。通常会列出可能难以理解的信息。
FILES - 本节包含了 UNIX 用来运行这个特定命令的补充文件的列表。这里,“补充文件”是指没有在命令行中指定的文件。例如,如果你在看 passwd 命令的手册,你可能会发现 /etc/passwd 列在这一节中,因为 UNIX 是在这里存储密码信息。
LIMITS - 本节描述了一个工具的限制。操作系统和硬件的限制通常不会被列出,因为它们不在工具的控制范围内。
PORTABILITY - 列出其他可以使用该工具的系统,以及该工具的其他版本可能有什么不同。
SEE ALSO - 列出包含相关信息的相关手册页。
HISTORY - 提供命令的简要历史,如它第一次出现的时间。
WARNING - 如果有这个部分,它包含了对用户的重要建议。
NOTES - 不像警告那样严重,但也是重要的信息。
同样,并不是所有的手册都使用上面列出的确切标题,但它们足够接近,可以遵循。
手册的节
整个 Linux 手册集合的手册页传统上被划分为有编号的节:
- 第 1 节:Shell 命令和应用程序
- 第 2 节:基本内核服务 - 系统调用和错误代码
- 第 3 节:为程序员提供的库信息
- 第 4 节:网络服务 - 如果安装了 TCP/IP 或 NFS 设备驱动和网络协议
- 第 5 节:文件格式 - 例如:显示
tar存档的样子 - 第 6 节:游戏
- 第 7 节:杂项文件和文档
- 第 8 节:系统管理和维护命令
- 第 9 节:不知名的内核规格和接口
将手册页分成这些组,可以使搜索更有效率。在我工作的地方,我有时会做一些编程工作,所以我花了一点时间看第 3 节的手册页。我也做一些网络方面的工作,所以我也知道要涉足网络部分。作为几个实验性机器的系统管理员,我在第 8 节花了很多时间。
将手册网归入特定的节(章节),使搜索信息更加容易 —— 无论是对需要搜索的人,还是对进行搜索的机器。
你可以通过名称旁边的数字来判断哪个手册页属于哪个部分。例如,如果你正在看 ls 的手册页,而页面的最上面写着。 LS(1),那么你正在浏览第 1 节中的 ls 页面,该节包含关于 shell 命令和应用程序的页面。
下面是另一个例子。如果你在看 passwd 的手册页,页面的顶部显示: PASSWD(1),说明你正在阅读第 1 节中描述 passwd 命令如何更改用户账户密码的手册页。如果你看到 PASSWD(5),那么你正在阅读关于密码文件和它是如何组成的的手册页。
passwd 恰好是两个不同的东西:一个是命令的名称,一个是文件的名称。同样,第 1 节描述了命令,而第 5 节涉及文件格式。
括号中的数字是重要的线索 —— 这个数字告诉你正在阅读的页面来自哪一节。
搜索一个特定的节
基本命令:
man -a name
将在每一节中搜索由 name 标识的手册页,按数字顺序逐一显示。要把搜索限制在一个特定的部分,请在 man 命令中使用一个参数,像这样:
man 1 name
这个命令将只在手册页的第 1 节中搜索 name。使用我们前面的 passwd 例子,这意味着我们可以保持搜索的针对性。如果我想阅读 passwd 命令的手册页,我可以在终端输入以下内容:
man 1 passwd
man 工具将只在第 1 节中搜索 passwd 并显示它。它不会在任何其他节中寻找 passwd。
这个命令的另一种方法是输入: man passwd.1。
搜索包含某个关键词的所有手册页
如果你想获得包含某个关键词的手册页的列表,man 命令中的 -k 选项(通常称为标志或开关)可以派上用场。例如,如果你想看一个关于 ftp 的手册列表,你可以通过输入以下内容得到这个列表:
man -k ftp
在接下来的列表中,你可以选择一个特定的手册页来阅读。
在某些系统上,在 man -k 工作之前,系统管理员需要运行一个叫做 catman 的工具。
了解手册的各个节
有两个有趣的工具可以帮助你搜索信息:whatis和 whereis。
whatis
有的时候,我们完全可以得到我们需要的信息。我们需要的信息有很大的机会是可以找到的 —— 找到它可能是一个小问题。
例如,如果我想看关于 passwd 文件的手册页,我在终端上输入:
man passwd
我就会看到关于 passwd 命令所有信息的手册页,但没有关于 passwd 文件的内容。我知道 passwd 是一个命令,也有一个 passwd 文件,但有时,我可能会忘记这一点。这时我才意识到,文件结构在手册页中的不同节,所以我输入了:
man 4 passwd
我得到这样的答复:
No manual entry for passwd in section 4
See 'man 7 undocumented' for help when manual pages are not available.
又是一次健忘的失误。文件结构在 System V UNIX 页面的第 4 节中。几年前,当我建立文件时,我经常使用 man 4 ...;这仍然是我的一个习惯。那么它在 Linux 手册中的什么地方呢?
现在是时候调用 whatis 来纠正我了。为了做到这一点,我在我的终端中输入以下内容:
whatis passwd
然后我看到以下内容:
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password file
啊!passwd 文件的页面在第 5 节。现在没问题了,可以访问我想要的信息了:
man 5 passwd
然后我被带到了有我需要的信息的手册页。
whatis 是一个方便的工具,可以用简短的一句话告诉你一个命令的作用。想象一下,你想知道 cal 是做什么的,而不想查看手册页。只要在命令提示符下键入以下内容。
whatis cal
你会看到这样的回应:
cal (1) - displays a calendar and the date of Easter
现在你知道了 whatis 命令,我可以告诉你一个秘密 —— 有一个 man 命令的等价物。为了得到这个,我们使用 -f 开关:man -f ...。
试试吧。在终端提示下输入 whatis cal。执行后就输入:man -f cal。两个命令的输出将是相同的。
whereis
whereis 命令的名字就说明了这一点 —— 它告诉你一个程序在文件系统中的位置。它也会告诉你手册页的存放位置。再以 cal 为例,我在提示符下输入以下内容:
whereis cal
我将看到这个:
cal: /usr/bin/cal /usr/share/man/man1/cal.1.gz
仔细看一下这个回答。答案只在一行里,但它告诉我两件事:
/usr/bin/cal是cal程序所在的地方,以及/usr/share/man/man1/cal.1.gz是手册页所在的地方(我也知道手册页是被压缩的,但不用担心 ——man命令知道如何即时解压)。
whereis 依赖于 PATH 环境变量;它只能告诉你文件在哪里,如果它们在你的 PATH 环境变量中。
你可能想知道是否有一个与 whereis 相当的 man 命令。没有一个命令可以告诉你可执行文件的位置,但有一个开关可以告诉你手册页的位置。在这个例子中使用 date 命令,如果我们输入:
whereis date
在终端提示符下,我们会看到:
date: /usr/bin/date /usr/share/man/man1/date.1.gz
我们看到 date 程序在 /usr/bin/ 目录下,其手册页的名称和位置是:/usr/share/man/man1/date.1.gz。
我们可以让 man 像 whereis 一样行事,最接近的方法是使用 -w 开关。我们不会得到程序的位置,但我们至少可以得到手册页的位置,像这样:
man -w date
我们将看到这样的返回:
/usr/share/man/man1/date.1.gz
你知道了 whatis 和 whereis,以及让 man 命令做同样(或接近)事情的方法。我展示了这两种方法,有几个不同的原因。
多年来,我使用 whatis 和 whereis,因为它们在我的培训手册中。直到最近我才了解到 man -f ... 和 man -w ...。我确信我看了几百次 man 的手册页,但我从未注意到 -f 和 -w 开关。我总是在看手册页的其他东西(例如:man -k ...)。我只专注于我需要找到的东西,而忽略了其他的东西。一旦我找到了我需要的信息,我就会离开这个页面,去完成工作,而不去注意这个命令所提供的其他一些宝贝。
这没关系,因为这部分就是手册页的作用:帮助你完成工作。
直到最近我向别人展示如何使用手册页时,我才花时间去阅读 —— “看看还有什么可能” —— 我们才真正注意到关于 man 命令的 -f 和 -w 标记可以做什么的信息。
不管你使用 Linux 多久了,或者多么有经验,总有一些新东西需要学习。
手册页会告诉你在完成某项任务时可能需要知道的东西 —— 但它们也有很多内容 —— 足以让你看起来像个魔术师,但前提是你要花时间去读。
结论
如果你花一些时间和精力在手册页上,你将会取得胜利。你对手册页的熟练程度,将在你掌握 Linux 的过程中发挥巨大作用。
tldr
Collaborative cheatsheets for console commands
“TLDR” 是流行的互联网行话,意思是“太长不读(to long didn’t read)”。这就是他们创建 tldr 的想法。如果你觉得手册页太长而不想阅读,tldr 通过提供命令的实际例子而将其简化了。
sudo apt install tldr
tldr -u
tldr tldr
ls
ls 命令可以列出一个 POSIX 系统上的文件。这是一个简单的命令,但它经常被低估,不是它能做什么(因为它确实只做了一件事),而是你该如何优化对它的使用。
GNU 还是 BSD?
在了解 ls 的隐藏能力之前,你必须确定你正在运行哪个 ls 命令。有两个最流行的版本:包含在 GNU coreutils 包中的 GNU 版本,以及 BSD 版本。如果你正在运行 Linux,那么你很可能已经安装了 GNU 版本的 ls。如果你正在运行 BSD 或 MacOS,那么你有的是 BSD 版本。本文会介绍它们的不同之处。
你可以使用 --version 选项找出你计算机上的版本:
ls --version
如果它返回有关 GNU coreutils 的信息,那么你拥有的是 GNU 版本。如果它返回一个错误,你可能正在运行的是 BSD 版本(运行 man ls | head 以确定)。
你还应该调查你的发行版可能具有哪些预设选项。终端命令的自定义通常放在 $HOME/.bashrc 或 $HOME/.bash_aliases 或 $HOME/.profile 中,它们是通过将 ls 别名化为更复杂的 ls 命令来完成的。例如:
alias ls='ls --color'
发行版提供的预设非常有用,但它们确实很难分辨出哪些是 ls 本身的特性,哪些是它的附加选项提供的。你要是想要运行 ls 命令本身而不是它的别名,你可以用反斜杠“转义”命令:
\ls
分类
单独运行 ls 会以适合你终端的列数列出文件:
$ ls ~/example
bunko jdk-10.0.2
chapterize otf2ttf.ff
despacer overtar.sh
estimate.sh pandoc-2.7.1
fop-2.3 safe_yaml
games tt
这是有用的信息,但所有这些文件看起来基本相同,没有方便的图标来快速表示出哪个是目录、文本文件或图像等等。
使用 -F(或 GNU 上的长选项 --classify)以在每个条目之后显示标识文件类型的指示符:
$ ls ~/example
bunko jdk-10.0.2/
chapterize* otf2ttf.ff*
despacer* overtar.sh*
estimate.sh pandoc@
fop-2.3/ pandoc-2.7.1/
games/ tt*
使用此选项,终端中列出的项目使用简写符号来按文件类型分类:
- 斜杠(
/)表示目录(或“文件夹”)。 - 星号(
*)表示可执行文件。这包括二进制文件(编译代码)以及脚本(具有可执行权限的文本文件)。 - 符号(
@)表示符号链接(或“别名”)。 - 等号(
=)表示套接字。 - 在 BSD 上,百分号(
%)表示涂改 whiteout(某些文件系统上的文件删除方法)。 - 在 GNU 上,尖括号(
>)表示门 door(Illumos 和 Solaris 上的进程间通信)。 - 竖线(
|)表示 FIFO 管道。 这个选项的一个更简单的版本是-p,它只区分文件和目录。
(LCTT 译注:在支持彩色的终端上,使用 --color 选项可以以不同的颜色来区分文件类型,但要注意如果将输出导入到管道中,则颜色消失。)
长列表
从 ls 获取“长列表”的做法是如此常见,以至于许多发行版将 ll 别名为 ls -l。长列表提供了许多重要的文件属性,例如权限、拥有每个文件的用户、文件所属的组、文件大小(以字节为单位)以及文件上次更改的日期:
$ ls -l
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
[...]
如果你不想以字节为单位,请添加 -h 标志(或 GNU 中的 --human)以将文件大小转换为更加人性化的表示方法:
$ ls --human
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
-rwxrwxr-x. 1 seth seth 662 Apr 29 22:27 factorial
-rwxrwx---. 1 seth users 20M Jun 29 2018 fop-2.3-bin.tar.gz
-rwxrwxr-x. 1 seth seth 6.1K May 22 10:22 geteltorito
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
要看到更少的信息,你可以带有 -o 选项只显示所有者的列,或带有 -g 选项只显示所属组的列:
$ ls -o
-rwxrwx---. 1 seth 455 Mar 2 2017 estimate.sh
-rwxrwxr-x. 1 seth 662 Apr 29 22:27 factorial
-rwxrwx---. 1 seth 20M Jun 29 2018 fop-2.3-bin.tar.gz
-rwxrwxr-x. 1 seth 6.1K May 22 10:22 geteltorito
-rwxrwx---. 1 seth 177 Nov 12 2018 html4mutt.sh
也可以将两个选项组合使用以显示两者。
时间和日期格式
ls 的长列表格式通常如下所示:
-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
月份的名字不便于排序,无论是通过计算还是识别(取决于你的大脑是否倾向于喜欢字符串或整数)。你可以使用 --time-style 选项和格式名称更改时间戳的格式。可用格式为:
full-iso:ISO 完整格式(1970-01-01 21:12:00)long-iso:ISO 长格式(1970-01-01 21:12)iso:iso 格式(01-01 21:12)locale:本地化格式(使用你的区域设置)posix-STYLE:POSIX 风格(用区域设置定义替换STYLE)
你还可以使用 date 命令的正式表示法创建自定义样式。
按时间排序
通常,ls 命令按字母顺序排序。你可以使用 -t 选项根据文件的最近更改的时间(最新的文件最先列出)进行排序。
例如:
$ touch foo bar baz
$ ls
bar baz foo
$ touch foo
$ ls -t
foo bar baz
列出方式
ls 的标准输出平衡了可读性和空间效率,但有时你需要按照特定方式排列的文件列表。
要以逗号分隔文件列表,请使用 -m:
ls -m ~/example
bar, baz, foo
要强制每行一个文件,请使用 -1 选项(这是数字 1,而不是小写的 L):
$ ls -1 ~/bin/
bar
baz
foo
要按文件扩展名而不是文件名对条目进行排序,请使用 -X(这是大写 X):
$ ls
bar.xfc baz.txt foo.asc
$ ls -X
foo.asc baz.txt bar.xfc
隐藏杂项
在某些 ls 列表中有一些你可能不关心的条目。例如,元字符 . 和 .. 分别代表“本目录”和“父目录”。如果你熟悉在终端中如何切换目录,你可能已经知道每个目录都将自己称为 .,并将其父目录称为 ..,因此当你使用 -a 选项显示隐藏文件时并不需要它经常提醒你。
要显示几乎所有隐藏文件(. 和 .. 除外),请使用 -A 选项:
$ ls -a
.
..
.android
.atom
.bash_aliases
[...]
$ ls -A
.android
.atom
.bash_aliases
[...]
