
[fəˈdɔrə] 费多拉
Fedora Linux 版本
Fedora 官方版本
- Fedora 工作站是可以安装在笔记本电脑和台式电脑上的 Linux。 此版本附带 GNOME 作为默认桌面环境和各种标准应用程序,以便 Fedora Linux 已准备好用于日常使用。
- Fedora 服务器专门用于服务器计算机用途,提供邮件服务器、DNS 等的安装。
- Fedora 物联网,用于物联网和设备边缘生态系统。
- Fedora CoreOS 是一种自动更新的操作系统,旨在安全、大规模地运行容器化工作负载。
- Fedora Silverblue 是一个不可变的桌面操作系统,旨在支持以容器为中心的工作流。
Fedora Spins
Fedora 的默认桌面环境是 GNOME,但是如果您喜欢其他的桌面环境,比如 KDE Plasma Desktop 或 Xfce,您可以下载一个您喜欢的桌面环境的 spin,然后用它来安装 Fedora,为您选择的桌面环境进行预配置。
Fedora Labs
Fedora 实验室是一个由 Fedora 社区成员策划和维护的目的明确的软件和内容的精选捆绑包。这些软件可以作为独立的Fedora完整版安装,也可以作为现有的Fedora安装的附加组件安装。
Fedora Alternative Downloads
这些Fedora下载要么是特殊用途的——用于测试,用于特定的架构;要么是其他格式的Fedora标准版本,如网络安装程序格式或用于torrent下载的格式。
本页旨在作为查找Fedora替代版本的单一中央资源。
Fedora Usage
Mirrors Of Fedora
SJTU Mirror
托管于华东教育网骨干节点上海交通大学。
$ sudo sed -e 's/^metalink=/#metalink=/g' -e 's|^#baseurl=http://download.example/pub/|baseurl=https://mirror.sjtu.edu.cn/|g' -i.bak /etc/yum.repos.d/{fedora,fedora-updates,fedora-modular,fedora-updates-modular}.repo
$ sudo dnf makecache #生成缓存
RPMFusion
第一步下载基础包(开源和闭源), 这里我们使用bfsu来下载,以避免网络问题,终端输入:
$ sudo dnf install --nogpgcheck https://mirror.sjtu.edu.cn/rpmfusion/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm https://mirror.sjtu.edu.cn/rpmfusion/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm -y
第二步,使用SJTU Mirror
sudo sed -e 's|^metalink=|#metalink=|g' -e 's|^#baseurl=http://download1.rpmfusion.org/|baseurl=https://mirror.sjtu.edu.cn/rpmfusion/|g' -i.bak /etc/yum.repos.d/rpmfusion-*
FlatHub Mirror
改为使用 sjtu 镜像:
$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
$ sudo flatpak remote-modify --enable flathub
$ sudo flatpak remote-modify flathub --url=https://mirror.sjtu.edu.cn/flathub
$ sudo flatpak remotes --show-details
$ cat /var/lib/flatpak/repo/config
Copr
类似 Ubuntu 的 PPA
-
You need to have
dnf-plugins-coreinstalled for dnf, and you need to haveyum-plugin-coprinstalled for yum$ sudo dnf install dnf-plugins-core $ sudo yum install yum-plugin-copr -
If you’re using a version of Linux with dnf, or if you have older distribution:
$ sudo dnf copr enable user/project $ sudo yum copr enable user/project
例如Fedora自带的Copr repo for PyCharm
$ cat /etc/yum.repos.d/_copr_phracek-PyCharm.repo
[phracek-PyCharm]
name=Copr repo for PyCharm owned by phracek
baseurl=https://copr-be.cloud.fedoraproject.org/results/phracek/PyCharm/fedora-$releasever-$basearch/
skip_if_unavailable=True
gpgcheck=1
gpgkey=https://copr-be.cloud.fedoraproject.org/results/phracek/PyCharm/pubkey.gpg
enabled=0
Speed Up DNF
尝试更改参数:
$ sudo vi /etc/dnf/dnf.conf
fastestmirror=true #如果启用国内镜像,就不需要设置这个了。
max_parallel_downloads=5
metadata_expire=2d
- fastermirror 选择最快的镜像
- max_parallel_downloads 一次下载多个包
Gnome
$ sudo dnf install gnome-tweaks gnome-extensions-app
- gnome-tweaks 里面可以管理 startup apps。
- gnome-extensions-app 管理 extensions。
- gnome-shell-extension-appindicator
- gnome-shell-extension-gsconnect
Multiple Git Accounts
$ ssh-keygen -t rsa -C "your-email"
$ nano ~/.ssh/config
Host github-proj1
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_github_proj1
Host github-proj2
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_github_proj2
Host aws-codecommit-proj3
Hostname git-codecommit.us-east-2.amazonaws.com
User TECADMIN0123456789
IdentityFile ~/.ssh/id_rsa_aws_codecommit_proj3
AddKeysToAgent yes
$ git clone ssh://github-proj1/user1/repo.git
$ git clone ssh://github-proj2/user2/repo.git
$ git clone ssh://aws-codecommit-proj3/v1/repos/myrepo
设置 config 后,可能需要重启才能起作用。
Fcitx5
$ sudo dnf install fcitx5 fcitx5-chinese-addons fcitx5-gtk fcitx5-qt fcitx5-configtool fcitx5-autostart fcitx5-rime
$ rpm -ql fcitx5-autostart
/etc/profile.d/fcitx5.sh
/etc/xdg/autostart/org.fcitx.Fcitx5.desktop
$ cat /etc/profile.d/fcitx5.sh
if [ ! "$XDG_SESSION_TYPE" = "tty" ] # if this is a gui session (not tty)
then
# let's use fcitx instead of fcitx5 to make flatpak happy
# this may break behavior for users who have installed both
# fcitx and fcitx5, let then change the file on their own
export INPUT_METHOD=fcitx
export GTK_IM_MODULE=fcitx
export QT_IM_MODULE=fcitx
export XMODIFIERS=@im=fcitx
fi
$ cat /etc/xdg/autostart/org.fcitx.Fcitx5.desktop
[Desktop Entry]
Name[ca]=Fcitx 5
Name[da]=Fcitx 5
Name[de]=Fcitx 5
Name[ja]=Fcitx 5
Name[ko]=Fcitx 5
Name[zh_CN]=Fcitx 5
Name[zh_TW]=Fcitx 5
Name=Fcitx 5
GenericName[ca]=Mètode d'entrada
GenericName[da]=Inputmetode
GenericName[de]=Eingabemethode
GenericName[ja]=入力メソッド
GenericName[ko]=입력기
GenericName[ru]=Метод ввода
GenericName[zh_CN]=输入法
GenericName[zh_TW]=輸入法
GenericName=Input Method
Comment[ca]=Mètode d'entrada estàndard
Comment[da]=Start inputmetode
Comment[de]=Eingabemethode starten
Comment[ja]=入力メソッドを開始
Comment[ko]=입력기 시작
Comment[zh_CN]=启动输入法
Comment=Start Input Method
Exec=/usr/bin/fcitx5
Icon=fcitx
Terminal=false
Type=Application
Categories=System;Utility;
StartupNotify=false
X-GNOME-AutoRestart=false
X-GNOME-Autostart-Notify=false
X-KDE-autostart-after=panel
X-KDE-StartupNotify=false
X-KDE-Wayland-VirtualKeyboard=true
在 fcitx5 Configure 中,Input Method 只保留 rime,按组合键 Ctrl+` 选择 ”朙月拼音-简化字“,对应定制文件为 luna_pinyin_simp.custom.yaml。
Nvidia
-
Update from the existing repositories
$ sudo dnf update -
Add the RPMFusion repository for NVIDIA drivers
$ sudo dnf install fedora-workstation-repositories -
Update from the newly added repositories
$ sudo dnf update --refresh -
Install the driver and its dependencies
$ sudo dnf install gcc kernel-headers kernel-devel akmod-nvidia xorg-x11-drv-nvidia xorg-x11-drv-nvidia-libs xorg-x11-drv-nvidia-libs.i686 -
Wait for the kernel modules to load up
-
Read from the updated kernel modules
$ sudo akmods --force $ sudo dracut --force -
Reboot your system.
在这里,确定在登录界面选择的是 Gnome on Xorg。
-
Edit the X11 configuration
$ sudo cp -p /usr/share/X11/xorg.conf.d/nvidia.conf /etc/X11/xorg.conf.d/nvidia.conf $ sudo nano /etc/X11/xorg.conf.d/nvidia.conf Section "OutputClass" Identifier "nvidia" MatchDriver "nvidia-drm" Driver "nvidia" Option "AllowEmptyInitialConfiguration" Option "SLI" "Auto" Option "BaseMosaic" "on" Option "PrimaryGPU" "yes" EndSection Section "ServerLayout" Identifier "layout" Option "AllowNVIDIAGPUScreens" EndSection -
Reboot your system
-
Verify the configuration
$ glxinfo | egrep "OpenGL vendor|OpenGL renderer"
Movies and music
In order to install OpenH264, you first need to enable it:
$ cat /etc/yum.repos.d/fedora-cisco-openh264.repo
[fedora-cisco-openh264]
name=Fedora $releasever openh264 (From Cisco) - $basearch
metalink=https://mirrors.fedoraproject.org/metalink?repo=fedora-cisco-openh264-$releasever&arch=$basearch
type=rpm
enabled=0
metadata_expire=14d
repo_gpgcheck=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-$releasever-$basearch
skip_if_unavailable=True
[fedora-cisco-openh264-debuginfo]
name=Fedora $releasever openh264 (From Cisco) - $basearch - Debug
metalink=https://mirrors.fedoraproject.org/metalink?repo=fedora-cisco-openh264-debug-$releasever&arch=$basearch
type=rpm
enabled=0
metadata_expire=14d
repo_gpgcheck=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-fedora-$releasever-$basearch
skip_if_unavailable=True
$ sudo dnf config-manager --set-enabled fedora-cisco-openh264
Use the dnf utility to install packages that provide multimedia libraries:
$ sudo proxychains dnf install gstreamer1-plugins-{bad-\*,good-\*,base} gstreamer1-plugin-openh264 gstreamer1-libav --exclude=gstreamer1-plugins-bad-free-devel -y
$ sudo proxychains dnf install lame\* --exclude=lame-devel -y
$ sudo proxychains dnf group upgrade --with-optional Multimedia -y
$ sudo dnf config-manager --set-disabled fedora-cisco-openh264
and then install the plugins (for firefox, if needed):
$ sudo dnf install mozilla-openh264
Afterwards you need open Firefox, go to menu → Add-ons → Plugins and enable OpenH264 plugin.
Rhythmbox
无法订阅喜马拉雅的feed,报错为:
Unable to load the feed. Check your network connection
其实试一下荔枝FM,会发现是可以订阅的。比较一下就会发现,荔枝FM的Feed都是mp3链接,而喜马拉雅的Feed都是m4a链接,下载必须解码器后( The .m4a files are alac which would be decoded by gstreamer1.0-libav. ),Rhythmbox 确实能播放m4a文件了,但依然无法订阅,因此应该是Prodcast解析feed链接的问题,有兴趣有能力有时间看:Rhythmbox Development Reference Manual(PS:Ubuntu 22.04.1 上并无此问题)
Podman
kali linux
开代理的话会报错:
Could not connect to 127.0.0.1:7890 (127.0.0.1). - connect (111: Connection refused)
查看 man podman-run,添加 --http-proxy=false 解决:
$ podman run --http-proxy=false -it docker.io/kalilinux/kali-rolling:latest /bin/bash
更换 ustc 源
$ echo 'deb http://mirrors.ustc.edu.cn/kali kali-rolling main non-free con
trib' > sources.list
$ apt update && apt -y install kali-linux-headless
ZFS on Fedora
zfs-fuse is a daemon which provides support for the ZFS filesystem, via fuse. Ordinarily this daemon will be invoked from system boot scripts.
$ sudo dnf install zfs-fuse
$ sudo zfs-fuse
$ sudo zpool import dpool
cannot import 'dpool': pool is formatted using a newer ZFS version
$ sudo rpm -e --nodeps zfs-fuse
$ sudo proxychains dnf install -y https://zfsonlinux.org/fedora/zfs-release$(rpm -E %dist).noarch.rpm
$ cat /etc/yum.repos.d/zfs.repo
[zfs]
name=ZFS on Linux for Fedora $releasever
baseurl=http://download.zfsonlinux.org/fedora/$releasever/$basearch/
enabled=0
metadata_expire=7d
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux
[zfs-source]
name=ZFS on Linux for Fedora $releasever - Source
baseurl=http://download.zfsonlinux.org/fedora/$releasever/SRPMS/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux
[zfs-testing]
name=ZFS on Linux for Fedora $releasever - Testing
baseurl=http://download.zfsonlinux.org/fedora-testing/$releasever/$basearch/
enabled=0
metadata_expire=7d
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux
[zfs-testing-source]
name=ZFS on Linux for Fedora $releasever - Testing Source
baseurl=http://download.zfsonlinux.org/fedora-testing/$releasever/SRPMS/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-zfsonlinux
$ sudo proxychains dnf install -y kernel-devel
$ sudo proxychains dnf install -y zfs
$ sudo modprobe zfs
$ echo zfs | sudo tee /etc/modules-load.d/zfs.conf # 可选
$ sudo dnf config-manager --set-disabled zfs
virt-manager
$ sudo dnf install @virtualization
$ sudo vi /etc/libvirt/libvirtd.conf
unix_sock_group = "libvirt"
unix_sock_rw_perms = "0770"
$ sudo systemctl restart libvirtd
$ sudo usermod -a -G libvirt $(whoami)
Now you must log out and log in to apply the changes.
VSCode
$ sudo tee -a /etc/yum.repos.d/vscode.repo << 'EOF'
[code]
name=Visual Studio Code
baseurl=https://packages.microsoft.com/yumrepos/vscode
enabled=1
gpgcheck=1
gpgkey=https://packages.microsoft.com/keys/microsoft.asc
EOF
$ sudo dnf install code
Binary releases of VS Code without MS branding/telemetry/licensing.
$ sudo tee -a /etc/yum.repos.d/vscodium.repo << 'EOF'
[gitlab.com_paulcarroty_vscodium_repo]
name=gitlab.com_paulcarroty_vscodium_repo
baseurl=https://paulcarroty.gitlab.io/vscodium-deb-rpm-repo/rpms/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo/raw/master/pub.gpg
metadata_expire=1h
EOF
$ dnf install codium
Fedora System
Package Manager
Managing DNF Repository
DNF repositories commonly provide their own .repo file. To add such a repository to your system and enable it, run the following command as root:
dnf config-manager --add-repo repository_url
To enable a particular repository or repositories, type the following at a shell prompt as root:
dnf config-manager --set-enabled repository…
To disable a DNF repository, run the following command as root:
dnf config-manager --set-disabled repository…
For example, Google Chrome Repository:
$ cat /etc/yum.repos.d/google-chrome.repo
[google-chrome]
name=google-chrome
baseurl=https://dl.google.com/linux/chrome/rpm/stable/x86_64
enabled=1
gpgcheck=1
gpgkey=https://dl.google.com/linux/linux_signing_key.pub
$ sudo dnf config-manager --set-enabled google-chrome
$ sudo dnf install google-chrome-stable
DNF System Upgrade
$ sudo dnf upgrade --refresh
$ sudo reboot
$ sudo dnf install dnf-plugin-system-upgrade
$ sudo dnf system-upgrade download --releasever=35
$ sudo dnf system-upgrade reboot
- Change the
--releasever=number if you want to upgrade to a different release. - If some of your packages have unsatisfied dependencies, the upgrade will refuse to continue until you run it again with an extra
--allowerasingoption. This often happens with packages installed from third-party repositories for which an updated repositories hasn’t been yet published. Study the output very carefully and examine which packages are going to be removed. None of them should be essential for system functionality, but some of them might be important for your productivity.- In case of unsatisfied dependencies, you can sometimes see more details if you add
--bestoption to the command line. - If you want to remove/install some packages manually before running
dnf system-upgrade downloadagain, it is advisable to perform those operations with--setopt=keepcache=1dnf command line option. Otherwise the whole package cache will be removed after your operation, and you will need to download all the packages once again.
- In case of unsatisfied dependencies, you can sometimes see more details if you add
- There are other important optional operations here, please read the official documentation.
DNF local plugin
An internet search yields two common solutions that eliminate or reduce repeat downloads of the same RPM set – create a private Fedora Linux mirror or set up a caching proxy.
Fedora provides guidance on setting up a [private mirror](https://fedoraproject.org/wiki/ Infrastructure/Mirroring#How_can_someone_make_a_private_mirror). A mirror requires a lot of bandwidth and disk space and significant work to maintain. A full private mirror would be too expensive and it would be overkill for my purposes.
The most common solution I found online was to implement a caching proxy using Squid. I had two concerns with this type of solution. First, I would need to edit repository definitions stored in /etc/yum.repo.d on each virtual and physical machine or container to use the same mirror. Second, I would need to use http and not https connections which would introduce a security risk.
After reading Glenn’s 2018 post on the DNF local plugin, I searched for additional information but could not find much of anything besides the sparse documentation for the plugin on the DNF documentation web site. This article is intended to raise awareness of this plugin.
Use DNS over TLS
dnf updateinfo
First, check the updates available:
$ dnf check-update
OK, so run your first dnf updateinfo command:
$ dnf updateinfo
Look at the list of updates and which types they belong to:
$ dnf updateinfo list
The next command will list the actual changelog.
$ dnf updateinfo info
install only security and bugfixes updates
$ dnf check-update --security --bugfix
$ sudo dnf update --security --bugfix
Install only specific updates
$ sudo dnf update --advisories=FEDORA-2021-74ebf2f06f,FEDORA-2021-83fdddca0f
XFS 檔案系統簡介
CentOS 7 開始,預設的檔案系統已經由原本的 EXT4 變成了 XFS 檔案系統了!為啥 CentOS 要捨棄對 Linux 支援度最完整的 EXT 家族而改用 XFS 呢? 這是有一些原因存在的。
EXT 家族當前較傷腦筋的地方:支援度最廣,但格式化超慢!
Ext 檔案系統家族對於檔案格式化的處理方面,採用的是預先規劃出所有的 inode/block/meta data 等資料,未來系統可以直接取用, 不需要再進行動態配置的作法。這個作法在早期磁碟容量還不大的時候還算 OK 沒啥問題,但時至今日,磁碟容量越來越大,連傳統的 MBR 都已經被 GPT 所取代,連我們這些老人家以前聽到的超大 TB 容量也已經不夠看了!現在都已經說到 PB 或 EB 以上容量了呢!那妳可以想像得到,當你的 TB 以上等級的傳統 ext 家族檔案系統在格式化的時候,光是系統要預先分配 inode 與 block 就消耗你好多好多的人類時間了…
Tips:之前格式化過一個 70 TB 以上的磁碟陣列成為 ext4 檔案系統,按下格式化,去喝了咖啡、吃了便當才回來看做完了沒有… 所以,後來立刻改成 xfs 檔案系統了。
另外,由於虛擬化的應用越來越廣泛,而作為虛擬化磁碟來源的巨型檔案 (單一檔案好幾個 GB 以上!) 也就越來越常見了。 這種巨型檔案在處理上需要考慮到效能問題,否則虛擬磁碟的效率就會不太好看。因此,從 CentOS 7.x 開始, 檔案系統已經由預設的 Ext4 變成了 xfs 這一個較適合高容量磁碟與巨型檔案效能較佳的檔案系統了。
Tips:其實鳥哥有幾組虛擬電腦教室伺服器系統,裡面跑的確實是 EXT4 檔案系統,老實說,並不覺得比 xfs 慢!所以,對鳥哥來說, 效能並不是主要改變檔案系統的考量!對於檔案系統的復原速度、建置速度,可能才是鳥哥改換成 xfs 的思考點。
XFS 檔案系統的配置
基本上 xfs 就是一個日誌式檔案系統,而 CentOS 7.x 拿它當預設的檔案系統,自然就是因為最早之前,這個 xfs 就是被開發來用於高容量磁碟以及高效能檔案系統之用, 因此,相當適合現在的系統環境。此外,幾乎所有 Ext4 檔案系統有的功能, xfs 都可以具備!也因此在本小節前幾部份談到檔案系統時, 其實大部份的操作依舊是在 xfs 檔案系統環境下介紹給各位的哩!
xfs 檔案系統在資料的分佈上,主要規劃為三個部份,一個資料區 (data section)、一個檔案系統活動登錄區 (log section)以及一個即時運作區 (realtime section)。 這三個區域的資料內容如下:
- 資料區 (data section)
基本上,資料區就跟我們之前談到的 ext 家族一樣,包括 inode/data block/superblock 等資料,都放置在這個區塊。 這個資料區與 ext 家族的 block group 類似,也是分為多個儲存區群組 (allocation groups) 來分別放置檔案系統所需要的資料。 每個儲存區群組都包含了 (1)整個檔案系統的 superblock、 (2)剩餘空間的管理機制、 (3)inode的分配與追蹤。此外,inode與 block 都是系統需要用到時, 這才動態配置產生,所以格式化動作超級快!
另外,與 ext 家族不同的是, xfs 的 block 與 inode 有多種不同的容量可供設定,block 容量可由 512bytes ~ 64K 調配,不過,Linux 的環境下, 由於記憶體控制的關係 (分頁檔 pagesize 的容量之故),因此最高可以使用的 block 大小為 4K 而已!(鳥哥嘗試格式化 block 成為 16K 是沒問題的,不過,Linux 核心不給掛載! 所以格式化完成後也無法使用啦!) 至於 inode 容量可由 256bytes 到 2M 這麼大!不過,大概還是保留 256bytes 的預設值就很夠用了!