有许多优秀的 Unix 工具有保存备份文件的传统,它们会在保存文件的名称后附加一些特殊字符作为备份文件。例如,在 Vim 中,备份会以在文件名后附加 ~ 字符的文件名保存。
这些类型的备份文件已经多次使我免于愚蠢的错误,但是经过多年享受它们提供的安全感后,我觉得不需要用视觉证据来证明它们存在。我相信 Linux 应用程序可以生成备份文件(如果它们声称这样做的话),我很乐意相信它们存在 —— 而不用必须看到它们。
要隐藏备份文件,请使用 -B 或 --ignore-backups 隐藏常用备份格式(此选项在 BSD 的 ls 中不可用):
$ ls
bar.xfc baz.txt foo.asc~ foo.asc
$ ls -B
bar.xfc baz.txt foo.asc
当然,备份文件仍然存在;它只是过滤掉了,你不必看到它。
除非另有配置,GNU Emacs 在文件名的开头和结尾添加哈希字符(#)来保存备份文件(#file#)。其他应用程序可能使用不同的样式。使用什么模式并不重要,因为你可以使用 --hide 选项创建自己的排除项:
$ ls
bar.xfc baz.txt #foo.asc# foo.asc
$ ls --hide="#*#"
bar.xfc baz.txt foo.asc
递归地列出目录
除非你在指定目录上运行 ls,否则子目录的内容不会与 ls 命令一起列出:
$ ls -F
example/ quux* xyz.txt
$ ls -R
quux xyz.txt
./example:
bar.xfc baz.txt #foo.asc# foo.asc
使用别名使其永久化
ls 命令可能是 shell 会话期间最常使用的命令。这是你的眼睛和耳朵,为你提供上下文信息和确认命令的结果。虽然有很多选项很有用,但 ls 之美的一部分就是简洁:两个字符和回车键,你就知道你到底在哪里以及附近有什么。如果你不得不停下思考(更不用说输入)几个不同的选项,它会变得不那么方便,所以通常情况下,即使最有用的选项也不会用了。
解决方案是为你的 ls 命令添加别名,以便在使用它时,你可以获得最关心的信息。
要在 Bash shell 中为命令创建别名,请在主目录中创建名为 .bash_aliases 的文件(必须在开头包含 .)。 在此文件中,列出要创建的别名,然后是要为其创建别名的命令。例如:
alias ls='ls -A -F -B --human --color'
这一行导致你的 Bash shell 将 ls 命令解释为 ls -A -F -B --human --color。
你不必仅限于重新定义现有命令,还可以创建自己的别名:
alias ll='ls -l'
alias la='ls -A'
alias lh='ls -h'
要使别名起作用,shell 必须知道 .bash_aliases 配置文件存在。在编辑器中打开 .bashrc 文件(如果它不存在则创建它),并包含以下代码块:
if [ -e $HOME/.bash_aliases ]; then
source $HOME/.bash_aliases
fi
每次加载 .bashrc(这是一个新的 Bash shell 启动的时候),Bash 会将 .bash_aliases 加载到你的环境中。你可以关闭并重新启动 Bash 会话,或者直接强制它执行此操作:
source ~/.bashrc
如果你忘了你是否有别名命令,which 命令可以告诉你:
$ which ls
alias ls='ls -A -F -B --human --color'
/usr/bin/ls
如果你将 ls 命令别名为带有选项的 ls 命令,则可以通过将反斜杠前缀到 ls 前来覆盖你的别名。例如,在示例别名中,使用 -B 选项隐藏备份文件,这意味着无法使用 ls 命令显示备份文件。 可以覆盖该别名以查看备份文件:
$ ls
bar baz foo
$ \ls
bar baz baz~ foo
做一件事,把它做好
ls 命令有很多选项,其中许多是特定用途的或高度依赖于你所使用的终端。在 GNU 系统上查看 info ls,或在 GNU 或 BSD 系统上查看 man ls 以了解更多选项。
你可能会觉得奇怪的是,一个以每个工具“做一件事,把它做好”的前提而闻名的系统会让其最常见的命令背负 50 个选项。但是 ls 只做一件事:它列出文件,而这 50 个选项允许你控制接收列表的方式,ls 的这项工作做得非常、_非常_好。
exa
A modern replacement for ‘ls’.
du (Disk Usage)
在 Linux 中使用 ls 命令 列出的目录内容中,目录的大小仅显示 4KB。这是一个默认的大小,是用来存储磁盘上存储目录的元数据的大小。
du 命令 表示 磁盘使用率。这是一个标准的 Unix 程序,用于估计当前工作目录中的文件空间使用情况。
它使用递归方式总结磁盘使用情况,以获取目录及其子目录的大小。
du -hs --max-depth=0 /path/dir
du– 这是一个命令-h– 以易读的格式显示大小 (例如 1K 234M 2G)-s– 仅显示每个参数的总数--max-depth=N– 目录的打印深度
NCurses Disk Usage
Ncdu is a disk usage analyzer with an ncurses interface.
ncdu 命令旨在提供一份关于你在硬盘上使用的空间的交互式报告。
gdu
Fast disk usage analyzer with console interface written in Go
Diff
diff 是 Unix 系统的一个很重要的工具程序。
它用来比较两个文本文件的差异,是代码版本管理的基石之一。你在命令行下,输入:
diff <变动前的文件> <变动后的文件>
diff 就会告诉你,这两个文件有何差异。它的显示结果不太好懂,下面我就来说明,如何读懂 diff。
三种格式
由于历史原因,diff 有三种格式:
- 正常格式(normal diff)
- 上下文格式(context diff)
- 合并格式(unified diff)
我们依次来看。
示例文件
为了便于讲解,先新建两个示例文件。
第一个文件叫做 f1,内容是每行一个 a,一共 7 行。
a
a
a
a
a
a
a
第二个文件叫做 f2,修改 f1 而成,第 4 行变成 b,其他不变。
a
a
a
b
a
a
a
正常格式
现在对 f1 和 f2 进行比较:
diff f1 f2
这时,diff 就会显示正常格式的结果:
4c4
< a
---
> b
第一行是一个提示,用来说明变动位置。
4c4
它分成三个部分:前面的"4",表示 f1 的第 4 行有变化;中间的"c"表示变动的模式是内容改变(change),其他模式还有"增加"(a,代表 addition)和"删除"(d,代表 deletion);后面的"4",表示变动后变成 f2 的第 4 行。
第二行分成两个部分。
< a
前面的小于号,表示要从 f1 当中去除该行(也就是第 4 行),后面的"a"表示该行的内容。
第三行用来分割 f1 和 f2。
---
第四行,类似于第二行。
> b
前面的大于号表示 f2 增加了该行,后面的"b"表示该行的内容。
最早的Unix(即 AT&T 版本的 Unix),使用的就是这种格式的 diff。
上下文格式
上个世纪 80 年代初,加州大学伯克利分校推出 BSD 版本的 Unix 时,觉得 diff 的显示结果太简单,最好加入上下文,便于了解发生的变动。因此,推出了上下文格式的 diff。
它的使用方法是加入 c 参数(代表 context)。
diff -c f1 f2
显示结果如下:
*** f1 2012-08-29 16:45:41.000000000 +0800
--- f2 2012-08-29 16:45:51.000000000 +0800
***************
*** 1,7 ****
a
a
a
!a
a
a
a
--- 1,7 ----
a
a
a
!b
a
a
a
这个结果分成四个部分。
第一部分的两行,显示两个文件的基本情况:文件名和时间信息。
*** f1 2012-08-29 16:45:41.000000000 +0800
--- f2 2012-08-29 16:45:51.000000000 +0800
***表示变动前的文件,---表示变动后的文件。
第二部分是 15 个星号,将文件的基本情况与变动内容分割开。
***************
第三部分显示变动前的文件,即 f1。
*** 1,7 ****
a
a
a
!a
a
a
a
这时不仅显示发生变化的第 4 行,还显示第 4 行的前面三行和后面三行,因此一共显示 7 行。所以,前面的*** 1,7 ****就表示,从第 1 行开始连续 7 行。
另外,文件内容的每一行最前面,还有一个标记位。如果为空,表示该行无变化;如果是感叹号(!),表示该行有改动;如果是减号(-),表示该行被删除;如果是加号(+),表示该行为新增。
第四部分显示变动后的文件,即 f2。
--- 1,7 ----
a
a
a
!b
a
a
a
除了变动行(第 4 行)以外,也是上下文各显示三行,总共显示 7 行。
合并格式
如果两个文件相似度很高,那么上下文格式的 diff,将显示大量重复的内容,很浪费空间。1990 年,GNU diff 率先推出了"合并格式"的 diff,将 f1 和 f2 的上下文合并在一起显示。
它的使用方法是加入 u 参数(代表 unified)。
diff -u f1 f2
显示结果如下:
--- f1 2012-08-29 16:45:41.000000000 +0800
+++ f2 2012-08-29 16:45:51.000000000 +0800
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
它的第一部分,也是文件的基本信息。
--- f1 2012-08-29 16:45:41.000000000 +0800
+++ f2 2012-08-29 16:45:51.000000000 +0800
---表示变动前的文件,+++表示变动后的文件。
第二部分,变动的位置用两个@作为起首和结束。
@@ -1,7 +1,7 @@
前面的"-1,7"分成三个部分:减号表示第一个文件(即 f1),“1"表示第 1 行,“7"表示连续 7 行。合在一起,就表示下面是第一个文件从第 1 行开始的连续 7 行。同样的,"+1,7"表示变动后,成为第二个文件从第 1 行开始的连续 7 行。
第三部分是变动的具体内容。
a
a
a
-a
+b
a
a
a
除了有变动的那些行以外,也是上下文各显示 3 行。它将两个文件的上下文,合并显示在一起,所以叫做"合并格式”。每一行最前面的标志位,空表示无变动,减号表示第一个文件删除的行,加号表示第二个文件新增的行。
git 格式
版本管理系统 git,使用的是合并格式 diff 的变体。
git diff
显示结果如下:
diff --git a/f1 b/f1
index 6f8a38c..449b072 100644
--- a/f1
+++ b/f1
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
第一行表示结果为 git 格式的 diff。
diff --git a/f1 b/f1
进行比较的是,a 版本的 f1(即变动前)和 b 版本的 f1(即变动后)。
第二行表示两个版本的 git 哈希值(index 区域的 6f8a38c 对象,与工作目录区域的 449b072 对象进行比较),最后的六位数字是对象的模式(普通文件,644 权限)。
index 6f8a38c..449b072 100644
第三行表示进行比较的两个文件。
--- a/f1
+++ b/f1
---表示变动前的版本,+++表示变动后的版本。
后面的行都与官方的合并格式 diff 相同。
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
Crontab
使用 crontab 命令来执行定时任务。所谓定时任务,就是未来的某个或多个时点,预定要执行的任务,比如每五分钟收一次邮件、每天半夜两点分析一下日志等等。
Installing
sudo apt install cronie
Running
systemctl enable crond.service
systemctl start crond.service
命令详解
crontab 命令通过 /etc/cron.allow 和 /etc/cron.deny 文件来限制某些用户是否可以使用 crontab 命令:
- 当系统中有 /etc/cron.allow 文件时,只有写入此文件的用户可以使用 crontab 命令,没有写入的用户不能使用 crontab 命令。
- 当系统中只有 /etc/cron.deny 文件时,写入此文件的用户不能使用 crontab 命令,没有写入文件的用户可以使用 crontab 命令。
- /etc/cron.allow 文件比 /etc/cron.deny 文件的优先级高,Linux 系统中默认只有 /etc/cron.deny 文件。
crontab 命令的基本格式如下:
crontab [选项] [file]
注意,这里的 file 指的是命令文件的名字,表示将 file 作为 crontab 的任务列表文件并载入 crontab,若在命令行中未指定文件名,则此命令将接受标准输入(键盘)上键入的命令,并将它们键入 crontab。
常用选项
| 选项 | 功能 |
|---|---|
| -u user | 用来设定某个用户的 crontab 服务,例如 “-u demo” 表示设备 demo 用户的 crontab 服务,此选项一般有 root 用户来运行。 |
| -e | 编辑某个用户的 crontab 文件内容。如果不指定用户,则表示编辑当前用户的 crontab 文件。 |
| -l | 显示某用户的 crontab 文件内容,如果不指定用户,则表示显示当前用户的 crontab 文件内容。 |
| -r | 从 /var/spool/cron 删除某用户的 crontab 文件,如果不指定用户,则默认删除当前用户的 crontab 文件。 |
| -i | 在删除用户的 crontab 文件时,给确认提示。 |
crontab 文件格式
* * * * * 执行的任务
执行的任务字段既可以定时执行系统命令,也可以定时执行某个 Shell 脚本。
执行时间
| 项目 | 含义 | 范围 |
|---|---|---|
| 第一个”*" | 一小时当中的第几分钟(minute) | 0~59 |
| 第二个"*" | 一天当中的第几小时(hour) | 0~23 |
| 第三个"*" | 一个月当中的第几天(day) | 1~31 |
| 第四个"*" | 一年当中的第几个月(month) | 1~12 |
| 第五个"*" | 一周当中的星期几(week) | 0~7(0 和 7 都代表星期日) |
时间特殊符号
| 特殊符号 | 含义 |
|---|---|
| *(星号) | 代表任何时间。比如第一个"*“就代表一小时种每分钟都执行一次的意思。 |
| ,(逗号) | 代表不连续的时间。比如 0 8,12,16 * * * 命令 就代表在每天的 8 点 0 分、12 点 0 分、16 点 0 分都执行一次命令。 |
| -(中杠) | 代表连续的时间范围。比如 0 5 * * 1-6 命令,代表在周一到周六的凌晨 5 点 0 分执行命令。 |
| /(正斜线) | 代表每隔多久执行一次。比如 */10 * * * * 命令,代表每隔 10 分钟就执行一次命令。 |
当“crontab -e”编辑完成之后,一旦保存退出,那么这个定时任务实际就会写入 /var/spool/cron/ 目录中,每个用户的定时任务用自己的用户名进行区分。而且 crontab 命令只要保存就会生效,只要 crond 服务是启动的。
crontab 举例
| 时间 | 含义 |
|---|---|
45 22 * * * 命令 |
在每天 22 点 45 分执行命令 |
0 17 * * 1 命令 |
在每周一的 17 点 0 分执行命令 |
0 5 1,15 * * 命令 |
在每月 1 日和 15 日的凌晨 5 点 0 分执行命令 |
40 4 * * 1-5 命令 |
在每周一到周五的凌晨 4 点 40 分执行命令 |
*/10 4 * * * 命令 |
在每天的凌晨 4 点,每隔 10 分钟执行一次命令 |
0 0 1,15 * 1 命令 |
在每月 1 日和 15 日,每周一 0 点 0 分都会执行命令 |
注意事项
- 6 个选项都不能为空,必须填写。如果不确定,则使用“*”代表任意时间。
- crontab 定时任务的最小有效时间是分钟,最大有效时间是月。像 2018 年某时执行、3 点 30 分 30 秒这样的时间都不能被识别。
- 在定义时间时,日期和星期最好不要在一条定时任务中出现,因为它们都以天为单位,非常容易让管理员混淆。
- 在定时任务中,不管是直接写命令,还是在脚本中写命令,最好都使用绝对路径。有时使用相对路径的命令会报错。
run a script on startup
Put the script in the appropriate user’s cron table (i. e. the crontab) with a schedule of @reboot.
A user can edit its cron table with crontab -e.
An example which will run /path/to/script.sh at startup:
@reboot /path/to/script.sh
If you need to run it as root, don’t use @reboot sudo /path/to/script.sh;
use sudo crontab -eu root to edit root’s crontab.
ps
简介
要对进程进行监测和控制,首先必须要了解当前进程的情况,也就是需要查看当前进程,而 ps 命令(Process Status)就是最基本同时也是非常强大的进程查看命令。使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等。总之大部分信息都是可以通过执行该命令得到的。ps 命令列出的是当前那些进程的快照,就是执行 ps 命令的那个时刻的那些进程,如果想要动态的显示进程信息,就可以使用 top 命令。
-
就绪状态和运行状态
就绪状态的状态标志 state 的值为 TASK_RUNNING。此时,程序已被挂入运行队列,处于准备运行状态。一旦获得处理器使用权,即可进入运行状态。
当进程获得处理器而运行时 ,state 的值仍然为 TASK_RUNNING,并不发生改变;但 Linux 会把一个专门用来指向当前运行任务的指针 current 指向它,以表示它是一个正在运行的进程。
-
可中断等待状态
状态标志 state 的值为 TASK_INTERRUPTIBL。此时,由于进程未获得它所申请的资源而处在等待状态。一旦资源有效或者有唤醒信号,进程会立即结束等待而进入就绪状态。
-
不可中断等待状态
状态标志 state 的值为 TASK_UNINTERRUPTIBL。此时,进程也处于等待资源状态。一旦资源有效,进程会立即进入就绪状态。这个等待状态与可中断等待状态的区别在于:处于 TASK_UNINTERRUPTIBL 状态的进程不能被信号量或者中断所唤醒,只有当它申请的资源有效时才能被唤醒。
这个状态被应用在内核中某些场景中,比如当进程需要对磁盘进行读写,而此刻正在 DMA 中进行着数据到内存的拷贝,如果这时进程休眠被打断(比如强制退出信号)那么很可能会出现问题,所以这时进程就会处于不可被打断的状态下。
-
停止状态
状态标志 state 的值为 TASK_STOPPED。当进程收到一个 SIGSTOP 信号后,就由运行状态进入停止状态,当受到一个 SIGCONT 信号时,又会恢复运行状态。这种状态主要用于程序的调试,又被叫做“暂停状态”、“挂起状态”。
-
中止状态
状态标志 state 的值为 TASK_DEAD。进程因某种原因而中止运行,进程占有的所有资源将被回收,除了 task_struct 结构(以及少数资源)以外,并且系统对它不再予以理睬,所以这种状态也叫做“僵死状态”,进程成为僵尸进程。
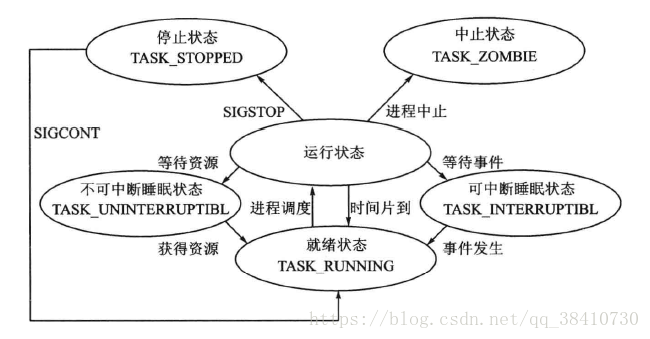
ps 标识进程状态对应的 5 种状态码:
R:就绪状态和运行状态 runnable (on run queue)S:可中断等待状态 sleepingD:不可中断等待状态 uninterruptible sleep (usually IO)T:停止状态 traced or stoppedZ:中止状态 a defunct (”zombie”) process
ps 标识进程的其他状态码:
X:死掉的进程 Dead (应该不会出现)W:内存交互状态 Paging (从 2.6 内核开始无效)N:高优先级<:低优先级s:包含子进程L:被锁入内存l:多线程状态+:前台进程
命令参数
在不同的 Linux 发行版上,ps 命令的语法各不相同,为此,Linux 采取了一个折中的方法,即融合各种不同的风格,兼顾那些已经习惯了其它系统上使用 ps 命令的用户。ps 命令支持三种使用的语法格式:
- UNIX 风格,选项可以组合在一起,并且选项前必须有“-”连字符;
- BSD 风格,选项可以组合在一起,但是选项前不能有“-”连字符;
- GNU 风格的选项,选项前有两个“-”连字符;
ps 命令常用的参数:
ps -a 显示所有终端下执行的进程,包含其他用户的进程
ps -A 显示所有进程
ps -e 和-A功能一样
ps -H 显示树状结构,表示程序间的相互关系
ps -f 全格式显示进程
ps a 显示当前终端下执行的进程
ps c 显示进程的真实名称
ps e 列出程序所使用的环境变量
ps f 用ASCII字符显示树状结构,表达程序间的相互关系
ps x 显示所有进程,无论是否运行在终端上
ps u 显示用户相关的进程或者与用户相关的属性
ps r 只显示正在运行的进程
使用实例
大家如果执行 man ps 命令,则会发现 ps 命令的帮助为了适应不同的类 UNIX 系统,可用格式非常多,不方便记忆。所以,我建议大家记忆几个固定选项即可。
ps aux 查看系统中所有的进程
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 2872 1416 ? Ss Jun04 0:02 /sbin/init
root 2 0.0 0.0 0 0 ? S Jun04 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S Jun04 0:00 [migration/0]
root 4 0.0 0.0 0 0 ? S Jun04 0:00 [ksoftirqd/0]
…省略部分输出…
输出信息中各列的具体含义:
| 表头 | 含义 |
|---|---|
| USER | 该进程是由哪个用户产生的。 |
| PID | 进程的 ID。 |
| %CPU | 该进程占用 CPU 资源的百分比,占用的百分比越高,进程越耗费资源。 |
| %MEM | 该进程占用物理内存的百分比,占用的百分比越高,进程越耗费资源。 |
| VSZ | 该进程占用虚拟内存的大小,单位为 KB。 |
| RSS | 该进程占用实际物理内存的大小,单位为 KB。 |
| TTY | 该进程是在哪个终端运行的。其中,tty1 ~ tty7 代表本地控制台终端(可以通过 Alt+F1 ~ F7 快捷键切换不同的终端),tty1~tty6 是本地的字符界面终端,tty7 是图形终端。pts/0 ~ 255 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。 |
| STAT | 进程状态。 |
| START | 该进程的启动时间。 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间。 |
| COMMAND | 产生此进程的命令名。 |
ps -le 查看系统中所有的进程
ps aux 命令可以看到系统中所有的进程,ps -le 命令也能看到系统中所有的进程。由于 -l 选项的作用,所以 ps -le 命令能够看到更加详细的信息,比如父进程的 PID、优先级等。但是这两个命令的基本作用是一致的,掌握其中一个就足够了。
# ps -le
F S UID PID PPID C PRI Nl ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 80 0 - 718 - ? 00:00:02 init
1 S 0 2 0 0 80 0 - 0 - ? 00:00:00 kthreadd
1 S 0 3 2 0 -40 - - 0 - ? 00:00:00 migration/0
1 S 0 4 2 0 80 0 - 0 - ? 00:00:00 ksoflirqd/0
1 S 0 5 2 0 -40 - - 0 - ? 00:00:00 migration/0
…省略部分输出…
输出信息中各列的含义:
| 表头 | 含义 |
|---|---|
| F | 进程标志,说明进程的权限,常见的标志有两个: 1:进程可以被复制,但是不能被执行;4:进程使用超级用户权限; |
| S | 进程状态。具体的状态和"psaux"命令中的 STAT 状态一致; |
| UID | 运行此进程的用户的 ID; |
| PID | 进程的 ID; |
| PPID | 父进程的 ID; |
| C | 该进程的 CPU 使用率,单位是百分比; |
| PRI | 进程的优先级,数值越小,该进程的优先级越高,越早被 CPU 执行; |
| NI | 进程的优先级,数值越小,该进程越早被执行; |
| ADDR | 该进程在内存的哪个位置; |
| SZ | 该进程占用多大内存; |
| WCHAN | 该进程是否运行。"-“代表正在运行; |
| TTY | 该进程由哪个终端产生; |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间; |
| CMD | 产生此进程的命令名; |
ps -l 查看当前 Shell 产生的进程
# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 18618 18614 0 80 0 - 1681 - pts/1 00:00:00 bash
4 R 0 18683 18618 4 80 0 - 1619 - pts/1 00:00:00 ps
top
简介
top 命令是 Linux 下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于 Windows 的任务管理器。
top 显示系统当前的进程和其他状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止该程序为止。
比较准确的说,top 命令提供了实时的对系统处理器的状态监视。它将显示系统中 CPU 最“敏感”的任务列表。该命令可以按 CPU 使用、内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
命令参数
top 命令的基本格式如下:
#top [选项]
选项:
- -d 秒数:指定 top 命令每隔几秒更新。默认是 3 秒;
- -b:使用批处理模式输出。一般和”-n"选项合用,用于把 top 命令重定向到文件中;
- -n 次数:指定 top 命令执行的次数。一般和”-b"选项合用;
- -p 进程 PID:仅查看指定 ID 的进程;
- -s:使 top 命令在安全模式中运行,避免在交互模式中出现错误;
- -u 用户名:只监听某个用户的进程;
交互操作指令
在 top 命令的显示窗口中,还可以使用如下按键,进行一下交互操作:
- ? 或 h:显示交互模式的帮助
- P:按照 CPU 的使用率排序,默认就是此选项
- M:按照内存的使用率排序
- N:按照 PID 排序
- T:按照 CPU 的累积运算时间排序,也就是按照 TIME+ 项排序
- k:按照 PID 给予某个进程一个信号。一般用于中止某个进程,信号 9 是强制中止的信号
- r:按照 PID 给某个进程重设优先级(Nice)值
<Space>:立即刷新- s:设置刷新时间间隔
- c:显示命令完全模式
- t::显示或隐藏进程和 CPU 状态信息
- m:显示或隐藏内存状态信息
- l:显示或隐藏 uptime 信息
- f:增加或减少进程显示标志
- S:累计模式,会把已完成或退出的子进程占用的 CPU 时间累计到父进程的 TIME+
- u:指定显示用户进程
- i:只显示正在运行的进程
- W:保存对 top 的设置到文件
~/.toprc,下次启动将自动调用 toprc 文件的设置。 - q:退出
使用实例
# top
top - 12:26:46 up 1 day, 13:32, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.7%id, 0.1%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 625344k total, 571504k used, 53840k free, 65800k buffers
Swap: 524280k total, 0k used, 524280k free, 409280k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19002 root 20 0 2656 1068 856 R 0.3 0.2 0:01.87 top
1 root 20 0 2872 1416 1200 S 0.0 0.2 0:02.55 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd
第一行为任务队列信息
| 内 容 | 说 明 |
|---|---|
| 12:26:46 | 系统当前时间 |
| up 1 day, 13:32 | 系统的运行时间.本机己经运行 1 天 13 小时 32 分钟 |
| 2 users | 当前登录了两个用户 |
| load average: 0.00,0.00,0.00 | 系统在之前 1 分钟、5 分钟、15 分钟的平均负载。如果 CPU 是单核的,则这个数值超过 1 就是高负载:如果 CPU 是四核的,则这个数值超过 4 就是高负载 (这个平均负载完全是依据个人经验来进行判断的,一般认为不应该超过服务器 CPU 的核数) |
第二行为进程信息
| 内 容 | 说 明 |
|---|---|
| Tasks: 95 total | 系统中的进程总数 |
| 1 running | 正在运行的进程数 |
| 94 sleeping | 睡眠的进程数 |
| 0 stopped | 正在停止的进程数 |
| 0 zombie | 僵尸进程数。如果不是 0,则需要手工检查僵尸进程 |
第三行为 CPU 信息
| 内 容 | 说 明 |
|---|---|
| Cpu(s): 0.1 %us | 用户模式占用的 CPU 百分比 |
| 0.1%sy | 系统模式占用的 CPU 百分比 |
| 0.0%ni | 改变过优先级的用户进程占用的 CPU 百分比 |
| 99.7%id | 空闲 CPU 占用的 CPU 百分比 |
| 0.1%wa | 等待输入/输出的进程占用的 CPU 百分比 |
| 0.0%hi | 硬中断请求服务占用的 CPU 百分比 |
| 0.1%si | 软中断请求服务占用的 CPU 百分比 |
| 0.0%st | st(steal time)意为虚拟时间百分比,就是当有虚拟机时,虚拟 CPU 等待实际 CPU 的时间百分比 |
第四行为物理内存信息
| 内 容 | 说 明 |
|---|---|
| Mem: 625344k total | 物理内存的总量,单位为 KB |
| 571504k used | 己经使用的物理内存数量 |
| 53840k free | 空闲的物理内存数量。我们使用的是虚拟机,共分配了 628MB 内存,所以只有 53MB 的空闲内存 |
| 65800k buffers/cache | 作为缓冲的内存数量 |
缓冲(buffer)和缓存(cache)的区别:
- 缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取。
- 缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
第五行为交换分区(swap)信息
| 内 容 | 说 明 |
|---|---|
| Swap: 524280k total | 交换分区(虚拟内存)的总大小 |
| Ok used | 已经使用的交换分区的大小 |
| 524280k free | 空闲交换分区的大小 |
| 409280k cached | 作为缓存的交换分区的大小 |
第六行为系统进程信息
再来看 top 命令的第二部分输出,主要是系统进程信息,各个字段的含义如下:
- PID:进程的 ID。
- USER:该进程所属的用户。
- PR:优先级,数值越小优先级越高。
- NI:优先级,数值越小、优先级越高。
- VIRT:该进程使用的虚拟内存的大小,单位为 KB。
- RES:该进程使用的物理内存的大小,单位为 KB。
- SHR:共享内存大小,单位为 KB。
- S:进程状态。
- %CPU:该进程占用 CPU 的百分比。
- %MEM:该进程占用内存的百分比。
- TIME+:该进程共占用的 CPU 时间。
- COMMAND:进程的命令名。
htop
htop 是一个 Linux 下的交互式的进程浏览器,可以用来替换 Linux 下的 top 命令。
与 Linux 传统的 top 相比,htop 更加人性化。它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
bpytop
Linux/OSX/FreeBSD resource monitor
lsof
简介
lsof 命令,“list opened files”的缩写,直译过来,就是列举系统中已经被打开的文件。通过 lsof 命令,我们就可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。
在 linux 环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过 lsof 工具能够查看这个列表对系统监测以及排错将是很有帮助的。
在终端下输入 lsof 即可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
$ sudo lsof | less
COMMAND PID TID TASKCMD USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root cwd DIR 8,2 4096 2 /
systemd 1 root rtd DIR 8,2 4096 2 /
systemd 1 root txt REG 8,2 1620224 2491035 /usr/lib/systemd/systemd
systemd 1 root mem REG 8,2 1369352 2498532 /usr/lib/x86_64-linux-gnu/libm-2.31.so
systemd 1 root mem REG 8,2 178528 2490726 /usr/lib/x86_64-linux-gnu/libudev.so.1.6.17
输出各列信息的意义如下:
-
COMMAND:进程的名称
-
PID:进程标识符
-
PPID:父进程标识符(需要指定-R 参数)
-
USER:进程所有者
-
PGID:进程所属组
-
FD:文件描述符(filedescriptor,简称 fd),应用程序通过文件描述符识别该文件类型。
例如 cwd 表示 current work dirctory,即应用程序的当前工作目录,这是该应用程序启动的目录,除非它本身对这个目录进行更改。txt 表示该类型的文件是程序代码,如应用程序二进制文件本身或共享库,如上列表中显示的
/usr/lib/systemd/systemd程序。 -
TYPE:文件类型,如 DIR、REG 等,常见的文件类型:
- DIR:目录
- REG:普通文件
- CHR:字符
- BLK:块设备类型
- UNIX: UNIX 域套接字
- FIFO:先进先出 (FIFO) 队列
- IPv4:网际协议 (IP) 套接字
-
DEVICE:指定磁盘的名称
-
SIZE:文件的大小
-
NODE:索引节点(文件在磁盘上的标识)
-
NAME:打开文件的确切名称
命令参数
| 参数 | 含义 |
|---|---|
| -a | 列出打开文件存在的进程 |
| -c <进程名> | 列出指定进程名所打开的文件 |
| -g | 列出 GID 号进程详情 |
| -d <文件号> | 列出占用该文件号的进程 |
| +d <目录> | 列出目录下被打开的文件 |
| +D <目录> | 递归列出目录下被打开的文件 |
| -n <目录> | 列出使用 NFS 的文件 |
| -i <条件> | 列出符合条件的进程 |
| -p <进程号> | 列出指定进程号所打开的文件 |
| -u | 列出 UID 号进程详情 |
| -h | 显示帮助信息 |
| -v | 显示版本信息 |
使用实例
查询某个文件被哪个进程调用
lsof /bin/bash
查询某个目录下所有的文件是被哪些进程调用的
lsof +d /usr/lib
查看以 httpd 开头的进程调用了哪些文件
lsof -c httpd
查询 PID 是 1 的进程调用的文件
lsof -p 1
按照用户名查询某个用户的进程调用的文件
lsof -u username
列出某个用户以及某个进程所打开的文件信息
lsof -u test -c mysql
列出所有的网络连接
lsof -i
列出所有 tcp 网络连接信息
lsof -i tcp
列出谁在使用某个端口
lsof -i :3306
列出某个用户的所有活跃的网络端口
lsof -a -u test -i
根据文件描述列出对应的文件信息
lsof -d txt
列出被进程号为 1234 的进程所打开的所有 IPV4 network files
lsof -i 4 -a -p 1234
列出目前连接主机 nf5260i5-td 上端口为:20,21,80 相关的所有文件信息,且每隔 3 秒重复执行
lsof -i @nf5260i5-td:20,21,80 -r 3
write
在服务器上,有时会有多个用户同时登录,一些必要的沟通就显得尤为重要。比如,我必须关闭某个服务,或者需要重启服务器,当然需要通知同时登录服务器的用户,这时就可以使用 write 命令。
write 命令的信息如下:
- 命令名称:write。
- 英文原意:send a message to another user。
- 所在路径:/usr/bin/write。
- 执行权限:所有用户。
- 功能描述:向其他用户发送信息。
write 命令的基本格式如下:
write 用户名 [终端号]
write 命令没有多余的选项,我们要向在某个终端登录的用户发送信息,就可以这样来执行命令:
# 向在pts/1 (远程终端1)登录的user1用户发送信息,使用"Ctrl+D"快捷键保存发送的数据
$ write user1 pts/1
hello
I will be in 5 minutes to restart, please save your data
这时,user1 用户就可以收到你要在 5 分钟之后重启系统的信息了。
xargs
标准输入与管道命令
Unix 命令都带有参数,有些命令可以接受"标准输入"(stdin)作为参数。
cat /etc/passwd | grep root
上面的代码使用了管道命令(|)。管道命令的作用,是将左侧命令(cat /etc/passwd)的标准输出转换为标准输入,提供给右侧命令(grep root)作为参数。
因为grep命令可以接受标准输入作为参数,所以上面的代码等同于下面的代码。
grep root /etc/passwd
但是,大多数命令都不接受标准输入作为参数,只能直接在命令行输入参数,这导致无法用管道命令传递参数。举例来说,echo命令就不接受管道传参。
echo "hello world" | echo
上面的代码不会有输出。因为管道右侧的echo不接受管道传来的标准输入作为参数。
xargs 命令的作用
xargs命令的作用,是将标准输入转为命令行参数。
$ echo "hello world" | xargs echo
hello world
上面的代码将管道左侧的标准输入,转为命令行参数hello world,传给第二个echo命令。
xargs命令的格式如下。
xargs [-options] [command]
真正执行的命令,紧跟在xargs后面,接受xargs传来的参数。
xargs的作用在于,大多数命令(比如rm、mkdir、ls)与管道一起使用时,都需要xargs将标准输入转为命令行参数。
echo "one two three" | xargs mkdir
上面的代码等同于mkdir one two three。如果不加xargs就会报错,提示mkdir缺少操作参数。
xargs 的单独使用
xargs后面的命令默认是echo。
$ xargs
# 等同于
$ xargs echo
大多数时候,xargs命令都是跟管道一起使用的。但是,它也可以单独使用。
输入xargs按下回车以后,命令行就会等待用户输入,作为标准输入。你可以输入任意内容,然后按下Ctrl d,表示输入结束,这时echo命令就会把前面的输入打印出来。
$ xargs
hello
(Ctrl + d)
hello
再看一个例子。
$ xargs find -name
"*.txt"
./foo.txt
./hello.txt
上面的例子输入xargs find -name以后,命令行会等待用户输入所要搜索的文件。用户输入"*.txt",表示搜索当前目录下的所有 TXT 文件,然后按下Ctrl d,表示输入结束。这时就相当执行find -name *.txt。
-d 参数与分隔符
默认情况下,xargs将换行符和空格作为分隔符,把标准输入分解成一个个命令行参数。
echo "one two three" | xargs mkdir
上面代码中,mkdir会新建三个子目录,因为xargs将one two three分解成三个命令行参数,执行mkdir one two three。
-d参数可以更改分隔符。
$ echo -e "a\tb\tc" | xargs -d "\t" echo
a b c
上面的命令指定制表符\t作为分隔符,所以a\tb\tc就转换成了三个命令行参数。echo命令的-e参数表示解释转义字符。
-p 参数,-t 参数
使用xargs命令以后,由于存在转换参数过程,有时需要确认一下到底执行的是什么命令。
-p参数打印出要执行的命令,询问用户是否要执行。
$ echo 'one two three' | xargs -p touch
touch one two three ?...