Tips:總之, xfs 的這個資料區的儲存區群組 (allocation groups, AG),你就將它想成是 ext 家族的 block 群組 (block groups) 就對了!本小節之前講的都可以在這個區塊內使用。 只是 inode 與 block 是動態產生,並非一開始於格式化就完成配置的。
- 檔案系統活動登錄區 (log section)
在登錄區這個區域主要被用來紀錄檔案系統的變化,其實有點像是日誌區啦!檔案的變化會在這裡紀錄下來,直到該變化完整的寫入到資料區後, 該筆紀錄才會被終結。如果檔案系統因為某些緣故 (例如最常見的停電) 而損毀時,系統會拿這個登錄區塊來進行檢驗,看看系統掛掉之前, 檔案系統正在運作些啥動作,藉以快速的修復檔案系統。
因為系統所有動作的時候都會在這個區塊做個紀錄,因此這個區塊的磁碟活動是相當頻繁的!xfs 設計有點有趣,在這個區域中, 妳可以指定外部的磁碟來作為 xfs 檔案系統的日誌區塊喔!例如,妳可以將 SSD 磁碟作為 xfs 的登錄區,這樣當系統需要進行任何活動時, 就可以更快速的進行工作!相當有趣!
- 即時運作區 (realtime section)
當有檔案要被建立時,xfs 會在這個區段裡面找一個到數個的 extent 區塊,將檔案放置在這個區塊內,等到分配完畢後,再寫入到 data section 的 inode 與 block 去! 這個 extent 區塊的大小得要在格式化的時候就先指定,最小值是 4K 最大可到 1G。一般非磁碟陣列的磁碟預設為 64K 容量,而具有類似磁碟陣列的 stripe 情況下,則建議 extent 設定為與 stripe 一樣大較佳。這個 extent 最好不要亂動,因為可能會影響到實體磁碟的效能喔。
XFS 檔案系統的描述資料觀察
剛剛講了這麼多,完全無法理會耶~有沒有像 EXT 家族的 dumpe2fs 去觀察 superblock 內容的相關指令可以查閱呢?有啦!可以使用 xfs_info 去觀察的! 詳細的指令作法可以參考如下:
[root@study ~]# xfs_info 掛載點|裝置檔名
範例一:找出系統 /boot 這個掛載點底下的檔案系統的 superblock 紀錄
[root@study ~]# df -T /boot
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/vda2 xfs 1038336 133704 904632 13% /boot
# 沒錯!可以看得出來是 xfs 檔案系統的!來觀察一下內容吧!
[root@study ~]# xfs_info /dev/vda2
1 meta-data=/dev/vda2 isize=256 agcount=4, agsize=65536 blks
2 = sectsz=512 attr=2, projid32bit=1
3 = crc=0 finobt=0
4 data = bsize=4096 blocks=262144, imaxpct=25
5 = sunit=0 swidth=0 blks
6 naming =version 2 bsize=4096 ascii-ci=0 ftype=0
7 log =internal bsize=4096 blocks=2560, version=2
8 = sectsz=512 sunit=0 blks, lazy-count=1
9 realtime =none extsz=4096 blocks=0, rtextents=0
上面的輸出訊息可以這樣解釋:
- 第 1 行裡面的 isize 指的是 inode 的容量,每個有 256bytes 這麼大。至於 agcount 則是前面談到的儲存區群組 (allocation group) 的個數,共有 4 個, agsize 則是指每個儲存區群組具有 65536 個 block 。配合第 4 行的 block 設定為 4K,因此整個檔案系統的容量應該就是 4655364K 這麼大!
- 第 2 行裡面 sectsz 指的是邏輯磁區 (sector) 的容量設定為 512bytes 這麼大的意思。
- 第 4 行裡面的 bsize 指的是 block 的容量,每個 block 為 4K 的意思,共有 262144 個 block 在這個檔案系統內。
- 第 5 行裡面的 sunit 與 swidth 與磁碟陣列的 stripe 相關性較高。這部份我們底下格式化的時候會舉一個例子來說明。
- 第 7 行裡面的 internal 指的是這個登錄區的位置在檔案系統內,而不是外部設備的意思。且佔用了 4K * 2560 個 block,總共約 10M 的容量。
- 第 9 行裡面的 realtime 區域,裡面的 extent 容量為 4K。不過目前沒有使用。
由於我們並沒有使用磁碟陣列,因此上頭這個裝置裡頭的 sunit 與 extent 就沒有額外的指定特別的值。根據 xfs(5) 的說明,這兩個值會影響到你的檔案系統性能, 所以格式化的時候要特別留意喔!上面的說明大致上看看即可,比較重要的部份已經用特殊字體圈起來,你可以瞧一瞧先!
Rosetta
由于我主要使用 ubuntu,为学习而使用 fedora,只是短时期使用过其他发行版,因此截取部分如下。
Basic operations
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Search for package(s) by searching the expression in name, description, short description. What exact fields are being searched by default varies in each tool. Mostly options bring tools on par. | dnf search |
apt search |
| Install a package(s) by name | dnf install |
apt install |
| Upgrade Packages - Install packages which have an older version already installed | dnf upgrade |
apt update and then apt upgrade |
| Upgrade Packages - Another form of the update command, which can perform more complex updates – like distribution upgrades. When the usual update command will omit package updates, which include changes in dependencies, this command can perform those updates. | dnf distro-sync |
apt update and then apt dist-upgrade |
| Remove a package(s) and all dependencies by name | dnf remove |
apt autoremove |
| Remove a package(s) and its configuration files | ? | apt purge |
| Remove a package(s) and all dependencies and configuration files | ? | apt autoremove --purge |
| Remove dependencies that are no longer needed (orphans), because e.g. the package which needed the dependencies was removed. | dnf autoremove |
apt autoremove |
| Remove packages no longer included in any repositories. | dnf repoquery --extras |
aptitude purge '~o' |
| Mark a package previously installed as a dependency as explicitly required. | dnf mark install |
apt-mark manual |
| Install package(s) as dependency / without marking as explicitly required. | dnf install and then dnf mark remove |
apt-mark auto |
| Only downloads the given package(s) without unpacking or installing them | dnf download |
apt install --download-only (into the package cache) or apt download (bypass the package cache) |
| Clean up all local caches. Options might limit what is actually cleaned. | dnf clean all |
apt autoclean removes only unneeded, obsolete information or apt clean |
| Start a shell to enter multiple commands in one session | dnf shell |
|
| Show a log of actions taken by the software management. | dnf history |
read /var/log/dpkg.log |
| Get a dump of the whole system information - Prints, Saves or similar the current state of the package management system. Preferred output is text or XML. (Note: Why either-or here? No tool offers the option to choose the output format.) | see /var/lib/rpm/Packages |
apt-cache stats |
| e-mail delivery of package changes | apt install apt-listchanges |
Querying specific packages
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Show all or most information about a package. The tools' verbosity for the default command vary. But with options, the tools are on par with each other. | dnf list or dnf info |
apt show or apt-cache policy |
| Display local package information: Name, version, description, etc. | rpm -qi / dnf info installed |
dpkg -s or aptitude show |
| Display remote package information: Name, version, description, etc. | dnf info |
apt-cache show or aptitude show |
| Display files provided by local package | rpm -ql |
dpkg -L |
| Display files provided by a remote package | dnf repoquery -l or repoquery -l (from package yum-utils) |
apt-file list |
| Query the package which provides FILE | rpm -qf (installed only) or dnf provides (everything) or repoquery -f (from package yum-utils) |
dpkg -S or dlocate |
| List the files that the package holds. Again, this functionality can be mimicked by other more complex commands. | dnf repoquery -l |
dpkg-query -L |
| Displays packages which provide the given exp. aka reverse provides. Mainly a shortcut to search a specific field. Other tools might offer this functionality through the search command. | dnf provides |
apt-file search |
| Search all packages to find the one which holds the specified file. | dnf provides |
apt-file search or auto-apt is using this functionality. |
| Show the changelog of a package | dnf changelog |
apt-get changelog |
Querying package lists
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Search for package(s) by searching the expression in name, description, short description. What exact fields are being searched by default varies in each tool. Mostly options bring tools on par. | dnf search |
apt search |
| Lists packages which have an update available. Note: Some provide special commands to limit the output to certain installation sources, others use options. | dnf list updates or dnf check-update |
apt list --upgradable |
| Display a list of all packages in all installation sources that are handled by the packages management. Some tools provide options or additional commands to limit the output to a specific installation source. | dnf list available |
apt-cache dumpavail or apt-cache dump (Cache only) or apt-cache pkgnames |
| Generates a list of installed packages | dnf list installed |
`dpkg –list |
| List packages that are installed but are not available in any installation source (anymore). | dnf list extras |
`apt –installed list |
| List packages that were recently added to one of the installation sources, i.e. which are new to it. | dnf list recent |
aptitude search '~N' or aptitude forget-new |
| List installed local packages along with version | rpm -qa |
dpkg -l or apt list --installed |
| Search locally installed package for names or descriptions | rpm -qa '*<str>*' |
`aptitude search ‘~i(~n $name |
| List packages not required by any other package | dnf leaves or package-cleanup --leaves --all |
deborphan -anp1 |
| List packages installed explicitly (not as dependencies) | dnf history userinstalled |
apt-mark showmanual |
| List packages installed automatically (as dependencies) | grep -E ‘^i[^+]’ (workaround) | apt-mark showauto |
Querying package dependencies
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Display packages which require X to be installed, aka show reverse dependencies. | dnf repoquery --alldeps --whatrequires or repoquery --whatrequires |
apt-cache rdepends or aptitude search ~D$pattern |
| Display packages which conflict with given expression (often package). Search can be used as well to mimic this function. | dnf repoquery --conflicts |
aptitude search '~C$pattern' |
| List all packages which are required for the given package, aka show dependencies. | dnf repoquery --requires or repoquery -R |
apt-cache depends or apt-cache show |
| List what the current package provides | dnf repoquery --provides |
dpkg -s or aptitude show |
| List all packages that require a particular package | dnf repoquery --installed --alldeps --whatrequires |
aptitude search ~D{depends,recommends,suggests}:$pattern or aptitude why |
| Display all packages that the specified packages obsoletes. | dnf list obsoletes |
apt-cache show |
| Generates an output suitable for processing with dotty for the given package(s). | apt-cache dotty |
Installation sources management
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Installation sources management | edit /etc/yum.repos.d/${REPO}.repo |
edit /etc/apt/sources.list |
| Add an installation source to the system. Some tools provide additional commands for certain sources, others allow all types of source URI for the add command. Again others, like apt and dnf force editing a sources list. apt-cdrom is a special command, which offers special options design for CDs/DVDs as source. | /etc/yum.repos.d/*.repo |