上面的命令执行以后,会打印出最终要执行的命令,让用户确认。用户输入y以后(大小写皆可),才会真正执行。
-t参数则是打印出最终要执行的命令,然后直接执行,不需要用户确认。
$ echo 'one two three' | xargs -t rm
rm one two three
-0 参数与 find 命令
由于xargs默认将空格作为分隔符,所以不太适合处理文件名,因为文件名可能包含空格。
find命令有一个特别的参数-print0,指定输出的文件列表以null分隔。然后,xargs命令的-0参数表示用null当作分隔符。
find /path -type f -print0 | xargs -0 rm
上面命令删除/path路径下的所有文件。由于分隔符是null,所以处理包含空格的文件名,也不会报错。
还有一个原因,使得xargs特别适合find命令。有些命令(比如rm)一旦参数过多会报错"参数列表过长",而无法执行,改用xargs就没有这个问题,因为它对每个参数执行一次命令。
find . -name "*.txt" | xargs grep "abc"
上面命令找出所有 TXT 文件以后,对每个文件搜索一次是否包含字符串abc。
-L 参数
如果标准输入包含多行,-L参数指定多少行作为一个命令行参数。
$ xargs find -name
"*.txt"
"*.md"
find: paths must precede expression: `*.md'
上面命令同时将"*.txt"和*.md两行作为命令行参数,传给find命令导致报错。
使用-L参数,指定每行作为一个命令行参数,就不会报错。
$ xargs -L 1 find -name
"*.txt"
./foo.txt
./hello.txt
"*.md"
./README.md
上面命令指定了每一行(-L 1)作为命令行参数,分别运行一次命令(find -name)。
下面是另一个例子。
$ echo -e "a\nb\nc" | xargs -L 1 echo
a
b
c
上面代码指定每行运行一次echo命令,所以echo命令执行了三次,输出了三行。
-n 参数
-L参数虽然解决了多行的问题,但是有时用户会在同一行输入多项。
$ xargs find -name
"*.txt" "*.md"
find: paths must precede expression: `*.md'
上面的命令将同一行的两项作为命令行参数,导致报错。
-n参数指定每次将多少项,作为命令行参数。
xargs -n 1 find -name
上面命令指定将每一项(-n 1)标准输入作为命令行参数,分别执行一次命令(find -name)。
下面是另一个例子。
$ echo {0..9} | xargs -n 2 echo
0 12 34 56 78 9
上面命令指定,每两个参数运行一次echo命令。所以,10 个阿拉伯数字运行了五次echo命令,输出了五行。
-I 参数
如果xargs要将命令行参数传给多个命令,可以使用-I参数。
-I指定每一项命令行参数的替代字符串。
$ cat foo.txt
one
two
three
$ cat foo.txt | xargs -I file sh -c 'echo file; mkdir file'
one
two
three
$ ls
one two three
上面代码中,foo.txt是一个三行的文本文件。我们希望对每一项命令行参数,执行两个命令(echo和mkdir),使用-I file表示file是命令行参数的替代字符串。执行命令时,具体的参数会替代掉echo file; mkdir file里面的两个file。
–max-procs 参数
xargs默认只用一个进程执行命令。如果命令要执行多次,必须等上一次执行完,才能执行下一次。
--max-procs参数指定同时用多少个进程并行执行命令。--max-procs 2表示同时最多使用两个进程,--max-procs 0表示不限制进程数。
docker ps -q | xargs -n 1 --max-procs 0 docker kill
上面命令表示,同时关闭尽可能多的 Docker 容器,这样运行速度会快很多。
awk
awk是处理文本文件的一个应用程序,几乎所有 Linux 系统都自带这个程序。
它依次处理文件的每一行,并读取里面的每一个字段。对于日志、CSV 那样的每行格式相同的文本文件,awk可能是最方便的工具。
awk其实不仅仅是工具软件,还是一种编程语言。不过,本文只介绍它的命令行用法,对于大多数场合,应该足够用了。
基本用法
awk的基本用法就是下面的形式。
# 格式
$ awk 动作 文件名
# 示例
$ awk '{print $0}' demo.txt
上面示例中,demo.txt是awk所要处理的文本文件。前面单引号内部有一个大括号,里面就是每一行的处理动作print $0。其中,print是打印命令,$0代表当前行,因此上面命令的执行结果,就是把每一行原样打印出来。
下面,我们先用标准输入(stdin)演示上面这个例子。
$ echo 'this is a test' | awk '{print $0}'
this is a test
上面代码中,print $0就是把标准输入this is a test,重新打印了一遍。
awk会根据空格和制表符,将每一行分成若干字段,依次用$1、$2、$3代表第一个字段、第二个字段、第三个字段等等。
$ echo 'this is a test' | awk '{print $3}'
a
上面代码中,$3代表this is a test的第三个字段a。
下面,为了便于举例,我们把/etc/passwd文件保存成demo.txt。
root❌0:0:root:/root:/usr/bin/zsh
daemon❌1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin❌2:2:bin:/bin:/usr/sbin/nologin
sys❌3:3:sys:/dev:/usr/sbin/nologin
sync❌4:65534:sync:/bin:/bin/sync
这个文件的字段分隔符是冒号(:),所以要用-F参数指定分隔符为冒号。然后,才能提取到它的第一个字段。
$ awk -F ':' '{ print $1 }' demo.txt
root
daemon
bin
sys
sync
变量
除了$ + 数字表示某个字段,awk还提供其他一些变量。
变量NF表示当前行有多少个字段,因此$NF就代表最后一个字段。
$ echo 'this is a test' | awk '{print $NF}'
test
$(NF-1)代表倒数第二个字段。
$ awk -F ':' '{print $1, $(NF-1)}' demo.txt
root /root
daemon /usr/sbin
bin /bin
sys /dev
sync /bin
上面代码中,print命令里面的逗号,表示输出的时候,两个部分之间使用空格分隔。
变量NR表示当前处理的是第几行。
$ awk -F ':' '{print NR ") " $1}' demo.txt
1) root
2) daemon
3) bin
4) sys
5) sync
上面代码中,print命令里面,如果原样输出字符,要放在双引号里面。
awk的其他内置变量如下。
FILENAME:当前文件名FS:字段分隔符,默认是空格和制表符。RS:行分隔符,用于分割每一行,默认是换行符。OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。OFMT:数字输出的格式,默认为%.6g。
函数
awk还提供了一些内置函数,方便对原始数据的处理。
函数toupper()用于将字符转为大写。
$ awk -F ':' '{ print toupper($1) }' demo.txt
ROOT
DAEMON
BIN
SYS
SYNC
上面代码中,第一个字段输出时都变成了大写。
其他常用函数如下。
tolower():字符转为小写。length():返回字符串长度。substr():返回子字符串。sin():正弦。cos():余弦。sqrt():平方根。rand():随机数。
awk内置函数的完整列表,可以查看手册。
条件
awk允许指定输出条件,只输出符合条件的行。
输出条件要写在动作的前面。
awk '条件 动作' 文件名
请看下面的例子。
$ awk -F ':' '/usr/ {print $1}' demo.txt
root
daemon
bin
sys
上面代码中,print命令前面是一个正则表达式,只输出包含usr的行。
下面的例子只输出奇数行,以及输出第三行以后的行。
# 输出奇数行
$ awk -F ':' 'NR % 2 == 1 {print $1}' demo.txt
root
bin
sync
# 输出第三行以后的行
$ awk -F ':' 'NR >3 {print $1}' demo.txt
sys
sync
下面的例子输出第一个字段等于指定值的行。
$ awk -F ':' '$1 == "root" {print $1}' demo.txt
root
$ awk -F ':' '$1 == "root" || $1 == "bin" {print $1}' demo.txt
root
bin
if 语句
awk提供了if结构,用于编写复杂的条件。
$ awk -F ':' '{if ($1 > "m") print $1}' demo.txt
root
sys
sync
上面代码输出第一个字段的第一个字符大于m的行。
if结构还可以指定else部分。
$ awk -F ':' '{if ($1 > "m") print $1; else print "---"}' demo.txt
root
---
---
sys
sync
find
find 命令由 POSIX 规范 定义,它创建了一个用于衡量 POSIX 系统的开放标准,这包括 Linux、BSD 和 macOS。简而言之,只要你运行的是 Linux、BSD 或 macOS,那么 find 已经安装了。
但是,并非所有的 find 命令都完全相同。例如,GNU 的 find 命令有一些 BSD、Busybox 或 Solaris 上 find 命令可能没有或有但实现方式不同的功能。本文使用 findutils 包中的 GNU find,因为它很容易获得且非常流行。本文演示的大多数命令都适用于 find 的其他实现,但是如果你在 Linux 以外的平台上尝试命令并得到非预期结果,尝试下载并安装 GNU 版本。
man 文档中给出的 find 命令的一般形式为:
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [path...] [expression]
其实[-H] [-L] [-P] [-D debugopts] [-Olevel]这几个选项并不常用(至少在我的日常工作中,没有用到过),上面的 find 命令的常用形式可以简化为:
find [path...] [expression]
-
path:find 命令所查找的目录路径。例如用
.来表示当前目录,用/来表示系统根目录 -
expression:expression 可以分为——“-options [-print -exec -ok …]”
-
-options,指定 find 命令的常用选项 -
-print,find 命令将匹配的文件输出到标准输出 -
-exec,find 命令对匹配的文件执行该参数所给出的 shell 命令。相应命令的形式为'command' { } \;,注意{ }和\;之间的空格find ./ -size 0 -exec rm {} \;删除文件大小为零的文件 (还可以以这样做:rm -i find ./ -size 0或find ./ -size 0 | xargs rm -f &)-
为了用 ls -l 命令列出所匹配到的文件,可以把 ls -l 命令放在 find 命令的-exec 选项中:
find . -type f -exec ls -l { } \; -
在/logs 目录中查找更改时间在 5 日以前的文件并删除它们:
find /logs -type f -mtime +5 -exec rm { } \; -
find . -name "*.txt" -exec echo {} \; -exec grep banana {} \; find . -type d -exec sh -c "echo -n {}; echo -n ' x '; echo {}" \;
-
-
-ok,和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的 shell 命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。find . -name "*.conf" -mtime +5 -ok rm { } \;在当前目录中查找所有文件名以.LOG 结尾、更改时间在 5 日以上的文件,并删除它们,只不过在删除之前先给出提示
-
也有人这样总结 find 命令的结构:
find start_directory
options
criteria_to_match
action_to_perform_on_results
常用选项
-name按照文件名查找文件。find /dir -name filename在/dir 目录及其子目录下面查找名字为 filename 的文件find . -name "*.c"在当前目录及其子目录(用“.”表示)中查找任何扩展名为“c”的文件-perm按照文件权限来查找文件。find . -perm 755 –print在当前目录下查找文件权限位为 755 的文件,即文件属主可以读、写、执行,其它用户可以读、执行的文件-prune使用这一选项可以使 find 命令不在当前指定的目录中查找,如果同时使用-depth 选项,那么-prune 将被 find 命令忽略。find /apps -path "/apps/bin" -prune -o –print在/apps 目录下查找文件,但不希望在/apps/bin 目录下查找find /usr/sam -path "/usr/sam/dir1" -prune -o –print在/usr/sam 目录下查找不在 dir1 子目录之内的所有文件-user按照文件属主来查找文件。find ~ -user sam –print在$HOME 目录中查找文件属主为 sam 的文件-group按照文件所属的组来查找文件。find /apps -group gem –print在/apps 目录下查找属于 gem 用户组的文件-mtime -n +n按照文件的更改时间来查找文件, - n 表示文件更改时间距现在 n 天以内,+ n 表示文件更改时间距现在 n 天以前。find / -mtime -5 –print在系统根目录下查找更改时间在 5 日以内的文件find /var/adm -mtime +3 –print在/var/adm 目录下查找更改时间在 3 日以前的文件-nogroup查找无有效所属组的文件,即该文件所属的组在/etc/groups 中不存在。find / –nogroup -print-nouser查找无有效属主的文件,即该文件的属主在/etc/passwd 中不存在。find /home -nouser –print-newer file1 ! file2查找更改时间比文件 file1 新但比文件 file2 旧的文件。-type查找某一类型的文件,诸如: b - 块设备文件。 d - 目录。 c - 字符设备文件。 p - 管道文件。 l - 符号链接文件。 f - 普通文件。find /etc -type d –print在/etc 目录下查找所有的目录find . ! -type d –print在当前目录下查找除目录以外的所有类型的文件find /etc -type l –print在/etc 目录下查找所有的符号链接文件-size n:[c] 查找文件长度为 n 块的文件,带有 c 时表示文件长度以字节计。find . -size +1000000c –print在当前目录下查找文件长度大于 1 M 字节的文件find /home/apache -size 100c –print在/home/apache 目录下查找文件长度恰好为 100 字节的文件find . -size +10 –print在当前目录下查找长度超过 10 块的文件(一块等于 512 字节)-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。find / -name "CON.FILE" -depth –print它将首先匹配所有的文件然后再进入子目录中查找-mount:在查找文件时不跨越文件系统 mount 点。find . -name "*.XC" -mount –print从当前目录开始查找位于本文件系统中文件名以 XC 结尾的文件(不进入其它文件系统)-follow:如果 find 命令遇到符号链接文件,就跟踪至链接所指向的文件。
按名称查找文件
你可以借助正则表达式使用完整或部分的文件名来定位文件。find 命令需要你给出想搜索的目录;指定搜索属性选项,例如,-name 用于指定区分大小写的文件名;然后是搜索字符串。默认情况下,搜索字符串按字面意思处理:除非你使用正则表达式语法,否则 find 命令搜索的文件名正是你在引号之间输入的字符串。
假设你的 Documents 目录包含四个文件:Foo、foo、foobar.txt 和 foo.xml。以下是对 foo 的字面搜索:
$ find ~ -name "foo"
/home/tux/Documents/examples/foo
你可以使用 -iname 选项使其不区分大小写来扩大搜索范围:
$ find ~ -iname "foo"
/home/tux/Documents/examples/foo
/home/tux/Documents/examples/Foo
通配符
你可以使用基本的 shell 通配符来扩展搜索。例如,* 表示任意数量的字符:
$ find ~ -iname "foo*"
/home/tux/Documents/examples/foo
/home/tux/Documents/examples/Foo
/home/tux/Documents/examples/foo.xml
/home/tux/Documents/examples/foobar.txt
? 表示单个字符:
$ find ~ -iname "foo*.???"