apt-cdrom add |
| Refresh the information about the specified installation source(s) or all installation sources. | dnf clean expire-cache and then dnf check-update |
apt-get update |
| Prints a list of all installation sources including important information like URI, alias etc. | cat /etc/yum.repos.d/* |
apt-cache policy |
| List all packages from a certain repo | ||
| Disable an installation source for an operation | dnf --disablerepo= |
|
| Download packages from a different version of the distribution than the one installed. | dnf --releasever= |
apt-get install -t release package or apt-get install package/release (dependencies not covered) |
Overrides
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Add a package lock rule to keep its current state from being changed | edit dnf.conf adding/amending the exclude option |
apt-mark hold pkg |
| Delete a package lock rule | apt-mark unhold pkg |
|
| Show a listing of all lock rules | /etc/apt/preferences |
|
| Set the priority of the given package to avoid upgrade, force downgrade or to overwrite any default behavior. Can also be used to prefer a package version from a certain installation source. | /etc/apt/preferences, apt-cache policy |
|
| Remove a previously set priority | /etc/apt/preferences |
|
| Show a list of set priorities | apt-cache policy or /etc/apt/preferences |
|
| Ignore problems that priorities may trigger. |
Verification and repair
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Verify single package | rpm -V |
debsums |
| Verify all packages | rpm -Va |
debsums |
| Reinstall given package; this will reinstall the given package without dependency hassle | dnf reinstall |
apt install --reinstall |
| Verify dependencies of the complete system; used if installation process was forcefully killed | dnf repoquery --requires |
apt-get check |
| Use some magic to fix broken dependencies in a system | dnf repoquery --unsatisfied |
apt-get --fix-broken and then aptitude install |
| Add a checkpoint to the package system for later rollback | (unnecessary, it is done on every transaction) | |
| Remove a checkpoint from the system | n/a | |
| Provide a list of all system checkpoints | dnf history list |
|
| Rolls entire packages back to a certain date or checkpoint | dnf history rollback |
|
| Undo a single specified transaction | dnf history undo |
Using package files and building packages
| Action | Red Hat/Fedora | Debian/Ubuntu |
|---|---|---|
| Query a package supplied on the command line rather than an entry in the package management database | rpm -qp |
dpkg -I |
| List the contents of a package file | rpmls rpm -qpl |
dpkg -c |
| Install local package file, e.g. app.rpm and uses the installation sources to resolve dependencies | dnf install |
apt install |
| Updates package(s) with local packages and uses the installation sources to resolve dependencies | dnf upgrade |
debi |
| Add a local package to the local package cache mostly for debugging purposes. | apt-cache add *package-filename* |
|
| Extract a package | `rpm2cpio | cpio -vid` |
| Install/Remove packages to satisfy build-dependencies. Uses information in the source package | dnf builddep |
apt-get build-dep |
| Display the source package to the given package name(s) | dnf repoquery -s |
apt-cache showsrc |
| Download the corresponding source package(s) to the given package name(s) | dnf download --source |
apt-get source or debcheckout |
| Build a package | rpmbuild -ba (normal) or mock (in chroot) |
debuild |
| Check for possible packaging issues | rpmlint | lintian |
Fedora Tips
kill
kill 是向进程发送信号的命令。
| 代号 | 名称 | 内容 |
|---|---|---|
| 1 | SIGHUP | 启动被终止的程序,可让该进程重新读取自己的配置文件,类似重新启动。 |
| 2 | SIGINT | 相当于用键盘输入 [ctrl]-c 来中断一个程序的进行。 |
| 9 | SIGKILL | 代表强制中断一个程序的进行,如果该程序进行到一半,那么尚未完成的部分可能会有“半产品”产生,类似 vim会有 .filename.swp 保留下来。 |
| 15 | SIGTERM | 以正常的方式来终止该程序。由于是正常的终止,所以后续的动作会将他完成。不过,如果该程序已经发生问题,就是无法使用正常的方法终止时,输入这个 signal 也是没有用的。 |
| 19 | SIGSTOP | 相当于用键盘输入 [ctrl]-z 来暂停一个程序的进行。 |
Shell freezes
In the event of a shell freeze (which might be caused by certain appearance tweaks, malfunctioning extensions or perhaps a lack of available memory), restarting the shell by pressing Alt+F2 and then entering r may not be possible.
In this case, try switching to another TTY (Ctrl+Alt+F2) and entering the following command: pkill -HUP gnome-shell. It may take a few seconds before the shell successfully restarts. On X11, restarting the shell in this fashion should not log the user out, but it is a good idea to try and ensure that all work is saved anyway; on Wayland (currently the default), restarting the shell kills the whole session, so everything will be lost.
If this fails, the Xorg server will need to be restarted either by pkill X for console logins or by restarting gdm.service for GDM logins. Bear in mind that restarting the Xorg server will log the user out, so try to ensure that all work is saved before attempting this.
fix a frozen Gnome desktop session
在较旧的 Gnome(即 Gnome 3.28 之前)中,您可以使用此命令重新启动 GNome shell。
$ glxinfo | grep display
name of display: :1
display: :1 screen: 0
$ touch gnome-restart
$ echo '#!/bin/bash' > gnome-restart
$ echo 'DISPLAY=:1 gnome-shell --replace &' >> gnome-restart
$ sudo chmod +x gnome-restart
$ ./gnome-restart
重启 Gnome Shell
可以使用 busctl --user call org.gnome.Shell /org/gnome/Shell org.gnome.Shell Eval s 'Meta.restart("Restarting…")' 命令行执行 ALT + F2 r 相同的操作。
亦可:
$ sudo systemctl restart systemd-logind
Gaming on Fedora
Fedora 33 百度网盘Linux版
那个 rpm 包压根不是对标最新的Fedora的,而是给那些基于RHEL的同样使用rpm包管理的古董国产操作系统使用的。
下载 baidunetdisk_3.5.0_amd64.deb,并解压出实际的程序。
首先我们跑一下,看看bt 吧:
Thread 1 "baidunetdisk" received signal SIGSEGV, Segmentation fault.
0x00007ffff5096179 in EVP_MD_CTX_clear_flags () from /lib64/libcrypto.so.1.1
(gdb) bt
目测翻车在libcrypto.so.1.1, 而且是跟sqlite加密有关.
我们把baidunetdisk动态链接到相关的加密库都找出来:
$ ldd baidunetdisk | grep -i -E 'ssl|crypt'
libgcrypt.so.20 => /lib64/libgcrypt.so.20 (0x00007fa18d693000)
libk5crypto.so.3 => /lib64/libk5crypto.so.3 (0x00007fa18d3cd000)
libcrypto.so.1.1 => /lib64/libcrypto.so.1.1 (0x00007fa18d0c0000)
经验告诉我,这个baidunetdisk挂的原因是, Fedora 33上面的包都比较新,尤其是 openssl 库. 因此,解决办法是,去下载老版本的 Ubuntu 18.04 的包,然后把so文件取出来,强制baidunetdisk使用这些旧版本的库即可.
ldd 一下很容易找出依赖关系: libkrb5.so.3 -> libk5crypto.so.3 -> libcrypto.so.1.1
下载以下包:
https://ubuntu.pkgs.org/18.04/ubuntu-main-amd64/libkrb5support0_1.16-2build1_amd64.deb.html
https://ubuntu.pkgs.org/18.04/ubuntu-main-amd64/libk5crypto3_1.16-2build1_amd64.deb.html
https://ubuntu.pkgs.org/18.04/ubuntu-main-amd64/libkrb5-3_1.16-2build1_amd64.deb.html
https://ubuntu.pkgs.org/18.04/ubuntu-main-amd64/libgssapi-krb5-2_1.16-2build1_amd64.deb.html
http://archive.ubuntu.com/ubuntu/pool/main/o/openssl/libssl1.1_1.1.0g-2ubuntu4_amd64.deb
编辑 /usr/share/applications/baidunetdisk.desktop, 将Exec=/opt/baidunetdisk/baidunetdisk --no-sandbox %U 修改成:
Exec=/bin/env LD_LIBRARY_PATH=/home/ttys3/Apps/baidunetdisk /home/ttys3/Apps/baidunetdisk/baidunetdisk --no-sandbox %U
ldd 查看程序依赖库
作用:用来查看程式运行所需的共享库,常用来解决程式因缺少某个库文件而不能运行的一些问题。
示例:查看test程序运行所依赖的库:
/opt/app/todeav1/test$ ldd test
libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x00000039a7e00000)
libm.so.6 => /lib64/libm.so.6 (0x0000003996400000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00000039a5600000)
libc.so.6 => /lib64/libc.so.6 (0x0000003995800000)
/lib64/ld-linux-x86-64.so.2 (0x0000003995400000)
/opt/app/todeav1/test$ ldd libc.so.6
...
- 第一列:程序需要依赖什么库
- 第二列: 系统提供的与程序需要的库所对应的库
- 第三列:库加载的开始地址
通过上面的信息,我们可以得到以下几个信息:
- 通过对比第一列和第二列,我们可以分析程序需要依赖的库和系统实际提供的,是否相匹配
- 通过观察第三列,我们可以知道在当前的库中的符号在对应的进程的地址空间中的开始位置
如果依赖的某个库找不到,通过这个命令可以迅速定位问题所在。
原理: ldd不是个可执行程式,而只是个shell脚本; ldd显示可执行模块的dependency的工作原理,其实质是通过ld-linux.so(elf动态库的装载器)来实现的。ld-linux.so模块会先于executable模块程式工作,并获得控制权,因此当上述的那些环境变量被设置时,ld-linux.so选择了显示可执行模块的dependency。
adb and fastboot
$ sudo dnf install android-tools
OneDrive 加速
OneDrive 的下载速度,明白的都明白,不懂得也就算了 。
PC 端(手机端应该也可以)有一个可能有效的提速方法是:
- 前往:https://tools.ipip.net/traceroute.php
- 左侧 ipv6 或 ipv4 选择离自己最近的运营商,右侧 ICMP 填入
sharepoint.com - 搜索之后将延时最短的非局域网 ip 填入在
hosts文件中 - 保存,使之生效,可以在控制台
ping sharepoint.com查看是否成功解析到新的 ip
Recover a root password
-
Boot the Live installation media and choose
Try Fedora. -
From the desktop, open a terminal and switch to root using
su(the system will not ask for a password). -
To view your hard drive device nodes, enter
df -Hinto the terminal. For this example we will use/dev/sda1for the/bootpartition and/dev/sda2for the root/partition.If you are using LVM partitions, type:
sudo lvscanand note the/devpath of your root partition. For this example we will use/dev/fedora/root. -
Create a directory for the mount point (use the
-poption to create subdirectories):mkdir -p /mnt/sysimage/boot -
Mount the
/(root) partition (be sure to use the actual device node or LVM path of your root/partition):To mount root on a standard partition scheme enter:
mount /dev/sda2 /mnt/sysimageTo mount root on an LVM partition scheme enter:
mount /dev/fedora/root /mnt/sysimage -
Continue the process by mounting
/boot,proc,/dev, and/runwith:mount /dev/sda1 /mnt/sysimage/boot mount -t proc none /mnt/sysimage/proc mount -o bind /dev /mnt/sysimage/dev mount -o bind /run /mnt/sysimage/run -
chrootto the mounted root partition with:chroot /mnt/sysimage /bin/bash -
Change the root password:
passwd -
Exit out of chroot with:
exitand exit out of the terminal.
-
Reboot your system and boot from the hard drive.
Congratulations, your root password has been successfully changed.
Samba Server
Install and Configure Samba
To get started with samba, you need to install the samba core packages and samba-client package as shown:
# dnf install samba samba-common samba-client
After all the samba is installed, you need to configure the samba share directory with proper permissions and ownership, so that it is going to be shared with all client machines in the same local network.
# mkdir -p /srv/tecmint/data
# chmod -R 755 /srv/tecmint/data
# chown -R nobody:nobody /srv/tecmint/data
# chcon -t samba_share_t /srv/tecmint/data
Next, we are going to configure the Samba share directory in the smb.conf file, which is the main configuration file for Samba.
# mv /etc/samba/smb.conf /etc/samba/smb.conf.bak
# vim /etc/samba/smb.conf
Add the following configuration lines, which define the policies on who can access the samba share on the network.
[global]
workgroup = WORKGROUP
server string = Samba Server %v
netbios name = rocky-8
security = user
map to guest = bad user
dns proxy = no
ntlm auth = true
[Public]
path = /srv/tecmint/data
browsable =yes
writable = yes
guest ok = yes
read only = no
Save and exit the configuration file.
Next, verify the samba configuration for errors.
# testparm
If everything looks okay, make sure to start, enable and verify the status of the Samba daemons.
# systemctl start smb
# systemctl enable smb
# systemctl start nmb
# systemctl enable nmb
# systemctl status smb
# systemctl status nmb
Accessing Samba Share from Windows
To access Samba share from the Windows machine, press the Windows logo key + R to launch the Run dialog and enter the IP address of the samba server
Secure Samba Share Directory
To secure our Samba share, we need to create a new samba user.
# useradd smbuser
# smbpasswd -a smbuser
Next, create a new group and add the new samba user to this group.
# sudo groupadd smb_group
# sudo usermod -g smb_group smbuser
Thereafter, create another secure samba share directory for accessing files securely by samba users.
# mkdir -p /srv/tecmint/private
# chmod -R 770 /srv/tecmint/private
# chcon -t samba_share_t /srv/tecmint/private
# chown -R root:smb_group /srv/tecmint/private
Once again, access the Samba configuration file.
# vi /etc/samba/smb.conf
Add these lines to define to secure samba share.
[Private]
path = /srv/tecmint/private
valid users = @smb_group
guest ok = no
writable = no
browsable = yes
Save the changes and exit.
Finally, restart all the samba daemons as shown.
$ sudo systemctl restart smb
$ sudo systemctl restart nmb
Now try to access the Samba share, this time you will see an additional ‘Private‘ directory. To access this directory, you will be required to authenticate with the Samba user’s credentials
[MIT/GNU Scheme](MIT/GNU Scheme)
9.2 是最后支持 windows 的版本,之前的版本我在fedora上编译失败了。
$ wget https://ftp.gnu.org/gnu/mit-scheme/stable.pkg/9.2/mit-scheme-9.2-x86-64.tar.gz
$ sudo dnf install gcc make m4 ncurses-devel libX11-devel
$ tar xzf mit-scheme-VERSION-i386.tar.gz
$ cd mit-scheme-VERSION/src
$ sudo ./configure --prefix=/opt/mit-scheme
$ sudo make
$ sudo make install
WAV、FLAC、APE
区别
同一个音乐文件而言,WAV、FLAC、APE三种音乐格式的音质是完全一样的。
意思是说,从CD碟上抓轨出来后,得到的WAV和APE、FLAC音质完全相同,实际上是不同形式的同一个文件。但与CD碟是否完全一样,除了抓轨操作问题,基本上都是电脑设备技术所限。(你不能要求电脑器材技术同灌制唱片的专业器材一致,电脑只是个均衡性技术器材组合体。)
所以,从收藏角度来说,三种格式可以,一样。但播放效果上,上万元的专业设备和神经质般的金耳朵是能听出些许差别来的,这主要是因为不同格式间因编码不同导致解码速度不同所致;如果转换为同一种格式,正常听是没有区别的。
那么,APE、FLAC、WAV三种格式区别在哪里呢?(这些区别并不是说音乐文件本身品质有优劣)
-
编码不同,导致解码速度WAV > FLAC > APE,直接影响到播放听感流畅性上:WAV > FLAC > APE
WAV波形文件是音响设备和很多软件可以直接读取的波形文件,基本上不存在编解码问题。flac和ape都对WAV进行了编码,故能换取较小的体积,但同时造成解码播放时,因播放器材解析力很敏感(或者说技术所限),会因出现一定的jitter抖动(解析复杂编码所致)而导致播放效果不够饱满和流畅。这点你可以通过统一转换为WAV格式来试听解决。
-
编码不同,导致所占空间大小 APE < FLAC < WAV。
由于flac和ape都对WAV进行了更高技术的编码,所以换取了较小的体积,这也是这两种格式之所以出现的根本原因。由于二者都是无损压缩,如果你是为了收藏,同时你的空间比较吃紧,无疑收藏较小体积的APE是最佳选择。至于以后会不会出现更小体积的无损压缩格式,但目前来说,APE 是最优选择。
-
编码不同,解码速度不一,导致占用CPU和耗电量不同。
编码越复杂,解码越麻烦,自然占用内存率越高,耗电量自然越大。那些伤不起的播放机们感触最深,同样的电量,三种格式播放时长依次为由长到短:WAV > FLAC > APE,所以,如果你的P5播放机比较脆弱,自然选择WAV可以享受更长时间的音乐。
-
开源性不同,导致纠错效果不同。
这一点各取所需吧!很多flac粉们对APE的防纠错和容错性大为诟病,指责其一报错就无法继续播放,等于整轨作废,同时嫌技术不开放(难道你自己要编程?搞不懂这个意见也这么大)。而flac用静音处理方式他们就认为很好。
个人认为,如果播放的话,因为一个错误就整轨不能播放,等于白下载,的确很烦人,而flac静音处理得以继续播放下面的曲目,的确人性;但从收藏的角度而言,静音处理错误是不是有点瞒天过海、自欺欺人?发烧者和收藏癖们对人耳觉察不到的细微差别都耿耿于怀,怎么会放过这么大的差错?反正,如果有错误音轨,我是肯定不要收藏的,而APE,正好给我了检验好坏质量的途径。
-
开源性不同,导致支持软件多寡不均。
编码软件的支持上,大家都说支持flac的软件比ape多。这点没问题。但并不等于支持Ape格式的播放软件就少。实际上,现在已经有很多软件支持ape了。而且,支持flac的软件虽然多,也有很多不支持flac的,但wav就不一样了,还没有不支持WAV格式的播放器呢!这样说来,是不是也要把flac淘汰掉?!其实,听的时候就那么几首歌,转一下格式能够让你的播放器支持不就好啦。
从收藏角度讲,APE、FLAC、WAV三种格式一样,文件音质相同;从播放来讲,格式不同,专业设备下,效果可能会有人耳察觉不同的区别(楼主没感觉出来)。
扩展知识
无损音乐音质也分“三六九等”
同一个文件的各个无损格式是一样的音质,如果不是同一个文件,即使是同一首歌,音质也分三六九等。举个例子,彭丽媛的曲目《在希望的田野上》 ,收录于《非同凡响》、《沂蒙山小调》、《演唱中国民歌》、《珠穆朗玛》等多个音乐专辑,这些专辑分别由不同的唱片公司于不同的时间出版,音质就会参差不齐。同时,由于时代不同,技术上受历史局限。也会导致音质有别。
为什么无损音乐和CD比较,听觉上会有细微差别?
无损音乐与CD碟片数据信息完全一样,那为什么音效不一样呢?嗯,这里我用的“音效”这个词非常好。CD碟和原声一样吗?肯定不一样。主要是技术上根本做不到完全还原原声。而且,为了音乐效果,一般还会加进各种特效。CD播放机和电脑,更是两个功用完全不同的设备。音效当然不可能一致。
其实,就算CD播放机,也不可能找到两台播放效果完全一样的。有句话,大意是世界上不可能找到两把相同的二胡,也是这个意思。
假无损是怎么回事?
到这里,我就给大家提炼出一个观点:【“无损音乐”不等于“无损音质”】
除了碟片录制设备技术问题(早期碟片音质都不好;不同唱片公司录制技术层次不同;国内碟相对国外顶级技术也不好),也有假无损,即不是由正版CD碟片抓轨得到,而是通过盗版碟片抓轨、磁带(卡带)翻录甚至是有损音乐(MP3等)转换而得到。这些APE、FLAC、WAV等格式的所谓的“无损音乐”,其音质就很差很差。
除了第一个原因我们无奈选择外,其他的发烧友都应该剔除。对于磁带翻录,如果是稀有资源,建议大家保留,因为如果找不到无损,有总比无好。
我的音乐听起来音质不好,是无损吗?
前面说了,【“无损音乐”不等于“无损音质”】,无损音乐严格来说,是指wav波形文件从音乐CD碟片的无损数字记录和APE、FLAC、WavPack、WMALossless等则是对WAV波形文件进行无损压缩。wav是无损音乐文件,APE、FLAC等则是无损压缩音乐文件。绝对意义上讲,他们都不能完全替代CD碟。WAV波形文件在媒体播放器里直接播放,而APE等其他压缩格式则需要经过解压(解码)还原成WAV再进行播放。
如果你的无损音乐听感比较差,这你就要注意了
⒈ 是真无损,多见于早期碟片。由于上世纪CD碟片刚起步,技术水平有限,故灌制效果相对今天的碟片来说欠佳。此外,即使今天,不同唱片公司出品的碟片,音质也有差别。在没有替代品的情况下,建议保留。
⒉ 是真无损,音质不好可能由抓轨操作失误造成“爆音”等数据信息残缺,建议更换。
⒊ 显示真无损,音质极差。这多由磁带/卡带转录而来。早期歌手只有磁带作品留世,虽然音质不好,但是唯一的纪念品。将其转录为数据,是为了更好地保存。在没有替代品的情况下,建议保留。
⒋ 假无损。即由有损格式MP3、WMA、OGG等格式转换而来,有些凭耳听,甚至难与真无损辨别,只有软件能检测出。有损转无损,丢失的信息不会转回来。虽然体积增大了,音质还是有损的音质。
如何鉴别无损音乐?