/home/tux/Documents/examples/foo.xml
/home/tux/Documents/examples/foobar.txt
这不是正则表达式语法,因此 . 在示例中只表示字母“点”。
正则表达式
你还可以使用正则表达式。与 -iname 和 -name 一样,也有区分大小写和不区分大小写的选项。但不一样的是,-regex 和 -iregex 搜索应用于整个路径,而不仅仅是文件名。这意味着,如果你搜索 foo,你不会得到任何结果,因为 foo 与 /home/tux/Documents/foo 不匹配。相反,你必须要么搜索整个路径,要么在字符串的开头使用通配符:
$ find ~ -iregex ".*foo"
/home/tux/Documents/examples/foo
/home/tux/Documents/examples/Foo
查找近一周修改过的文件
要查找近一周修改的文件,使用 -mtime 选项以及过去的天数(负数):
$ find ~ -mtime -7
/home/tux/Documents/examples/foo
/home/tux/Documents/examples/Foo
/home/tux/Documents/examples/foo.xml
/home/tux/Documents/examples/foobar.txt
查找近几天修改的文件
你可以结合使用 -mtime 选项来查找近几天范围内修改的文件。对于第一个 -mtime 参数,表示上一次修改文件的最近天数。第二个参数表示最大天数。例如,搜索修改时间超过 1 天但不超过 7 天的文件:
find ~ -mtime +1 -mtime -7
按文件类型限制搜索
指定查找文件的类型来优化 find 的结果是很常见的。如果你不确定要查找的内容,则不应该使用此选项。但如果你知道要查找的是文件而不是目录,或者是目录而不是文件,那么这可能是一个很好的过滤器。选项是 -type,它的参数是代表不同类型数据的字母代码。最常见的是:
d- 目录f- 文件l- 链接文件s- 套接字p- 命名管道(用于 FIFO)b- 块设备(通常是硬盘)
下面是一些例子:
$ find ~ -type d -name "Doc*"
/home/tux/Documents
$ find ~ -type f -name "Doc*"
/home/tux/Downloads/10th-Doctor.gif
$ find /dev -type b -name "sda*"
/dev/sda/dev/sda1
调整范围
find 命令默认是递归的,这意味着它会在指定的目录中层层搜索结果。这在大型文件系统中可能会变得不堪重负,但你可以使用 -maxdepth 选项来控制搜索深度:
$ find /usr -iname "*xml" | wc -l
15588
$ find /usr -maxdepth 2 -iname "*xml" | wc -l
15
也可以使用 -mindepth 设置最小递归深度:
$ find /usr -mindepth 8 -iname "*xml" | wc -l
9255
与 xargs
在使用 find 命令的-exec 选项处理匹配到的文件时, find 命令将所有匹配到的文件一起传递给 exec 执行。但有些系统对能够传递给 exec 的命令长度有限制,这样在 find 命令运行几分钟之后,就会出现溢出错误。错误信息通常是“参数列太长”或“参数列溢出”。这就是 xargs 命令的用处所在,特别是与 find 命令一起使用。
find 命令把匹配到的文件传递给 xargs 命令,而 xargs 命令每次只获取一部分文件而不是全部,不像-exec 选项那样。这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。
在有些系统中,使用-exec 选项会为处理每一个匹配到的文件而发起一个相应的进程,并非将匹配到的文件全部作为参数一次执行;这样在有些情况下就会出现进程过多,系统性能下降的问题,因而效率不高;
而使用 xargs 命令则只有一个进程。另外,在使用 xargs 命令时,究竟是一次获取所有的参数,还是分批取得参数,以及每一次获取参数的数目都会根据该命令的选项及系统内核中相应的可调参数来确定。
来看看 xargs 命令是如何同 find 命令一起使用的,并给出一些例子。
find . -type f -print | xargs file查找系统中的每一个普通文件,然后使用 xargs 命令来测试它们分别属于哪类文件
find / -name "core" -print | xargs echo "" >/tmp/core.log 在整个系统中查找内存信息转储文件(core dump) ,然后把结果保存到/tmp/core.log 文件中:
find . -type f -print | xargs grep "hostname" 用 grep 命令在所有的普通文件中搜索 hostname 这个词
find ./ -mtime +3 -print|xargs rm -f –r删除 3 天以前的所有东西 (find . -ctime +3 -exec rm -rf {} \;)
find ./ -size 0 | xargs rm -f & 删除文件大小为零的文件
find 命令配合使用 exec 和 xargs 可以使用户对所匹配到的文件执行几乎所有的命令。
fd
fd 命令是一个流行的、用户友好的 find 命令的替代品。
Find files by file type
find . -type f -exec bash -c '
[[ "$( file -bi "$1" )" == */x-shellscript* ]]' bash {} \; -print
基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"
同上,但忽略大小写
find . -iregex ".*\(\.txt\|\.pdf\)$"
grep
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep 这个名字,来源于一个 Unix/Linux 中的古老的行编辑器 ed 中执行相似操作的命令:
g/re/p
语法如下所示:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
grep 命令用于搜索由 Pattern 参数指定的模式,并将每个匹配的行写入标准输出中。这些模式是具有限定的正则表达式,它们使用 ed 或 egrep 命令样式。
如果在 File 参数中指定了多个名称,grep 命令将显示包含匹配行的文件的名称。
对 shell 有特殊含义的字符 ($, *, [, |, ^, (, ), \ ) 出现在 Pattern 参数中时必须带双引号。如果 Pattern 参数不是简单字符串,通常必须用单引号将整个模式括起来。在诸如 [a-z], 之类的表达式中,-(减号)cml 可根据当前正在整理的序列来指定一个范围。整理序列可以定义等价的类以供在字符范围中使用。
如果未指定任何文件,grep 会假定为标准输入。
基本集
grep 正则表达式元字符集:
^锚定行的开始 如:'^grep'匹配所有以 grep 开头的行。$锚定行的结束 如:'grep$'匹配所有以 grep 结尾的行。.匹配一个非换行符的字符 如:'gr.p'匹配 gr 后接一个任意字符,然后是 p。*匹配零个或多个先前字符 如:' *grep'匹配所有一个或多个空格后紧跟 grep 的行。.*一起用代表任意字符。[]匹配一个指定范围内的字符,如'[Gg]rep'匹配 Grep 和 grep。[^]匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含 A-F 和 H-Z 的一个字母开头,紧跟 rep 的行。\(..\)标记匹配字符,如:'\(love\)',love 被标记为 1。\<锚定单词的开始,如:'\<\>锚定单词的结束,如grep\>'匹配包含以 grep 结尾的单词的行。x\{m\}连续重复字符 x,m 次,如:'o\{5\}'匹配包含连续 5 个 o 的行。x\{m,\}连续重复字符 x,至少 m 次,如:'o\{5,\}'匹配至少连续有 5 个 o 的行。x\{m,n\}连续重复字符 x,至少 m 次,不多于 n 次,如:'o\{5,10\}'匹配连续 5–10 个 o 的行。\w匹配一个文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以 G 后跟零个或多个文字或数字字符,然后是 p。\Ww 的反置形式,匹配一个非单词字符,如点号句号等。\W*则可匹配多个。\b单词锁定符,如:'\bgrep\b'只匹配 grep,即只能是 grep 这个单词,两边均为空格。
常用选项
-?
同时显示匹配行上下的?行,如:grep -2 pattern filename 同时显示匹配行的上下 2 行。
-b,--byte-offset
打印匹配行前面打印该行所在的块号码。
-c,--count
只打印匹配的行数,不显示匹配的内容。
-f File,--file=File
从文件中提取模板。空文件中包含 0 个模板,所以什么都不匹配。
-h,--no-filename
当搜索多个文件时,不显示匹配文件名前缀。
-i,--ignore-case
忽略大小写差别。
-q,--quiet
取消显示,只返回退出状态。0 则表示找到了匹配的行。
-l,--files-with-matches
打印匹配模板的文件清单。
-L,--files-without-match
打印不匹配模板的文件清单。
-n,--line-number
在匹配的行前面打印行号。
-s,--silent
不显示关于不存在或者无法读取文件的错误信息。
-v,--revert-match
反检索,只显示不匹配的行。
-w,--word-regexp
如果被\引用,就把表达式做为一个单词搜索。
-V,--version
显示软件版本信息。
怎么样使用 grep 来搜索一个文件
搜索 /etc/passwd 文件下的 boo 用户,输入:
grep boo /etc/passwd
输出内容:
foo❌1000:1000:foo,,,:/home/foo:/bin/ksh
可以使用 grep 去强制忽略大小写。例如,使用 -i 选项可以匹配 boo, Boo, BOO 和其他组合:
grep -i "boo" /etc/passwd
递归使用 grep
你可以递归地使用 grep 进行搜索。例如,在文件目录下面搜索所有包含字符串“192.168.1.5”的文件
grep -r "192.168.1.5" /etc/
或者是:
grep -R "192.168.1.5" /etc/
示例输出:
/etc/ppp/options:# ms-wins 192.168.1.50/etc/ppp/options:# ms-wins 192.168.1.51/etc/NetworkManager/system-connections/Wired connection 1:addresses1=192.168.1.5;24;192.168.1.2;
你会看到搜索到 192.168.1.5 的结果每一行都前缀以找到匹配的文件名(例如:/etc/ppp/options)。输出之中包含的文件名可以加 -h 选项来禁止输出:
grep -h -R "192.168.1.5" /etc/
或者
grep -hR "192.168.1.5" /etc/
示例输出:
# ms-wins 192.168.1.50# ms-wins 192.168.1.51addresses1=192.168.1.5;24;192.168.1.2;
使用 grep 去搜索文本
当你搜索 boo 时,grep 命令将会匹配 fooboo,boo123, barfoo35 和其他所有包含 boo 的字符串,你可以使用 -w 选项去强制只输出那些仅仅包含那个整个单词的行(LCTT 译注:即该字符串两侧是英文单词分隔符,如空格,标点符号,和末端等,因此对中文这种没有断字符号的语言并不适用。)。
grep -w "boo" file
使用 grep 命令去搜索两个不同的单词
使用 egrep 命令如下:
egrep -w 'word1|word2' /path/to/file
(LCTT 译注:这里使用到了正则表达式,因此使用的是 egrep 命令,即扩展的 grep 命令。)
统计文本匹配到的行数
grep 命令可以通过加 -c 参数显示每个文件中匹配到的次数:
grep -c 'word' /path/to/file
传递 -n 选项可以输出的行前加入匹配到的行的行号:
grep -n 'root' /etc/passwd
示例输出:
1:root:x:0:0:root:/root:/bin/bash1042:rootdoor:x:0:0:rootdoor:/home/rootdoor:/bin/csh3319:initrootapp:x:0:0:initrootapp:/home/initroot:/bin/ksh
反转匹配(不匹配)
可以使用 -v 选项来输出不包含匹配项的内容,输出内容仅仅包含那些不含给定单词的行,例如输出所有不包含 bar 单词的行:
grep -v bar /path/to/file
UNIX/Linux 管道与 grep 命令
grep 常常与管道一起使用,在这个例子中,显示硬盘设备的名字:
# dmesg | egrep '(s|h)d[a-z]'
显示 CPU 型号:
# cat /proc/cpuinfo | grep -i 'Model'
然而,以上命令也可以按照以下方法使用,不使用管道:
# grep -i 'Model' /proc/cpuinfo
示例输出:
model : 30model name : Intel(R) Core(TM) i7 CPU Q 820 @ 1.73GHzmodel : 30model name : Intel(R) Core(TM) i7 CPU Q 820 @ 1.73GHz
仅仅显示匹配到内容的文件名
使用 -l 选项去显示那些文件内容中包含 main() 的文件名:
grep -l 'main' *.c
最后,你可以强制 grep 以彩色输出:
grep --color vivek /etc/passwd
查找文件内容
从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 “ERROR” 的行:
find / -type f -name "*.log" | xargs grep "ERROR"
例子:
#!/usr/bin/bash
IREGEX=".*\(\.txt\|\.md\|\.yaml\)$"
find . \
-type f \
-regex $IREGEX \
-print0 | xargs -0 grep -in "$1" 2>/dev/null
only matching
Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line.
grep -oh "\w*th\w*" *
cat
bat
A cat(1) clone with wings.
添加了语法高亮和 Git 集成等功能,并且还提供了分页选项。
ip
linux 的ip命令和ifconfig类似,但前者功能更强大,并旨在取代后者。使用 ip 命令,只需一个命令,你就能很轻松地执行一些网络管理任务。ifconfig 是 net-tools 中已被废弃使用的一个命令,许多年前就已经没有维护了。iproute2 套件里提供了许多增强功能的命令,ip 命令即是其中之一。
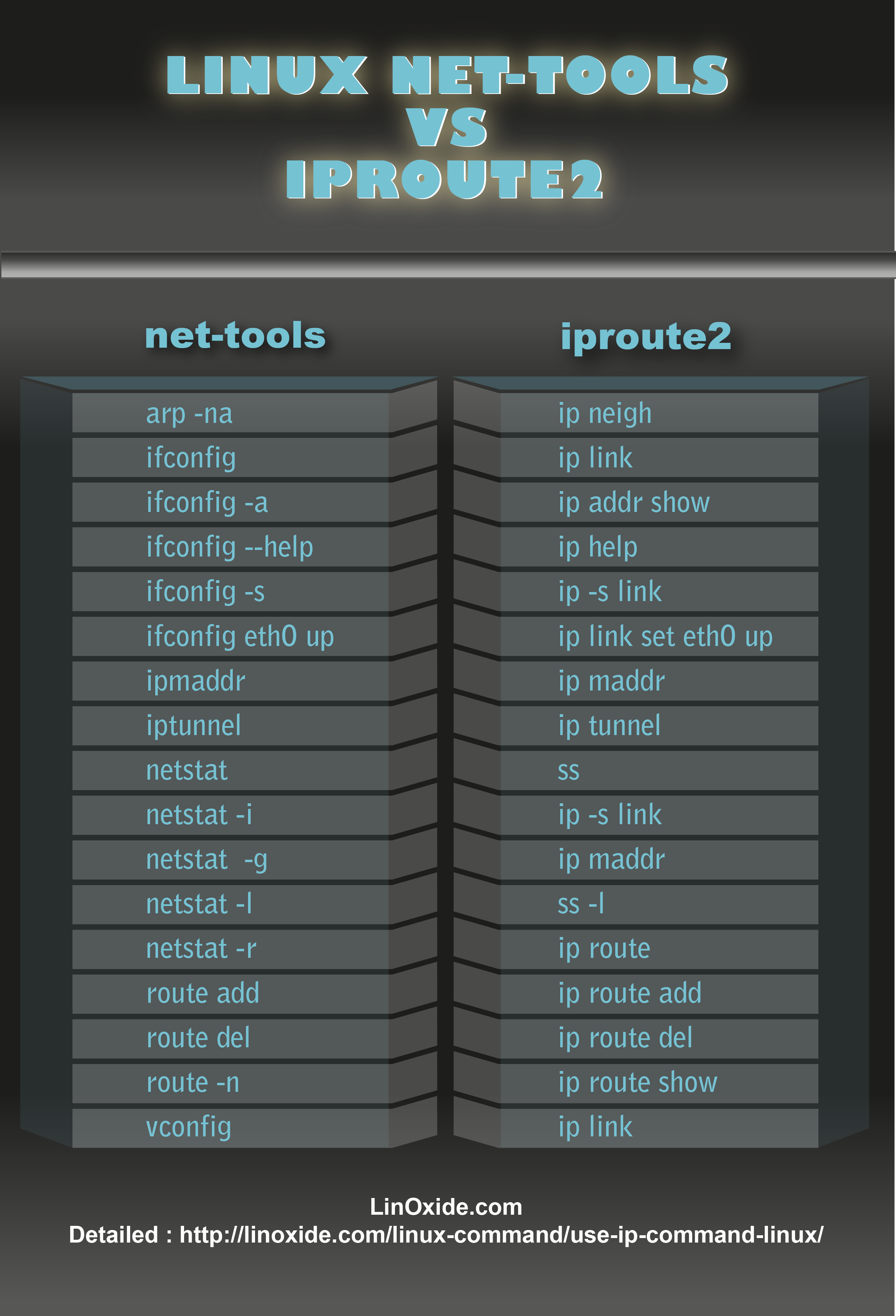
设置和删除 Ip 地址
要给你的机器设置一个 IP 地址,可以使用下列 ip 命令:
sudo ip addr add 192.168.0.193/24 dev wlan0
请注意 IP 地址要有一个后缀,比如/24。这种用法用于在无类域内路由选择(CIDR)中来显示所用的子网掩码。在这个例子中,子网掩码是 255.255.255.0。
在你按照上述方式设置好 IP 地址后,需要查看是否已经生效。
ip addr show wlan0
你也可以使用相同的方式来删除 IP 地址,只需用 del 代替 add。
sudo ip addr del 192.168.0.193/24 dev wlan0
列出路由表条目
ip 命令的路由对象的参数还可以帮助你查看网络中的路由数据,并设置你的路由表。第一个条目是默认的路由条目,你可以随意改动它。
在这个例子中,有几个路由条目。这个结果显示有几个设备通过不同的网络接口连接起来。它们包括 WIFI、以太网和一个点对点连接。
ip route show
假设现在你有一个 IP 地址,你需要知道路由包从哪里来。可以使用下面的路由选项(译注:列出了路由所使用的接口等):
ip route get 10.42.0.47
更改默认路由
要更改默认路由,使用下面 ip 命令:
sudo ip route add default via 192.168.0.196
显示网络统计数据
使用 ip 命令还可以显示不同网络接口的统计数据。
当你需要获取一个特定网络接口的信息时,在网络接口名字后面添加选项ls即可。使用多个选项**-s**会给你这个特定接口更详细的信息。特别是在排除网络连接故障时,这会非常有用。
ip -s -s link ls p2p1
ARP 条目
地址解析协议(ARP)用于将一个 IP 地址转换成它对应的物理地址,也就是通常所说的 MAC 地址。使用 ip 命令的 neigh 或者 neighbour 选项,你可以查看接入你所在的局域网的设备的 MAC 地址。
ip neighbour
监控 netlink 消息
也可以使用 ip 命令查看 netlink 消息。monitor 选项允许你查看网络设备的状态。比如,所在局域网的一台电脑根据它的状态可以被分类成 REACHABLE 或者 STALE。使用下面的命令:
ip monitor all
激活和停止网络接口
你可以使用 ip 命令的 up 和 down 选项来激某个特定的接口,就像 ifconfig 的用法一样。
在这个例子中,当 ppp0 接口被激活和在它被停止和再次激活之后,你可以看到相应的路由表条目。这个接口可能是 wlan0 或者 eth0。将 ppp0 更改为你可用的任意接口即可。
sudo ip link set ppp0 down
sudo ip link set ppp0 up
获取帮助
当你陷入困境,不知道某一个特定的选项怎么用的时候,你可以使用 help 选项。man 页面并不会提供许多关于如何使用 ip 选项的信息,因此这里就是获取帮助的地方。
比如,想知道关于 route 选项更多的信息:
ip route help
小结
对于网络管理员们和所有的 Linux 使用者们,ip 命令是必备工具。是时候抛弃 ifconfig 命令了,特别是当你写脚本时。
dig
使用 dig 来进行 DNS 查询。
参数类型:查询和格式化
有两种主要的参数可以传递给 dig:
- 告诉
dig要进行什么 DNS 查询的参数。 - 告诉
dig如何 格式化响应的参数。
首先,让我们看一下查询选项。
主要的查询选项
你通常想控制 DNS 查询的 3 件事是:
- 名称(如
jvns.ca)。默认情况下,查询的是空名称(.)。 - DNS 查询类型(如
A或CNAME)。默认是A。 - 发送查询的 服务器(如
8.8.8.8)。默认是/etc/resolv.conf中的内容。
其格式是:
dig @server name type
这里有几个例子:
dig @8.8.8.8 jvns.ca向谷歌的公共 DNS 服务器(8.8.8.8)查询jvns.ca。dig ns jvns.ca对jvns.ca进行类型为NS的查询。
-x:进行反向 DNS 查询
我偶尔使用的另一个查询选项是 -x,用于进行反向 DNS 查询。下面是输出结果的样子。
$ dig -x 172.217.13.174
174.13.217.172.in-addr.arpa. 72888 IN PTR yul03s04-in-f14.1e100.net。
-x 不是魔术。dig -x 172.217.13.174 只是对 174.13.217.172.in-addr.arpa. 做了一个 PTR 查询。下面是如何在不使用 `-x’ 的情况下进行完全相同的反向 DNS 查询。
$ dig ptr 174.13.217.172.in-addr.arpa.