如何鉴别?主要是一靠听、二靠看、三靠软件检测。
注意软件检测也会出错,只是作为参考。毕竟,音乐最主要的用途是欣赏,而不是科学精密研究。建议大家首先听。比如磁带转录的,一般一听就听出来。但软件检测未必检测出。这是因为软件作用只是检测哪些是由有损低劣的音乐转换成的伪劣假冒无损。
-
【一听】
听第一感觉,如果音质不好,甚至有爆音,即使是真无损,也是音质较差的低劣无损。
-
【二看】看占用空间大小和播放码率
看占用空间大小,一定要在相同格式的前提下,否则用APE和FLAC比较,是无意义的。一般,两个时长、内容一致的同名文件,占用空间越大者原则上包含信息越丰富、音质越好;看播放码率。
-
【三检测】用无损检验软件检测,和看频谱。
篇外篇
长期来,很多人对MP3印象不好,更多人认为WMA的最佳音质要好过MP3,这种说法是不正确的,在中高码率下,编码得当的MP3要比WMA优秀很多,可以非常接近CD音质,在不太好的硬件设备支持下,没有多少人可以区分两者的差异,这不是神话故事,尽管你以前盲听就可以很轻松区分MP3和CD,但现在你难保证你可以分辨正确。因为MP3也是优秀的编码,以前被埋没了。
大家都谈说音质好,一种是指还原度好,就是说和录制的时候差别越小越好;一种是指悦耳,就是好听。就mp3来说,mp3是一种压缩格式,码率越高,通常来说就代表压缩小,损失的细节比较少,也就是说,码率越高听起来越接近原声。但是音质还和你的输出设备有关,比如说一部好的mp3,一对好耳机,这都对你的听音音质有帮助!因此,如果想改善音质,不妨从以上几个角度出发,不要过分强调其中哪一方面。
视频编码码率控制
背景知识:
视频编码过程中,有一个重要步骤:量化,量化属于有损压缩过程。量化基本决定了视频的码率,视频的码率又从一定程度上决定了视频的质量。量化值QP越大则量化的粒度越高,压缩率越大,码率更小,视频质量越低,呈现出来就是马赛克比较大,画面不细腻,画面比较模糊。反之,压缩率低,码率大,质量高,画面细腻,细节丰富。
所以选择一个适合场景的视频码控方案很重要,调整视频输出码率其实就是在视频编码速度、网络带宽以及视频质量之间做一个平衡。有时网络带宽很受限,就要优先考虑码率大小优先的码控方案,有些对视频质量要求很高,要高清视频,那就要选择质量优先的模型。
整体来说选择视频编码码率控制方案,可以通过下面五个因素权衡得出:
-
视觉质量稳定性,利于视觉主观质量,比如清晰度,流畅度,细节等,这点和人眼的视觉原理有关,选择人眼主动质量感受最高的模型;
-
即时输出码率,相当于每帧编码输出比特数,要考虑网络带宽因素,随着移动互联网发展,也需要考虑wifi和无线网这块的影响;
-
输出视频文件大小可控,利于传输,存储,要看系统的空间大小;
-
编码速度,不同的码控模型也影响了编码速度,对于低延时、实时场景要考虑,因为不同的码控方案,计算的复杂度不同,带来的编码延时也有影响;
-
对于移动设备还需要不同编码方式耗电量要求,因为不同模型会影响编码和解码复杂度,进而在移动设备编码和播放需要的耗电量不同;
CBR
恒定码率(Constant Bit Rate),一定时间范围内比特率基本保持的恒定,属于码率优先模型。
**适用场景:**一般也不建议使用这种方式,虽然输出的码率总是处于一个稳定值,但是质量不稳定,不能充分有效利用网络带宽,因为这种模型不考虑视频内容的复杂性,把所有视频帧的内容统一对待。但是有些编码软件只支持固定质量或者固定码率方式,有时不得不用。用的时候在允许的带宽范围内尽可能把带宽设置大点,以防止复杂运动场景下视频质量很低,如果设置的不合理,在运动场景下直接就糊的看不成了。
特点:
- 码率稳定,但是质量不稳定,带宽有效利用率不高,特别当该值设置不合理,在复杂运动场景下,画面非常模糊,非常影响观看体验;
- 但是输出视频码率基本稳定,便于计算视频体积大小;
VBR
可变码率(Variable Bit Rate),简单场景分配比较大的QP,压缩率小,质量高。复杂场景分配较小QP。得到基本稳定的视觉质量,因为人眼人眼本来就对复杂场景不敏感,缺点在于输出码率大小不可控。
有两种调控模式:质量优先模式和2PASS二次编码模式。
质量优先模式:
不考虑输出视频文件的大小,完全按照视频的内容复杂程度来分配码率,这样视频的播放效果质量最好。
二次编码方式2PASS:
第一次编码检测视频内容的简单和复杂部分,同时确定简单和复杂的比例。第二遍编码会让视频的平均码率不变,复杂的地方分配多bit,简单地方分配少bit。这种编码虽然很好,但是速度会跟不上。
**适用场景:**VBR适用于那些对带宽和编码速度不太限制,但是对质量有很高要求的场景。特别是在运动的复杂场景下也可以保持比较高的清晰度且输出质量比较稳定,适合对延时不敏感的点播,录播或者存储系统。
特点:
- 码率不稳定,质量基本稳定且非常高;
- 编码速度一般比较慢,点播、下载和存储系统可以优先使用,不适合低延时、直播系统;
- 这种模型完全不考虑输出的视频带宽,为了质量,需要多少码率就占用多少,也不太考虑编码速度;
ABR
恒定平均目标码率(Average Bit Rate),简单场景分配较低bit,复杂场景分配足够bit,使得有限的bit数能够在不同场景下合理分配,这类似VBR。同时一定时间内,平均码率又接近设置的目标码率,这样可以控制输出文件的大小,这又类似CBR。可以认为是CBR和VBR的折中方案,这是大多人的选择。特别在对质量和视频带宽都有要求的情况下,可以优先选择该模式,一般速度是VBR的两倍到三倍,相同体积的视频文件质量却比CBR好很多。
**适用场景:**ABR在直播和低延时系统用的比较多,因为只编码了一次,所以速度快,同时兼顾了视频质量和带宽,对于转码速度有要求的情况下也可以选择该模式。B站的大部分视频就选择了该模式。
特点:
- 视频质量整体可控,同时兼顾了视频码率和速度,是一个折中方案,实际用的比较多;
- 使用过程一般要让调用方设置,最低码率、最高码率和平均码率,这些值要尽可能设置合理点;
总结
不懂的話沒關係,反正普遍情況是這樣的:
-
音質:CBR > VBR > ABR
192 kbps以下的CBR,與後兩者無明顯差異,但檔案容量差很多,建議有心要壓CBR就直接衝高流量!
-
檔案大小:CBR > VBR & ABR
後兩者隨參數設定而有差別,大致上差不了多少
DFF、DSF、DST
- DSD是SACD采用的信号调制方式,相当于CDDA(普通CD)采用的PCM调制方式。
- DSF、DFF是SACD碟片中数据的未压缩编码格式,DSF用于Sony,DFF用于Philips,相当于CDDA碟片中的WAV文件。
- DST是一种对SACD中DSF、DFF数据进行无损压缩的编码格式,相当于FLAC、APE是对CDDA中WAV数据的无损压缩。
RPM 搜索与下载网站
- pkgs.org:最好的
- rpm.pbone.net:比较全面但是下载速度有点慢
- rpmfind.net:速度还可以就是没有上面的全
- crpm.cn
误删了 /usr/share/icons 目录
-
从他们的官方网站下载您的操作系统的完整 ISO 并将其加载到驱动器中,然后将 /usr/share/applications 从 ISO 复制到您的系统。
-
reinstall
$ sudo dnf reinstall "$(rpm -qa)"
Flatpak 的亚洲字体问题
如果你遇到了游戏中无法显示亚洲字体的问题,这是因为 org.freedesktop.Platform 并没有包含合适的字体文件进去。首先尝试挂载你的本地字体:
$ flatpak run --filesystem=~/.local/share/fonts --filesystem=~/.config/fontconfig com.valvesoftware.Steam
如果上述命令不起作用,考虑动手 hack 一下:直接将字体文件复制进 org.freedesktop.Platform 的目录下以启用字体,例如
# replace ? with your version and hash
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/etc/fonts/conf.avail
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/etc/fonts/conf.d
/var/lib/flatpak/runtime/org.freedesktop.Platform/x86_64/?/?/files/share/fonts
SELinux policy for a systemd service
Check that the script is properly labeled as bin_t
$ sudo chcon -v -t bin_t /home/kurome/.opt/clash/clash_premium
FILTER RULES
~/.opt/rsync/backup-home:
+ /.config/
+ /.config/autostart/***
+ /.config/fontconfig/***
+ /.config/google-chrome/***
+ /.config/ibus/***
+ /.config/obsidian/***
+ /.config/Typora/***
+ /Documents/***
+ /.goldendict/***
+ /.local/
+ /.local/bin/***
+ /.local/share
+ /.local/share/applications/***
+ /.local/share/icons/***
+ /.local/share/TelegramDesktop/***
+ /Music/***
+ /.opt/***
+ /.ssh/***
+ /Templates/***
- /**
-
Using Rsync filter to include/exclude files
this won’t work:
+ /some/path/this-file-will-not-be-found + /file-is-included - *this set of rules works fine:
+ /some/ + /some/path/ + /some/path/this-file-is-found + /file-also-included - * -
exclude all directories except a few
$ cat filter.txt + /include_this_dir/ + /include_this_dir/** + /include_that_dir/ + /include_that_dir/** - /** $ rsync -av --dry-run --filter="merge filter.txt" source_dir/ dest_dir/You can reduce it further with three “*”, like
+ /include_this_dir/***, which means+ /include_this_dir/+/include_this_dir/**
~/.local/bin/backup-home:
#!/bin/bash
set -o errexit
set -o nounset
set -o pipefail
readonly SOURCE_DIR=/home/kurome/
readonly BACKUP_DIR="$(findmnt -nr -o target -S /dev/mapper/luks-5277e33d-604f-4c1e-bc8c-40c14544614e)/Backup/HomeData"
readonly DATETIME="$(date '+%Y-%m-%d_%H:%M:%S')"
readonly BACKUP_PATH="${BACKUP_DIR}/${DATETIME}"
readonly LATEST_LINK="${BACKUP_DIR}/latest"
rsync -av \
--delete "${SOURCE_DIR}/" \
--link-dest "${LATEST_LINK}" \
--filter="merge /home/kurome/.opt/rsync/backup-home" \
"${BACKUP_PATH}"
rm -rf "${LATEST_LINK}"
ln -s "${BACKUP_PATH}" "${LATEST_LINK}"
Fedora Questions
Cannot open acess to console, the root account is locked…
先是添加一个 LV 到 /etc/fstab,结果开机报错,原因是写错了:
Time out ...Dependency failed for ...