174.13.217.172.in-addr.arpa. 72888 IN PTR yul03s04-in-f14.1e100.net。
我总是使用 -x,因为它可以减少输入。
DNS 反向查询大概的一个定义就是:
从 IP 地址获取 PTR 记录。也就是说,通过使用一些网络工具可以将 IP 地址转换为主机名。 实际上,PRT 代表 POINTER,在 DNS 系统有唯一性,将 IP 地址与规范化的主机名联系起来。PTR 记录其实是 NDS 系统的一部分,但是由专门的区域文件组成的,使用的是传统的 in-addr.arpa 格式。
格式化响应的选项
现在,让我们讨论一下你可以用来格式化响应的参数。
我发现 dig 默认格式化 DNS 响应的方式对初学者来说是很难接受的。下面是输出结果的样子:
; <<>> DiG 9.16.20 <<>> -r jvns.ca
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28629
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: d87fc3022c0604d60100000061ab74857110b908b274494d (good)
;; QUESTION SECTION:
;jvns.ca. IN A
;; ANSWER SECTION:
jvns.ca. 276 IN A 172.64.80.1
;; Query time: 9 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Sat Dec 04 09:00:37 EST 2021
;; MSG SIZE rcvd: 80
如果你不习惯看这个,你可能需要花点时间来筛选,找到你要找的 IP 地址。而且大多数时候,你只对这个响应中的一行感兴趣(jvns.ca. 180 IN A 172.64.80.1)。
下面是我最喜欢的两种方法,可以使 dig 的输出更容易管理:
方式 1 : +noall +answer
这告诉 dig 只打印 DNS 响应中的“答案”部分的内容。下面是一个查询 google.com 的 NS 记录的例子:
$ dig +noall +answer ns google.com
google.com. 158564 IN NS ns4.google.com.
google.com. 158564 IN NS ns1.google.com.
google.com. 158564 IN NS ns2.google.com.
google.com. 158564 IN NS ns3.google.com.
这里的格式是:
NAME TTL TYPE CONTENT
google.com 158564 IN NS ns3.google.com.
顺便说一下:如果你曾经想知道 IN 是什么意思,它是指“查询类”,代表“互联网 internet”。它基本上只是上世纪 80、90 年代的遗物,当时还有其他网络与互联网竞争,如“混沌网络 chaosnet”。
方式 2:+short
这就像 dig +noall +answer,但更短:它只显示每条记录的内容。比如说:
$ dig +short ns google.com
ns2.google.com.
ns1.google.com.
ns4.google.com.
ns3.google.com.
digrc
如果你不喜欢 dig 的默认格式(我就不喜欢!),你可以在你的主目录下创建一个 .digrc 文件,告诉它默认使用不同的格式。
我非常喜欢 +noall +answer 格式,所以我把 +noall +answer 放在我的 ~/.digrc 中。下面是我使用该配置文件运行 dig jvns.ca 时的情况。
$ dig jvns.ca
jvns.ca. 255在172.64.80.1中
这样读起来就容易多了!
如果我想回到所有输出的长格式(我有时会这样做,通常是因为我想看响应的权威部分的记录),我可以通过运行再次得到一个长答案。
dig +all jvns.ca
dig +trace
我使用的最后一个 dig 选项是 +trace。dig +trace 模仿 DNS 解析器在查找域名时的做法 —— 它从根域名服务器开始,然后查询下一级域名服务器(如 .com),以此类推,直到到达该域名的权威域名服务器。因此,它将进行大约 30 次 DNS 查询。(我用 tcpdump 检查了一下,对于每个根域名服务器的 A / AAAA 记录它似乎要进行 2 次查询,所以这已经是 26 次查询了。我不太清楚它为什么这样做,因为它应该已经有了这些 IP 的硬编码,但它确实如此。)
我发现这对了解 DNS 的工作原理很有用,但我不认为我用它解决过问题。
为什么要用 dig
尽管有一些更简单的工具来进行 DNS 查询(如 dog 和 host),我发现自己还是坚持使用 dig。
我喜欢 dig 的地方实际上也是我 不喜欢 dig 的地方 —— 它显示了大量的细节!
我知道,如果我运行 dig +all,它将显示 DNS 响应的所有部分。例如,让我们查询 jvns.ca 的一个根名称服务器。响应有 3 个部分,我可能会关心:回答部分、权威部分和附加部分。
$ dig @h.root-servers.net. jvns.ca +all
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18229
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 9
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;jvns.ca. IN A
;; AUTHORITY SECTION:
ca. 172800 IN NS c.ca-servers.ca.
ca. 172800 IN NS j.ca-servers.ca.
ca. 172800 IN NS x.ca-servers.ca.
ca. 172800 IN NS any.ca-servers.ca.
;; ADDITIONAL SECTION:
c.ca-servers.ca. 172800 IN A 185.159.196.2
j.ca-servers.ca. 172800 IN A 198.182.167.1
x.ca-servers.ca. 172800 IN A 199.253.250.68
any.ca-servers.ca. 172800 IN A 199.4.144.2
c.ca-servers.ca. 172800 IN AAAA 2620:10a:8053::2
j.ca-servers.ca. 172800 IN AAAA 2001:500:83::1
x.ca-servers.ca. 172800 IN AAAA 2620:10a:80ba::68
any.ca-servers.ca. 172800 IN AAAA 2001:500:a7::2
;; Query time: 103 msec
;; SERVER: 198.97.190.53#53(198.97.190.53)
;; WHEN: Sat Dec 04 11:23:32 EST 2021
;; MSG SIZE rcvd: 289
dog 也显示了 “附加” 部分的记录,但它没有明确指出哪个是哪个(我猜 + 意味着它在附加部分?) ,但它似乎没有显示“权威”部分的记录。
$ dog @h.root-servers.net. jvns.ca
NS ca. 2d0h00m00s A "c.ca-servers.ca."
NS ca. 2d0h00m00s A "j.ca-servers.ca."
NS ca. 2d0h00m00s A "x.ca-servers.ca."
NS ca. 2d0h00m00s A "any.ca-servers.ca."
A c.ca-servers.ca. 2d0h00m00s + 185.159.196.2
A j.ca-servers.ca. 2d0h00m00s + 198.182.167.1
A x.ca-servers.ca. 2d0h00m00s + 199.253.250.68
A any.ca-servers.ca. 2d0h00m00s + 199.4.144.2
AAAA c.ca-servers.ca. 2d0h00m00s + 2620:10a:8053::2
AAAA j.ca-servers.ca. 2d0h00m00s + 2001:500:83::1
AAAA x.ca-servers.ca. 2d0h00m00s + 2620:10a:80ba::68
AAAA any.ca-servers.ca. 2d0h00m00s + 2001:500:a7::2
而 host 似乎只显示“答案”部分的记录(在这种情况下没有得到记录):
$ host jvns.ca h.root-servers.net
Using domain server:
Name: h.root-servers.net
Address: 198.97.190.53#53
Aliases:
总之,我认为这些更简单的 DNS 工具很好(我甚至自己做了一个 简单的网络 DNS 工具),如果你觉得它们更容易,你绝对应该使用它们,但这就是为什么我坚持使用 dig 的原因。drill 的输出格式似乎与 dig 的非常相似,也许 drill 更好!但我还没有真正试过它。
Samba
Samba 是 SMB/CIFS 网络协议的重新实现, 可以在 Linux 和 Windows 系统间进行文件、打印机共享,和 NFS 的功能类似。
安装
sudo apt install samba
sudo systemctl enable --now smbd.service
Samba 服务的配置文件是 /etc/samba/smb.conf,smb.conf(5)提供了详细的文档。
如果使用了 防火墙,请记得打开需要的端口(通常是 137-139 + 445)。完整列表请查看 Samba 端口使用。
sudo ufw allow Samba
sudo ufw reload
创建共享
创建的目录即之后能够在 Windows 主机上直接访问的目录。例如:在用户 samba_user 的主目录下新建 share 文件夹为共享目录,由于 Windows 下的文件夹需可读可写可执行,需更改权限为 777
mkdir /home/samba_user/smbshare
sudo chmod 777 /home/samba_user/smbshare
修改 /etc/samba/smb.conf,在 smb.conf 文件最后加上以下内容
$ sudo vim /etc/samba/smb.conf
[share]
path = /home/samba_user/smbshare
public = yes
writable = yes
valid users = samba_user
create mask = 0644
force create mode = 0644
directory mask = 0755
force directory mode = 0755
available = yes
- [share]表示共享文件夹的别名,之后将直接使用这个别名
force create mode与force directory mode的设置是因为 Windows 下与 Linux 下文件和文件夹的默认权限不同造成的,Windows 下新建的文件是可执行的,必须强制设定其文件权限。- valid users 设置为你当前的 Linux 用户名,例如我的是 samba_user,因为第一次打开共享文件夹时,需要验证权限。
用户管理
Samba 需要 Linux 账户才能使用 - 可以使用已有账户或创建新用户。
虽然用户名可以和 Linux 系统共享,Samba 使用单独的密码管理,将下面的 samba_user 替换为上面设置的 valid users:
sudo smbpasswd -a samba_user
根据服务器角色的差异,可能需要修改已有的文件权限和属性。
Which is faster-Samba or scp?
Depends on the machines. Machines with really fast CPU may do SCP or SFTP faster.
Otherwise, Samba will probably be faster because it doesn’t have to encrypt.
Connect to servers with nautilus
Step 1: find the “Other Locations” button on the left-hand side of the Gnome file manager and click on the mouse.
Step 2: make your way to the “Connect to Server” text box and tap on it with the mouse.
Step 3: write out smb:// followed by the IP address of the Samba file server. Alternatively, write out the hostname of the file server, as that works as well. Confused? Copy the examples below.
# ip address
smb://ip.address.of.samba.file.server
# hostname
smb://MyExampleSambaShare
ftp://ip.address.of.ftp.server
nfs://ip.address.of.nfs.server
Step 4: click on the “Connect” button to send out a new Samba connection. Assuming your file server has no user-name setup and is public, you’ll instantly see the files and be able to interact with the server.
However, if your server requires a username/password, you must fill out the username/password before using Samba.
Mount Samba Share in Linux
List available shares on server:
Install the samba client library:
sudo apt install smbclient
Then list the shares:
smbclient -L //<your-ip-address>
You will then be prompted to enter a password (assuming your share requires one) and then will output something like this:
Sharename Type Comment
--------- ---- -------
folder-mount-1 Disk Description 1
folder-mount-2 Disk Description 2
folder-mount-3 Disk Description 3
IPC$ IPC IPC Service (Server Name)
Note the share name that you want to mount for later.
Temp mount the share to a folder:
Install the cifs-utils package:
sudo apt install cifs-utils
Create the mount-point (folder) and then mount the share:
sudo mkdir /mnt/myFolder
sudo mount -t cifs -o username=serverUserName //myServerIpAdress/sharename /mnt/myFolder/
(Note: this will unmount upon reboot.)
Permanently mount the share to a folder:
Install the cifs-utils package:
sudo apt install cifs-utils
Create the mount-point (folder):
sudo mkdir /mnt/myFolder
Modify your fstab file:
sudo vi /etc/fstab
Place the following line at or near the bottom of the file:
//<your-ip-address>/<mount-name> /mnt/myFolder/ cifs username=YOURUSERNAME,password=YOURPASSWORD,iocharset=utf8,file_mode=0777,dir_mode=0777
(be sure to swap in your info into the line above)
Reboot your server and you should be off to the races. To confirm that it is still mounted, type df -h and look found your mount in the list.
sudo
简单的说,sudo 是一种权限管理机制,管理员可以授权于一些普通用户去执行一些 root 执行的操作,而不需要知道 root 的密码。
严谨些说,sudo 允许一个已授权用户以超级用户或者其它用户的角色运行一个命令。当然,能做什么不能做什么都是通过安全策略来指定的。sudo 支持插件架构的安全策略,并能把输入输出写入日志。第三方可以开发并发布自己的安全策略和输入输出日志插件,并让它们无缝的和 sudo 一起工作。默认的安全策略记录在 /etc/sudoers 文件中。而安全策略可能需要用户通过密码来验证他们自己。也就是在用户执行 sudo 命令时要求用户输入自己账号的密码。如果验证失败,sudo 命令将会退出。
命令语法
sudo [-bhHpV][-s ][-u <用户>][指令]
sudo [-klv]
参数:
-b在后台执行指令。-h显示帮助。-H将 HOME 环境变量设为新身份的 HOME 环境变量。-k结束密码的有效期限,也就是下次再执行 sudo 时便需要输入密码。-l列出目前用户可执行与无法执行的指令。-p改变询问密码的提示符号。-s执行指定的 shell。-u<用户> 以指定的用户作为新的身份。若不加上此参数,则预设以 root 作为新的身份。-v延长密码有效期限 5 分钟。-V显示版本信息。-S从标准输入流替代终端来获取密码
基本配置
系统默认创建了一个名为 sudo 的组。只要把用户加入这个组,用户就具有了 sudo 的权限。
至于如何把用户加入 sudo 组,您可以直接编辑 /etc/group 文件,当然您得使用一个有 sudo 权限的用户来干这件,在 sudo 组中加入新的用户,要使用逗号分隔多个用户。
或者您可以使用 usermod 命令把用户添加到一个组中:
sudo usermod -a -G sudo jack
上面的设置中我们把用户 jack 添加到了 sudo 组中,所以当用户 jack 登录后就可以通过 sudo 命令以 root 权限执行命令了!