结束后就 Cannot open acess to console, the root account is locked,什么也干不了,只能强制关机。
解决方案是重启进入 Fedora Live CD,挂载 root,修改 /etc/fstab。但是无法挂载,挂载的是 Fedora Live CD 的 root,我 TM 佛了,原因应该是这两个名一模一样,Live CD 覆盖了 root。最后是用 Ubntu Live CD 解决。
这告诉我们,不要只有一个 Live CD。这还告诉我们,先找自己的原因才能有耐心去解决问题。
dmesg-x86/cpu: SGX disabled by BIOS
snd_hda_codec_hdmi hdaudioC0D2: Monitor plugged-in, Failed to power up codec ret=[-13]
set Kernel parameters,要使改变在重启后仍生效,您可以手动编辑 /boot/grub/grub.cfg。对于初学者,建议编辑 /etc/default/grub 并将您的内核选项添加至 GRUB_CMDLINE_LINUX_DEFAULT 行:
GRUB_CMDLINE_LINUX_DEFAULT="snd_hda_codec_hdmi.enable_silent_stream=0"
然后重新生成 grub.cfg 文件:
# grub2grub-mkconfig2 -o /boot/grub2/grub.cfg
为什么 Linus Torvalds 用 Fedora
- 2008:linus对发行版的要求是"易安装,比较贴近上游"即可(滚动+少折腾”)。
- 2010年的时候,他指出了Fedora 14的一个bug。
- 2011年Fedora 15换Gnome3作为默认DE了,Linus直言"unholy mess" ,然后转投XFCE。
- 2011年末,Linus提出并修补了openSUSE中Xorg的一个严重bug。
- 2013年5月:Linus尝试将自己手头的MacBook Air装上Linux,把几个大的发行版全部都试了一遍。发现只有Fedora能正常工作。
- 之后的所有消息就是各种fedora了
代理后为什么 ping 不通
问题:
设置了http_proxy和https_proxy在.bashrc文件里,firefox可以上网了。ping外网能够解析域名,但ping不通
解答:
首先提一个问题,为什么我们要用代理服务器上网?
那是因为如果不用代理服务器,我们访问的website 被blocked,最简单的方式就是在一个大型防火墙上执行: deny website IP。
而使用代理服务器,无非是用代理服务器的IP作为目的IP,把用户的HTTP、HTTPS封装在TCP上,这样途径防火墙时,由于目的IP不在blocked IP 之列,所以被放行,这样我们就可以浏览一些被blocked 的网页。
但是一般代理服务器并不为UDP/ICMP服务,最多为TCP服务,所以你ping website 时,代理服务器并没有介入,因为Ping是ICMP报文,那就意味着你的ping包的目的IP就是被blocked IP地址,很显然无法正常通过,全被丢了。
Fedora安装Chrome后显示“您的浏览器由所属组织管理”
I finally got a chance to look into this today, and I don’t think it’s as alarming as this BZ makes it sound. Yes, Chrome (over-)states that it is “Managed by your organization”. Clicking on that links to https://support.google.com/chrome/answer/9281740 which lists the things a managed system can do. However, if you read just a few sentences further, it tells you how to view exactly which settings your administrator has enabled, which in turn has links to the descriptions of what those features are. As clearly linked there, the only settings we’ve enabled is “This browser can negotiate authentication with *.fedoraproject.org”.
So, I’m inclined to say that while the initial reading page might lead a user to be slightly concerned, I don’t feel that the situation is particularly dire. They can always just read content in the links.
In the worst case, if someone really doesn’t want to have that message appear, they can just dnf remove fedora-chromium-config.
This package is used to install customizations for Chromium/Chrome that are recommended by Fedora, including a user-agent string identifying the system as Fedora.
It includes a GSSAPI configuration that enables access to many Fedora Project services. To add support for other domains, replace the symlink /etc/chromium/policies/managed/00_gssapi.json with your own content. (upstream)
difference between docker attach and docker exec
There was a commit PR which added to the doc:
Note: This command (
attach) is not for running a new process in a container. See:docker exec.
The answer to “Docker. How to get bash\ssh inside runned container (run -d)?” illustrates the difference:
(docker >= 1.3) If we use
docker attach, we can use only one instance of shell. So if we want to open new terminal with new instance of container’s shell, we just need to rundocker execif the docker container was started using
/bin/bashcommand, you can access it using attach, if not then you need to execute the command to create a bash instance inside the container usingexec.
As mentioned in this issue:
- Attach isn’t for running an extra thing in a container, it’s for attaching to the running process.
- “
docker exec” is specifically for running new things in a already started container, be it a shell or some other process.
The same issue adds:
While
attachis not well named, particularly because of the LXC commandlxc-attach(which is more akindocker exec <container> /bin/sh, but LXC specific), it does have a specific purpose of literally attaching you to the process Docker started. Depending on what the process is the behavior may be different, for instance attaching to/bin/bashwill give you a shell, but attaching to redis-server will be like you’d just started redis directly without daemonizing.
Error syncing passwords
Error: MergeDataAndStartSyncing@../../components/password_manager/core/browser/sync/password_syncable_service.cc:190, datatype error was encountered: Failed to get passwords from store.
The problem was solved by deleting ‘Login Data’ and ‘Login Data-journal’ in the profile.
$ rm -rf ~/.config/google-chrome/Default/Login\ Data*
The <profile> part can be found in the Profile Path on the chrome://version page.
Gnome Boxes with ssh
GNOME Boxes does not expose guests to SSH into. You are expected to have SPICE guest additions installed on the guest to be able:
- to copy and paste text with a shared clipboard between the host and the guest and
- to drag and drop files into the guest.
This approach is supposed to be intuitively comprehensible for unsophisticated users.
Where do packages installed with DNF get stored?
With APT (Ubuntu), downloaded packages are stored at: /var/cache/apt/archives
DNF stores downloaded packages and metadata in /var/cache/dnf, in various per-repository subdirectories.
How do I scan for viruses with ClamAV?
RHEL
RHEL Developer Subscription
Need to log in to download RHEL.
下载的时候会断,有时候甚至下载到 99% 都会断,所以最好是用专门的、支持断点续传的软件(如 aria2)下载。同时最好不要关闭浏览器,特别是保留redhat官网登录状态,如果关闭了就需要重新登录,根本没有保存登录状态选项。
怎样使用 Red Hat Subscription Manager (RHSM) 将系统注册到红帽客户门户网站?
# subscription-manager register --username <username> --password <password> --auto-attach
注意!是用户名而不是邮箱!
配置 Red Hat Enterprise Linux 8 中基本系统设置的指南
EPEL & RPMFusion
EPEL的全称叫 Extra Packages for Enterprise Linux 。EPEL是由 Fedora 社区打造,为 RHEL 及衍生发行版如 CentOS、Scientific Linux 等提供高质量软件包的项目。装上了 EPEL之后,就相当于添加了一个第三方源。
# subscription-manager repos --enable codeready-builder-for-rhel-9-$(arch)-rpms
# dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm
如果你知道rpmfusion.org的话,拿 rpmfusion 做比较还是很恰当的,rpmfusion 主要为桌面发行版提供大量rpm包(只有开源驱动才能进官方源,想要闭源驱动装rpmfusion),而EPEL则为服务器版本提供大量的rpm包,而且大多数rpm包在官方 repository 中是找不到的。
继上面安装 epel 后安装 RPMFusion:
# dnf install --nogpgcheck https://mirrors.rpmfusion.org/free/el/rpmfusion-free-release-$(rpm -E %rhel).noarch.rpm https://mirrors.rpmfusion.org/nonfree/el/rpmfusion-nonfree-release-$(rpm -E %rhel).noarch.rpm
使用 BFSU MIRROR
$ sudo dnf install --nogpgcheck https://mirrors.bfsu.edu.cn/rpmfusion/free/el/rpmfusion-free-release-$(rpm -E %rhel).noarch.rpm https://mirrors.bfsu.edu.cn/rpmfusion/nonfree/el/rpmfusion-nonfree-release-$(rpm -E %rhel).noarch.rpm -y
注意:RHEL、CentOS 及替代(Rocky、AlmaLinux、OracleLinux)等服务器版本,很多常见桌面应用是没有在源里面提供的(不论时官方源还是额外的第三方源),因此需要手动管理了。
Remi’s RPM repository
向Fedora和Enterprise Linux(RHEL、CentOS、Oracle、Scientific Linux,…)用户提供 最新版本的**PHP**堆栈、全功能和一些其他软件。它主要包含:
- 我也在 Fedora 中维护的包
- Fedora 开发版中可用的软件包的反向移植
- 一些与 Fedora 政策不兼容的软件包
- 在提交到 Fedora 存储库之前正在处理的一些包
- (几乎)香草版本
这与 Enterprise Linux的向后移植修复策略相去甚远。
GetPageSpeed RHEL Packages Repository
We have by far the largest RPM repository with dynamic stable NGINX modules and VMODs for Varnish 4.1 and 6.0 LTS. If you want to install nginx, Varnish and lots of useful modules for them, this is your one stop repository to get all performance related software.
ELRepo Project
The ELRepo Project focuses on hardware related packages to enhance your experience with Enterprise Linux. This includes filesystem drivers, graphics drivers, network drivers, sound drivers, webcam and video drivers.
HTML5/MP4 videos
Install EPEL and RPMFusion.
Then yum install ffmpeg and you should be all set. The way Firefox works with this is it links to the avcodec/avformat (one of those two) libraries at launch, and those are provided by the ffmpeg project. ffmpeg in turn will grab the necessary codecs’ libraries it was compiled with (x264, vp9, x265, etc) and install them on your system.
Kdump
Kdump是一种基于kexec的Linux内核崩溃捕获机制,简单来说系统启动时会预留一块内存,当系统崩溃调用命令kexec(kdump kernel)在预留的内存中启动kdump内核,该内核会将此时内存中的所有运行状态和数据信息收集到一个coredump文件中以便后续分析调试。
Qemu on rhel
The main QEMU executable is now /usr/libexec/qemu-kvm
VNC applications
Some Free/Libre software supporting VNC/RFB protocol or Remote Desktop Protocol (RDP):
- noVNC (GitHub) is a browser-based app supporting many VNC features but no RDP.
- rdesktop (GitHub)
- FreeRDP (GitHub) Fork of rdesktop to clean the code, support Seamless Windows (RDP6)…
- Remmina (GitHub) Based on FreeRDP replaced tsclient as Ubuntu’s default RD client (2011)
- Vinagre Default GNOME VNC client supporting RDP since 2012
- Ulteo Open Virtual Desktop (guide to get source code)
VirtualBox has a built-in vRDP protocol that can be used to access GNU/Linux remote desktops (Linux distro usually lacks a RDP server). The vRDP protocol is compatible with all RDP clients. However, the proprietary VirtualBox Extension Pack is required.
See also this good comparison of remote desktop software (Wikipedia).