详细配置
在前面的配置中我们只是把用户 jack 加入了 sudo 组,他就具有了通过 root 权限执行命令的能力。
现在我们想问一下,这是怎么发生的?是时候介绍如何配置 sudo 命令了!
sudo 命令的配置文件为 /etc/sudoers。
编辑这个文件是有单独的命令的 visudo,这个文件我们最好不要使用 vim 命令来打开,是因为一旦你的语法写错会造成严重的后果,这个工具会替你检查你写的语法,这个文件的语法遵循以下格式:
who where whom command
说白了就是哪个用户在哪个主机以谁的身份执行那些命令,那么这个 where, 是指允许在那台主机 ssh 连接进来才能执行后面的命令,文件里面默认给 root 用户定义了一条规则:
root ALL=(ALL:ALL) ALL
root表示 root 用户。ALL表示从任何的主机上都可以执行,也可以这样 192.168.100.0/24。(ALL:ALL)是以谁的身份来执行,ALL:ALL 就代表 root 可以任何人的身份来执行命令。ALL表示任何命令。
那么整条规则就是 root 用户可以在任何主机以任何人的身份来执行所有的命令。
现在我们可以回答 jack 为什么具有通过 root 权限执行命令的能力了。打开 /etc/sudoers 文件:
%sudo ALL=(ALL:ALL) ALL
sudo 组中的所有用户都具有通过 root 权限执行命令的能力!
再看个例子:
nick 192.168.10.0/24=(root) /usr/sbin/useradd
上面的配置只允许 nick 在 192.168.10.0/24 网段上连接主机并且以 root 权限执行 useradd 命令。
设置 sudo 时不需要输入密码
只需要在配置行中添加 NOPASSWD: 就可以了:
%sudo ALL=(ALL:ALL) NOPASSWD:ALL
日志
在 ubuntu 中,sudo 的日志默认被记录在 /var/log/auth.log 文件中。当我们执行 sudo 命令时,相关日志都是会被记录下来的。
与输出重定向
如果当前用户没有某个文件的写权限,又要通过输出重定向往该文件中写入内容。结果只能是 “Permission denied”。
比如当前用户为 nick,下面的命令试图查询 /root 目录下的文件并把结果写入到 /root/test.txt 文件中,注意用户 nick 没有对 /root/test.txt 文件的写权限:
$ sudo ls -al /root/test.txt
-rw-r--r-- 1 root root 0 Jan 10 05:19 /root/test.txt
$ sudo ls -al /root > /root/test.txt
-bash: /root/test.txt: Premission denied
不工作的原因是:虽然 ls 命令是以 sudo 方式执行的,但是输出重定向操作是由当前 shell 执行的,它(当前 shell)没有 /root/test.txt 文件的权限,所以最终失败。
搞清楚了原因,就可以通过不同的方式来解决这个问题了,下面介绍四种方式。
以 sudo 方式运行 shell
既然是 shell 进程没有权限,那就用 sudo 的方式执行 shell:
sudo bash -c 'ls -al /root > /root/test.txt'
把命令写入脚本,以 sudo 方式执行脚本
把下面的代码保存到脚本文件 test.sh 中:
#!/bin/bash
ls -al /root > /root/test.txt
然后通过下面的方式执行:
chmod +x test.sh
sudo ./test.sh
如果觉着创建脚本麻烦的话还可以使用变通的方式:
$ sudo bash <<EOF
> ls -al /root > /root/test.txt
> EOF
或者是下面的写法:
echo 'ls -al /root > /root/test.txt' | sudo bash
先通过 sudo -s 启动 shell,然后执行命令
先通过 sudo -s 命令切换到 root 用户再执行命令,最后 ctrl + d 退出。
通过 sudo tee 命令实现
Tee 命令用于将数据重定向到文件,另一方面还可以提供一份重定向数据的副本作为后续命令的 stdin。简单的说就是把数据重定向到给定文件和屏幕上:
面的命令中通过 sudo tee 把 ls 命令的输出写入文件:
sudo ls -al /root | sudo tee /root/test.txt > /dev/null
其中的 > /dev/null 阻止 tee 把内容输出到终端。
fdisk
Linux 系统中所有的硬件设备都是通过文件的方式来表现和使用的,我们将这些文件称为设备文件,硬盘对应的设备文件一般被称为块设备文件。
磁盘分类
比较常见的磁盘类型有消费类市场中的 SATA 硬盘和服务器中使用的 SCSI 硬盘、SAS 硬盘,当然还有当下大热的各种固态硬盘。
SATA 硬盘
SATA(Serial ATA)口的硬盘又叫串口硬盘,Serial ATA 采用串行连接方式,串行 ATA 总线使用嵌入式时钟信号,具备了更强的纠错能力,与以往相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。串行接口还具有结构简单、支持热插拔的优点。SATA 硬盘主要用于消费类市场和一些低端服务器:

SCSI 硬盘
SCSI 硬盘即采用 SCSI 接口的硬盘。它由于性能好、稳定性高,因此在服务器上得到广泛应用。同时其价格也不菲,正因它的价格昂贵,所以在普通 PC 上很少见到它的踪迹。SCSI 硬盘使用 50 针接口,外观和普通硬盘接口有些相似(下图来自互联网):

SAS 硬盘
SAS 是 Serial Attached SCSI 的缩写,即串行连接的 SCSI,其目标是定义一个新的串行点对点的企业级存储设备接口。串行接口减少了线缆的尺寸,允许更快的传输速度。SAS 硬盘与相同转速的 SCSI 硬盘相比有相同或者更好的性能。SAS 硬盘一般用于比较高端的服务器。
固态硬盘
固态硬盘(Solid State Disk),一般称之为 SSD 硬盘,固态硬盘是用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH 芯片、DRAM 芯片)组成。其主要特点是没有传统硬盘的机械结构,读写速度非常快(下图来自互联网):

表示方法
在 Linux 系统中磁盘设备文件的命名规则为:
主设备号 + 次设备号 + 磁盘分区号
对于目前常见的磁盘,一般表示为:
sd[a-z]x
- 主设备号代表设备的类型,相同的主设备号表示同类型的设备。当前常见磁盘的主设备号为 sd。
- 次设备号代表同类设备中的序号,用 “a-z” 表示。比如 /dev/sda 表示第一块磁盘,/dev/sdb 表示第二块磁盘。
- x 表示磁盘分区编号。在每块磁盘上可能会划分多个分区,针对每个分区,Linux 用 /dev/sdbx 表示,这里的 x 表示第二块磁盘的第 x 个分区。
磁盘分区
创建磁盘分区大概有下面几个目的:
- 提升数据的安全性(一个分区的数据损坏不会影响其他分区的数据)
- 支持安装多个操作系统
- 多个小分区对比一个大分区会有性能提升
- 更好的组织数据
本文以常见的 MBR 分区为例介绍磁盘分区中的一些常见概念。MBR 磁盘的分区由主分区、扩展分区和逻辑分区组成。在一块磁盘上,主分区的最大个数是 4,其中扩展分区也是一个主分区,并且最多只能有一个扩展分区,但可以在扩展分区上创建多个逻辑分区。因此主分区(包括扩展分区)的范围是 1-4,逻辑分区从 5 开始。对于逻辑分区,Linux 规定它们必须建立在扩展分区上,而不是建立在主分区上。
主分区的作用是用来启动操作系统的,主要存放操作系统的启动或引导程序。
扩展分区只不过是逻辑分区的 “容器”。实际上只有主分区和逻辑分区是用来进行数据存储的,因而可以将数据集中存放在磁盘的逻辑分区中。
我们可以通过 fdisk 命令来查看磁盘分区的信息:
sudo fdisk -l /dev/sda
分区信息:
- Device 显示了磁盘分区对应的设备文件名。
- Boot 显示是否为引导分区,是引导分区就有一个 ‘*’ 号。
- Start 表示磁盘分区的起始位置。
- End 表示磁盘分区的结束位置。
- Sectors 表示分区占用的扇区数目。
- Size 显示分区的大小。
- Id/Type 显示的内容相同,分别是数值 ID 及其文字描述。 Id 列显示了磁盘分区对应的 ID,根据分区的不同,分区对应的 ID 号也不相同。Linux 下用 83 表示主分区和逻辑分区,5 表示扩展分区,8e 表示 LVM 分区,82 表示交换分区,7 表示 NTFS 分区。
划分磁盘分区
fdisk 是 Linux 系统中一款功能强大的磁盘分区管理工具,可以观察硬盘的使用情况,也可以用来管理磁盘分区。
假设我们的 Linux 系统中增加了一块新的磁盘,系统对应的设备名为 /dev/sdd,下面我们通过 fdisk 命令对这个磁盘进行分区:
(echo n; echo p; echo 1; echo ; echo ; echo w) | sudo fdisk /dev/sdd
- 命令 n 来创建新分区
- p 来创建主分区
- 主分区的编号为 1- 4,这里我们输入了 1。
- 分区的大小是通过设置分区开始处的扇区和结束处的扇区设置的。这里如果回车两次会把整个磁盘划分为一个分区,也就是整个磁盘的容器都分给了一个分区。
- 注意此时的分区信息还没有写入到磁盘中,在这里还可以反悔,如果确认执行上面的分区,执行 w 命令就行了。
这时分区操作已经完成了,我们可以通过下面的命令查看分区的结果:
sudo fdisk -l /dev/sdd
分区是使用磁盘的基础,在分区完成后还需要对分区进行格式化,并把格式化后的文件系统挂载到 Linux 系统之后才能存储文件。
更改分区的类型
创建的分区类型默认为 83(Linux),如果想要一个 8e(Linux LVM)类型的分区,在 fdisk 输入 t 命令来修改分区的类型。
fuser
当使用 umount 命令卸载挂载点时,会遇到“device is busy”提示,这时 fuser 就能查出谁在使用这个资源。
描述
fuser 可以显示出当前哪个程序在使用磁盘上的某个文件、挂载点、甚至网络端口,并给出程序进程的详细信息。
每个进程 ID 后面跟有一个字母代码。字母代码的解释如下所述。
c:表示此进程正在使用该文件作为其当前目录。e:将此文件作为程序的可执行对象使用f:打开的文件。默认不显示。F:打开的文件,用于写操作。默认不显示。r:表示此进程正在将该文件用作其根目录。m:指示进程使用该文件进行内存映射,抑或该文件为共享库文件,被进程映射进内存。s:将此文件作为共享库(或其他可装载对象)使用
对于具有已挂载文件系统的块特殊设备,将列出使用该设备上的任何文件的所有进程。对于所有类型的文件(文本文件、可执行文件、目录、设备,等等),只会报告使用该文件的进程。
对于所有类型的设备,fuser 还会显示打开设备的任何已知内核使用者。内核使用者显示为下列格式之一:
[module_name]
[module_name,dev_path=path]
[module_name,dev=(major,minor)]
[module_name,dev=(major,minor),dev_path=path]
如果指定了多组文件,可能需要为其他每个文件组重新指定选项。单个短划线可取消当前施行的选项。
各个进程 ID 输出到标准输出中的单个行上,并以空格分隔。所有其他输出(包括单个终止换行符)均被写入到标准错误。
任何用户都可以运行 fuser,但只有超级用户可以终止其他用户的进程。
选项
支持以下选项:
-a:显示所有命令行中指定的文件,默认情况下被访问的文件才会被显示。-c:和-m 一样,用于 POSIX 兼容。-k:杀掉访问文件的进程。如果没有指定-signal 就会发送 SIGKILL 信号。-i:杀掉进程之前询问用户,如果没有-k 这个选项会被忽略。-l:列出所有已知的信号名称。-m:name 指定一个挂载文件系统上的文件或者被挂载的块设备(名称 name)。这样所有访问这个文件或者文件系统的进程都会被列出来。如果指定的是一个目录会自动转换成"name/",并使用所有挂载在那个目录下面的文件系统。-n:space 指定一个不同的命名空间(space).这里支持不同的空间文件(文件名,此处默认)、tcp(本地 tcp 端口)、udp(本地 udp 端口)。对于端口, 可以指定端口号或者名称,如果不会引起歧义那么可以使用简单表示的形式,例如:name/space (即形如:80/tcp 之类的表示)。-s:静默模式,这时候-u,-v 会被忽略。-a 不能和-s 一起使用。-signal:使用指定的信号,而不是用 SIGKILL 来杀掉进程。可以通过名称或者号码来表示信号(例如-HUP,-1),这个选项要和-k 一起使用,否则会被忽略。-u:在每个 PID 后面添加进程拥有者的用户名称。-v:详细模式。输出似 ps 命令的输出,包含 PID,USER,COMMAND 等许多域,如果是内核访问的那么 PID 为 kernel. -V 输出版本号。-4:使用 IPV4 套接字,不能和-6 一起应用,只在-n 的 tcp 和 udp 的命名存在时不被忽略。-6:使用 IPV6 套接字,不能和-4 一起应用,只在-n 的 tcp 和 udp 的命名存在时不被忽略。-:重置所有的选项,把信号设置为 SIGKILL.
示例
示例 1 显示使用某个文件的进程信息
这个命令在 umount 的时候很有用,可以找到还有哪些用到这个设备了。
$ fuser -um /dev/sda2
/dev/sda2: 6378c(quietheart) 6534c(quietheart) 6628(quietheart)
6653c(quietheart) 7429c(quietheart) 7549c(quietheart) 7608c(quietheart)
示例 2 杀掉打开 readme 文件的程序
这里,会在 kill 之前询问是否确定。最好加上-v 以便知道将要杀那个进程。
fuser -m -k -i readme
示例 3 查看那些程序使用 tcp 的 80 端口
$ fuser -v -n tcp 80
# or
$ fuser -v 80/tcp
tcpdump
tcpdump 是一款 Linux 平台的抓包工具。它可以抓取涵盖整个 TCP/IP 协议族的数据包,支持针对网络层、协议、主机、端口的过滤,并提供 and、or、not 等逻辑语句来过滤无用的信息。
tcpdump 是一个非常复杂的工具,掌握它的方方面面实属不易,也不推荐,能够用它来解决日常工作问题才是关系。
命令选项
tcpdump 有很多命令选项,想了解所有选项可以 Linux 命令行输入 tcpdump -h,man tcpdump 查看每个选项的意思。
下面列举一些常用选项:
- -A 只使用 ASCII 打印报文的全部数据,不要和
-X一起使用,获取 http 可以用tcpdump -nSA port 80 - -b 在数据链路层上选择协议,包括 ip, arp, rarp, ipx 等
- -c 指定要抓取包的数量
- -D 列出操作系统所有可以用于抓包的接口
- -e 输出链路层报头
- -i 指定监听的网卡,
-i any显示所有网卡 - -n 表示不解析主机名,直接用 IP 显示,默认是用 hostname 显示
- -nn 表示不解析主机名和端口,直接用端口号显示,默认显示是端口号对应的服务名
- -p 关闭接口的混杂模式
- -P 指定抓取的包是流入的包还是流出的,可以指定参数 in, out, inout 等,默认是 inout
- -q 快速打印输出,即只输出少量的协议相关信息
- -s len 设置要抓取数据包长度为 len,默认只会截取前 96bytes 的内容,
-s 0的话,会截取全部内容。 - -S 将 TCP 的序列号以绝对值形式输出,而不是相对值
- -t 不要打印时间戳
- -vv 输出详细信息(比如 tos、ttl、checksum 等)
- -X 同时用 hex 和 ascii 显示报文内容
- -XX 同 -X,但同时显示以太网头部
过滤器
网络报文是很多的,很多时候我们在主机上抓包,会抓到很多我们并不关心的无用包,然后要从这些包里面去找我们需要的信息,无疑是一件费时费力的事情,tcpdump 提供了灵活的语法可以精确获取我们关心的数据,这些语法说得专业点就是过滤器。
过滤器简单可分为三类:协议(proto)、传输方向(dir)和类型(type)。
一般的 表达式格式 为:

- 关于 proto:可选有 ip, arp, rarp, tcp, udp, icmp, ether 等,默认是所有协议的包
- 关于 dir:可选有 src, dst, src or dst, src and dst,默认为 src or dst
- 关于 type:可选有 host, net, port, portrange(端口范围,比如 21-42),默认为 host
常用操作
测试环境 IP:172.18.82.173
抓取某主机的数据包
抓取主机 172.18.82.173 上所有收到(DST_IP)和发出(SRC_IP)的所有数据包
tcpdump host 172.18.82.173
抓取经过指定网口 interface ,并且 DST_IP 或 SRC_IP 是 172.18.82.173 的数据包
tcpdump -i eth0 host 172.18.82.173
筛选 SRC_IP,抓取经过 interface 且从 172.18.82.173 发出的包
tcpdump -i eth0 src host 172.18.82.173
筛选 DST_IP,抓取经过 interface 且发送到 172.18.82.173 的包
tcpdump -i eth0 dst host 172.18.82.173
抓取主机 200.200.200.1 和主机 200.200.200.2 或 200.200.200.3 通信的包
tcpdump host 200.200.200.1 and \(200.200.200.2 or 200.200.200.3\)
抓取主机 200.200.200.1 和除了主机 200.200.200.2 之外所有主机通信的包
tcpdump ip host 200.200.200.1 and ! 200.200.200.2
抓取某端口的数据包
抓取所有端口,显示 IP 地址
tcpdump -nS
抓取某端口上的包
tcpdump port 22
抓取经过指定 interface,并且 DST_PORT 或 SRC_PORT 是 22 的数据包
tcpdump -i eth0 port 22
筛选 SRC_PORT
tcpdump -i eth0 src port 22
筛选 DST_PORT
tcpdump -i eth0 dst port 22
比如希望查看发送到 host 172.18.82.173 的网口 eth0 的 22 号端口的包
tcpdump -i eth0 -nnt dst host 172.18.82.173 and port 22 -c 1 -vv
抓取某网络(网段)的数据包
抓取经过指定 interface,并且 DST_NET 或 SRC_NET 是 172.18.82 的包
tcpdump -i eth0 net 172.18.82
筛选 SRC_NET
tcpdump -i eth0 src net 172.18.82
筛选 DST_NET
tcpdump -i eth0 dst net 172.18.82
抓取某协议的数据包
tcpdump -i eth0 icmp
tcpdump -i eth0 ip
tcpdump -i eth0 tcp
tcpdump -i eth0 udp
tcpdump -i eth0 arp
复杂的过滤条件
抓取经过 interface eth0 发送到 host 200.200.200.1 或 200.200.200.2 的 TCP 协议 22 号端口的数据包
tcpdump -i eth0 -nntvv -c 10 '((tcp) and (port 22) and ((dst host 200.200.200.1) or (dst host 200.200.200.2)))'
对于复杂的过滤器表达式,为了逻辑清晰,可以使用 (),不过默认情况下,tcpdump 会将 () 当做特殊字符,所以必须使用 '' 来消除歧义。
抓取经过 interface eth0, DST_MAC 或 SRC_MAC 地址是 00:16:3e:12:16:e7 的 ICMP 数据包
tcpdump -i eth0 '((icmp) and ((ether host 00:16:3e:12:16:e7)))' -nnvv
抓取经过 interface eth0,目标网络是 172.18 但目标主机又不是 172.18.82.173 的 TCP 且非 22 号端口号的数据包
tcpdump -i eth0 -nntvv '((dst net 172.18) and (not dst host 172.18.82.173) and (tcp) and (not port 22))'
抓取流入 interface eth0,host 为 172.18.82.173 且协议为 ICMP 的数据包
tcpdump -i eth0 -nntvv -P in host 172.18.82.173 and icmp
抓取流出 interface eth0,host 为 172.18.82.173 且协议为 ICMP 的数据包
tcpdump -i eth0 -nntvv -P out host 172.18.82.173 and icmp
与其他工具的配合
tcpdump 抓包的时候,默认是打印到屏幕输出,如果是抓取包少还好,如果包很多,很多行数据,刷刷刷从眼前一闪而过,根本来不及看清内容。不过,tcpdump 提供了将抓取的数据保存到文件的功能,查看文件就方便分析多了,而且还能与其他图形工具一起配合分析,比如 wireshark、Snort 等。
- -w 选项表示把数据报文输出到文件
tcpdump -w capture_file.pcap port 80
- -r 选项表示读取文件里的数据报文,显示到屏幕上
tcpdump -nXr capture_file.pcap host host1
.pcap 格式的文件需要用 wireshark、Snort 等工具查看,使用 vim 或 cat 会出现乱码。
tcpdump 的输出格式
tcpdump 的输出格式总体上为:
系统时间 源主机.端口 > 目标主机.端口 数据包参数
比如下面的例子,显示了 TCP 的三次握手过程:
21:27:06.995846 IP (tos 0x0, ttl 64, id 45646, offset 0, flags [DF], proto TCP (6), length 64)
192.168.1.106.56166 > 124.192.132.54.80: Flags [S], cksum 0xa730 (correct), seq 992042666, win 65535, options [mss 1460,nop,wscale 4,nop,nop,TS val 663433143 ecr 0,sackOK,eol], length 0
21:27:07.030487 IP (tos 0x0, ttl 51, id 0, offset 0, flags [DF], proto TCP (6), length 44)
124.192.132.54.80 > 192.168.1.106.56166: Flags [S.], cksum 0xedc0 (correct), seq 2147006684, ack 992042667, win 14600, options [mss 1440], length 0
21:27:07.030527 IP (tos 0x0, ttl 64, id 59119, offset 0, flags [DF], proto TCP (6), length 40)
192.168.1.106.56166 > 124.192.132.54.80: Flags [.], cksum 0x3e72 (correct), ack 2147006685, win 65535, length 0
第一条是 SYN 报文,通过 Flags[S] 看出。第二条是 [S.],表示 SYN-ACK 报文。常见的 TCP 报文的 Flags 如下:
[S]: SYN(开始连接)[.]: 没有 Flag[P]: PSH(推送数据)[F]: FIN (结束连接)[R]: RST(重置连接)
GPG
前两篇文章,我介绍了RSA 算法。
今天,就接着来看,现实中怎么使用这个算法,对信息加密和解密。这要用到GnuPG软件(简称 GPG),它是目前最流行、最好用的加密工具之一。
什么是 GPG
要了解什么是 GPG,就要先了解PGP。
1991 年,程序员Phil Zimmermann为了避开政府监视,开发了加密软件 PGP。这个软件非常好用,迅速流传开来,成了许多程序员的必备工具。但是,它是商业软件,不能自由使用。所以,自由软件基金会决定,开发一个 PGP 的替代品,取名为 GnuPG。这就是 GPG 的由来。
GnuPG 是完整实现了 RFC4880 (即 PGP) 所定义的 OpenPGP 标准的自由软件。
GnuPG 可以加密和签名你的数据和通讯信息,包含一个通用的密钥管理系统以及用于各种公钥目录的访问模块。
GnuPG 是一个易于与其它程序整合的命令行工具,拥有很多前端程序和函数库。
GnuPG 还支持 S/MIME 和 Secure Shell (ssh)。
GPG 有许多用途,本文主要介绍文件加密。至于邮件的加密,不同的邮件客户端有不同的设置,请参考 Ubuntu 网站的介绍。
本文的使用环境为 Linux 命令行。如果掌握了命令行,Windows 或 Mac OS 客户端,就非常容易掌握。GPG 并不难学,学会了它,从此就能轻松传递加密信息。建议读者一步步跟着教程做,对每条命令都自行测试。
安装
GPG 有两种安装方式。可以下载源码,自己编译安装。
./configure
make
make install
也可以安装编译好的二进制包。
sudo apt-get install gnupg
安装完成后,键入下面的命令:
gpg --help
如果屏幕显示 GPG 的帮助,就表示安装成功。
配置
目录位置
GnuPG 用环境变量 $GNUPGHOME 定位配置文件的位置,默认情况下此变量并未被设置,会直接使用 $HOME,所以默认的配置目录是 ~/.gnupg。
要改变默认位置,执行 $ gpg --homedir path/to/file 或在 startup files 中设置 GNUPGHOME。
配置文件
默认的配置文件是 ~/.gnupg/gpg.conf 和 ~/.gnupg/dirmngr.conf.
gnupg 目录的默认 权限 是 700,其中文件的权限是 600. 仅目录的所有者有权读写,访问这些文件。这是基于安全考虑,请不要变更。如果不使用这样的安全权限设置,会收到不安全文件的警告。
在文件中附加需要的文件:/usr/share/gnupg 包含基本架构文件. gpg,第一次运行时,如果配置文件不存在,会自动复制文件到 ~/.gnupg。
新用户的默认选项
要给新建用户设定一些默认选项,把配置文件放到 /etc/skel/.gnupg/。系统创建新用户时,就会把文件复制到 GnuPG 目录。还有一个 addgnupghome 命令可以为已有用户创建新 GnuPG 主目录:
# addgnupghome user1 user2
此命令会将对检查 /home/user1/.gnupg 和 /home/user2/.gnupg,如果用户的 GnuPG 主目录不存在,就会从 skeleton 目录复制文件过去。
生成密钥
安装成功后,使用 --full-generate-key 参数生成自己的密钥。
gpg --full-generate-key
或用 gpg --gen-key 快速生成。以下使用 gpg2 --full-generate-key 演示。
回车以后,会跳出一大段文字:
gpg (GnuPG) 2.2.19; Copyright (C) 2019 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
(14) Existing key from card
Your selection?
第一段是版权声明,然后让用户自己选择加密算法。默认选择第一个选项,表示加密和签名都使用 RSA 算法。
然后,系统就会问你密钥的长度。
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (3072)
密钥越长越安全。
接着,设定密钥的有效期。
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0)
如果密钥只是个人使用,并且你很确定可以有效保管私钥,建议选择第一个选项,即永不过期。回答完上面三个问题以后,系统让你确认。
Is this correct? (y/N)
输入 y,系统就要求你提供个人信息。
GnuPG needs to construct a user ID to identify your key.
Real name:
Email address
Comment:
“真实姓名"填入你姓名的英文写法,“电子邮件地址"填入你的邮件地址,“注释"这一栏可以空着。
然后,你的"用户 ID"生成了。
You selected this USER-ID:
"Vane Hsiung <1664548605@qq.com>"
系统会让你最后确认一次。
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit?
输入 O 表示"确定”。
接着,系统会要求你做一些随机的举动,以生成一个随机数。同时系统会让你设定一个私钥的密码。这是为了防止误操作,或者系统被侵入时有人擅自动用私钥。
We need to generate a lot of random bytes. It is a good idea to performsome other action (type on the keyboard, move the mouse, utilize thedisks) during the prime generation; this gives the random numbergenerator a better chance to gain enough entropy.
然后,系统就开始生成密钥了,
几分钟以后,系统提示密钥已经生成了。
gpg: key B893B73ABC92D2CA marked as ultimately trusted
gpg: revocation certificate stored as ''public and secret key created and signed.
请注意上面的字符串"B893B73ABC92D2CA”,这是"用户 ID"的 Hash 字符串,可以用来替代"用户 ID”。
这时,最好再生成一张"撤销证书",以备以后密钥作废时,可以请求外部的公钥服务器撤销你的公钥。
gpg --gen-revoke [用户ID]
上面的"用户 ID"部分,可以填入你的邮件地址或者 Hash 字符串(以下同)。
密钥管理
列出密钥
list-keys 参数列出系统中已有的密钥.
gpg --list-keys
显示结果如下:
gpg: checking the trustdb
gpg: marginals needed: 3 completes needed: 1 trust model: pgp
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
/home/vane/.gnupg/pubring.kbx
-----------------------------
pub rsa3072 2021-10-17 [SC]
BC158F7500033355B5324CF14C701F8BF2E03463
uid [ultimate] Vane Hsiung <1664548605@qq.com>
sub rsa3072 2021-10-17 [E]
第一行显示公钥文件名(pubring.gpg),第二行显示公钥特征(4096 位,Hash 字符串和生成时间),第三行显示"用户 ID",第四行显示私钥特征。
如果你要从密钥列表中删除某个密钥,可以使用如下参数。
gpg --delete-secret-keys [用户ID]
gpg --delete-key [用户ID]
输出密钥
公钥文件(.gnupg/pubring.gpg)以二进制形式储存,armor 参数可以将其转换为 ASCII 码显示。
gpg --armor --output public-key.txt --export [用户ID]
“用户 ID"指定哪个用户的公钥,output 参数指定输出文件名(public-key.txt)。
类似地,export-secret-keys 参数可以转换私钥。
gpg --armor --output private-key.txt --export-secret-keys
上传公钥
公钥服务器是网络上专门储存用户公钥的服务器。send-keys 参数可以将公钥上传到服务器。
gpg --send-keys [用户ID] --keyserver hkp://subkeys.pgp.net
使用上面的命令,你的公钥就被传到了服务器 subkeys.pgp.net,然后通过交换机制,所有的公钥服务器最终都会包含你的公钥。
由于公钥服务器没有检查机制,任何人都可以用你的名义上传公钥,所以没有办法保证服务器上的公钥的可靠性。通常,你可以在网站上公布一个公钥指纹,让其他人核对下载到的公钥是否为真。fingerprint 参数生成公钥指纹。
gpg --fingerprint [用户ID]
输入密钥
除了生成自己的密钥,还需要将他人的公钥或者你的其他密钥输入系统。这时可以使用 import 参数。
gpg --import [密钥文件]
为了获得他人的公钥,可以让对方直接发给你,或者到公钥服务器上寻找。
gpg --keyserver hkp://subkeys.pgp.net --search-keys [用户ID]
正如前面提到的,我们无法保证服务器上的公钥是否可靠,下载后还需要用其他机制验证.
加密和解密
加密
假定有一个文本文件 demo.txt,怎样对它加密呢?
encrypt 参数用于加密。
gpg --recipient [用户ID] --output demo.en.txt --encrypt demo.txt
recipient 参数指定接收者的公钥,output 参数指定加密后的文件名,encrypt 参数指定源文件。运行上面的命令后,demo.en.txt 就是已加密的文件,可以把它发给对方。
解密
对方收到加密文件以后,就用自己的私钥解密。
gpg --output demo.de.txt --decrypt demo.en.txt
output 指定解密后生成的文件,decrypt 参数指定需要解密的文件。运行上面的命令,demo.de.txt 就是解密后的文件。
GPG 允许省略 decrypt 参数。
gpg demo.en.txt
签名
对文件签名
有时,我们不需要加密文件,只需要对文件签名,表示这个文件确实是我本人发出的。sign 参数用来签名。
gpg --sign demo.txt
运行上面的命令后,当前目录下生成 demo.txt.gpg 文件,这就是签名后的文件。这个文件默认采用二进制储存,如果想生成 ASCII 码的签名文件,可以使用 clearsign 参数。
gpg --clearsign demo.txt
运行上面的命令后 ,当前目录下生成 demo.txt.asc 文件,后缀名 asc 表示该文件是 ASCII 码形式的。
如果想生成单独的签名文件,与文件内容分开存放,可以使用 detach-sign 参数。
gpg --detach-sign demo.txt
运行上面的命令后,当前目录下生成一个单独的签名文件 demo.txt.sig。该文件是二进制形式的,如果想采用 ASCII 码形式,要加上 armor 参数。
gpg --armor --detach-sign demo.txt
签名+加密
上一节的参数,都是只签名不加密。如果想同时签名和加密,可以使用下面的命令。
gpg --local-user [发信者ID] --recipient [接收者ID] --armor --sign --encrypt demo.txt
local-user 参数指定用发信者的私钥签名,recipient 参数指定用接收者的公钥加密,armor 参数表示采用 ASCII 码形式显示,sign 参数表示需要签名,encrypt 参数表示指定源文件。
验证签名
我们收到别人签名后的文件,需要用对方的公钥验证签名是否为真。verify 参数用来验证。
gpg --verify demo.txt.asc demo.txt
举例来说,openvpn网站就提供每一个下载包的 gpg 签名文件。你可以根据它的说明,验证这些下载包是否为真。
Others
Ubuntu Packages Search
List of applications:Arch
Recommended applications: Gentoo
常用软件:openSUSE
Awesome-Linux-Software
应用下载-优麒麟
国内应用 wine 版 deb 包。
AUR
抄安装脚本。
Gentoo Portage Overlays
抄安装脚本。
铜豌豆软件生态
- 铜豌豆 Linux 收集整理制作了大量中国人常用的应用软件,丰富 Linux 桌面系统软件生态。
- 大家可以在添加铜豌豆软件源后,来安装使用这些软件包。
- 铜豌豆软件源不但支持 铜豌豆 Linux 系统,还支持 Debian 系的所有 Linux 发行版。Debian、Armbian、Ubuntu、深度、优麒麟、红旗等。