TechRadar has also published an interesting article on this purpose:
Best Linux remote desktop clients: Top 5 RDC in 2018 By Mayank Sharma, January 2018 We cover all the ins-and-outs of remote viewing
Remote control features
- TigerVNC 3/5
- RealVNC 4/5 Top
- Remmina 4/5 Top
- Vinagre 3/5
- TightVNC 3/5
Multimedia performance
- TigerVNC 4/5 Top
- RealVNC 4/5 Top
- Remmina 3/5
- Vinagre 4/5 Top
- TightVNC 2/5
Interface and usability
- TigerVNC 3/5
- RealVNC 3/5
- Remmina 3/5
- Vinagre 3/5
- TightVNC 3/5
Documentation and support
- TigerVNC 2/5
- RealVNC 5/5 Top
- Remmina 3/5
- Vinagre 2/5
- TightVNC 2/5
Server and protocol support
- TigerVNC 2/5
- RealVNC 4/5 Top
- Remmina 3/5
- Vinagre 3/5
- TightVNC 1/5
Configurable parameters
- TigerVNC 2/5
- RealVNC 4/5 Top
- Remmina 3/5
- Vinagre 2/5
- TightVNC 2/5
Connection flexibility
- TigerVNC 4/5 Top
- RealVNC 3/5
- Remmina 4/5 Top
- Vinagre 2/5
- TightVNC 4/5 Top
Final verdict
Rocky
NJU Mirror
$ sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.nju.edu.cn/rocky|g' \
-i.bak \
/etc/yum.repos.d/Rocky-*.repo
$ dnf makecache
EPEL
首先从CentOS Extras这个源(本镜像站也有镜像)里安装epel-release:
yum install epel-release
修改/etc/yum.repos.d/epel.repo,将mirrorlist和metalink开头的行注释掉。
接下来,取消注释这个文件里baseurl开头的行,并将其中的http://download.fedoraproject.org/pub替换成https://mirrors.bfsu.edu.cn。
可以用如下命令自动替换:(来自 https://github.com/tuna/issues/issues/687)
$ sed -e 's!^metalink=!#metalink=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!//download\.fedoraproject\.org/pub!//mirrors.bfsu.edu.cn!g' \
-e 's!//download\.example/pub!//mirrors.bfsu.edu.cn!g' \
-e 's!http://mirrors!https://mirrors!g' \
-i /etc/yum.repos.d/epel*.repo
CentOS
关于多线程
概述
每个正在系统上运行的程序都是一个进程。每个进程包含一到N个线程。进程也可能是整个程序或者是部分程序的动态执行。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。线程是程序中一个单一的顺序控制流程。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文.多线程主要是为了节约CPU时间,发挥利用,根据具体情况而定. 线程的运行中需要使用计算机的内存资源和CPU。
同步多线程(SMT)是一种在一个CPU 的时钟周期内能够执行来自多个线程的指令的硬件多线程技术。本质上,同步多线程是一种将线程级并行处理(多CPU)转化为指令级并行处理(同一CPU)的方法。 同步多线程是单个物理处理器从多个硬件线程上下文同时分派指令的能力。同步多线程用于在商用环境中及为周期/指令(CPI)计数较高的工作负载创造性能优势。 处理器采用超标量结构,最适于以并行方式读取及运行指令。同步多线程使您可在同一处理器上同时调度两个应用程序,从而利用处理器的超标量结构性质。
超线程(HT, Hyper-Threading)是英特尔研发的一种技术,于2002年发布。通过此技术,英特尔实现在一个实体CPU中,提供两个逻辑线程。
其实可以将SMT和HT理解为一个技术。
Hyper-threading (officially called Hyper- ThreadingTechnology or HT Technology, and abbreviated as HTT orHT) is Intel’s proprietary simultaneous multithreading (SMT) implementation used to improve parallelization ofcomputations (doing multiple tasks at once) performed onx86 microprocessors.
来自 https://cn.bing.com/search?q=intel+ht&go=%E6%8F%90%E4%BA%A4&qs=ds&form=QBLHCN
与多进程的区别
“进程——资源分配的最小单位,线程——程序执行的最小单位”
实际应用中基本上都是“进程+线程”的结合方式,千万不要真的陷入一种非此即彼的误区。
| 对比维度 | 多进程 | 多线程 | 总结 |
|---|---|---|---|
| 数据共享、同步 | 数据共享复杂,需要用IPC;数据是分开的,同步简单 | 因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 | 各有优势 |
| 内存、CPU | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,CPU利用率高 | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 线程占优 |
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 | 适应于多核分布式 | 进程占优 |
- 需要注意:
1)需要频繁创建销毁的优先用线程
2)需要进行大量计算的优先使用线程
3)强相关的处理用线程,弱相关的处理用进程
一般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。当然这种划分方式不是一成不变的,也可以根据实际情况进行调整。
4)可能要扩展到多机分布的用进程,多核分布的用线程
5)都满足需求的情况下,用你最熟悉、最拿手的方式
来自 https://blog.csdn.net/lishenglong666/article/details/8557215
如何使用?
需要CPU、BIOS、操作系统、应用软件都支持多线程技术才可以。
支持多线程的CPU
Power CPU 支持的SMT技术:
Simultaneous multithreading (SMT) is a processor technology that allows multiple instruction streams (threads) to run concurrently on the same physical processor, improving overall throughput. To the operating system, each hardware thread is treated as an independent logical processor. Single-threaded (ST) execution mode is also supported.
来自 https://www.ibm.com/support/knowledgecenter/SSFHY8_6.2/reference/am5gr_f0106.html?view=embed
Intel CPU 支持的HT技术:
Intel® Hyper-Threading Technology (Intel® HT Technology) uses processor resources more efficiently, enabling multiple threads to run on each core. As a performance feature, it also increases processor throughput, improving overall performance on threaded software. Intel® HT Technology is available on the latest Intel® Core™ vPro™ processors, the Intel® Core™ processor family, the Intel® Core™ M processor family, and the Intel® Xeon® processor family. By combining one of these Intel® processors and chipsets with an operating system and BIOS supporting Intel® HT Technology.
SMT/HT支持情况
- Intel CPU : 2 Thread/Core
- Power9 CPU: 8 Thread /Core
- Sparc: 8 Thread /Core
RHEL7/CentOS7 & Intel CPU
BIOS 中修改SMT/HT 的设置,使用这种方式Enable或者Disable后,将永久生效,需要重启。
Hyper-Threading Technology BIOS Setup Options
For Intel® Desktop/Server Boards setup option location is the main menu of the BIOS setup program.
• Located on the same menu screen that already had Processor Type, Processor Speed, System Bus Speed, and other related processor fields.
• Setup Option Text
○ The field is called Hyper-Threading Technology.
• Setup Option Values
○ The setup option values are Enabled and Disabled.
• Setup Option Help Text
来自 <https://www.intel.com/content/www/us/en/support/articles/000007645/boards-and-kits/desktop-boards.html>
RHEL/CentOS操作系统中查看多线程情况:(更多信息:https://access.redhat.com/solutions/rhel-smt)
# lscpu | grep -e Socket -e Core -e Thread
Thread(s) per core: 2 # 线程数
Core(s) per socket: 6 # core 数量
Socket(s): 2
或者
# grep -H . /sys/devices/system/cpu/cpu*/topology/thread_siblings_list | sort -n -t ':' -k 2 -u
# 显示 /sys/devices/system/cpu/cpu0/topology/thread_siblings_list:0 # 表示HT关闭
# 显示 /sys/devices/system/cpu/cpu0/topology/thread_siblings_list:0-1 # 表示 HT 启用
操作系统层关闭多线程有几种办法:
- 方法一:使用
nosmt启动参数,需要新的x86 CPU,需要重启
# grubby --args=nosmt --update-kernel=DEFAULT
# grub2-mkconfig -o /boot/grub/grub.conf # 创建新的grub.conf
# reboot #重启
- 方法二:临时关闭,重启后失效
# echo off > /sys/devices/system/cpu/smt/control
/sys/devices/system/cpu/smt/control:
This file allows to read out the SMT control state and provides the
ability to disable or (re)enable SMT. The possible states are:
============== ===================================================
on SMT is supported by the CPU and enabled. All
logical CPUs can be onlined and offlined without
restrictions.
off SMT is supported by the CPU and disabled. Only
the so called primary SMT threads can be onlined
and offlined without restrictions. An attempt to
online a non-primary sibling is rejected
forceoff Same as 'off' but the state cannot be controlled.
Attempts to write to the control file are rejected.
notsupported The processor does not support SMT. It's therefore
not affected by the SMT implications of L1TF.
Attempts to write to the control file are rejected.
============== ===================================================
The possible states which can be written into this file to control SMT
state are:
- on
- off
- forceoff
/sys/devices/system/cpu/smt/active:
This file reports whether SMT is enabled and active, i.e. if on any
physical core two or more sibling threads are online.
AIX & Power
Power9 CPU默认支持8线程,使用smtctl命令可以查看和修改 smt级别。更多内容查看https://www.ibm.com/support/knowledgecenter/ssw_aix_72/com.ibm.aix.cmds5/smtctl.htm
- 查看
SMT level
smtctl
- 临时修改
SMT level, # 可以是1, 2, 4 or 8,重启后将恢复原来的smt level
smtctl -t 2 -w now
- 修改
SMT level永久生效,# 可以是1, 2, 4 or 8,完成后需要使用bosboot创建启动设备
smtctl -t 4 -w boot
bosboot -a # Creates complete boot image and device.
RHEL7 & Power
OpenPower CPU 默认支持4线程,安装RHEL后可以使用开源的工具 ppc64_cpu进行查看和修改多线程(更多查看 https://github.com/ibm-power-utilities/powerpc-utils)。
ppc64_cpu
---------
This allows users to set the smt state, smt-snooze-delay and other settings
on ppc64 processors. It also allows users to control the number of processor
cores which are online (not in the sleep state).
来自 <https://github.com/ibm-power-utilities/powerpc-utils>
1,查看 SMT level
ppc64_cpu --smt
2,修改 SMT 级别, # is 1, 2, 4 or on
ppc64_cpu --smt=#
3, 关闭 smt支持
ppc64_cpu --smt=off
其他
oracle数据库
Oracle Database 在12c之前windows平台下支持多线程,Unix和Linux只支持多进程模式。在Oracle Database 12c中,Oracle引入了多线程模式,允许在Windows平台之外的Unix、Linux系统使用多线程模式,结合多进程与多线程模式,Oracle可以改进进程管理与性能。
通过设置初始化参数threaded_execution,可以启用或关闭多线程模式,该参数缺省值为False,设置为TRUE启用12c的这个新特性:
SQL> show parameter threaded_exec
NAME TYPE VALUE
---
threaded_execution boolean FALSE
SQL> alter system set threaded_execution=true scope=spfile;
System altered.
该参数重新启动数据库后生效,但是注意,多线程模式,不支持操作系统认证,不能直接启动数据库,需要提供SYS的密码认证后方能启动数据库:
SQL> shutdown immediate;
SQL> startup
ORA-01017: invalid username/password; logon denied
# 需要通过用户名和密码登录数据库。
用ps -ef 检查一下进程/线程:
[oracle@enmocoredb dbs]$ ps -ef|grep ora_
oracle 27404 1 0 17:00 ? 00:00:00 ora_pmon_core
oracle 27406 1 0 17:00 ? 00:00:00 ora_psp0_core
oracle 27408 1 3 17:00 ? 00:00:05 ora_vktm_core
oracle 27412 1 0 17:00 ? 00:00:00 ora_u004_core
oracle 27418 1 0 17:00 ? 00:00:00 ora_u005_core
oracle 27424 1 0 17:00 ? 00:00:00 ora_dbw0_core
其中U<NNN>进程是共享线程的"容器进程",每个进程可以容纳100个线程。
来自 https://www.eygle.com/archives/2013/07/oracle_database_12c_multithreaded_model.html
连接热点
-
打开WIFI
ifconfig interface up -
查看所有可用的无线网络信号
iw wlp2s0 scan | grep SSID -
连接无线网
wpa_supplicant -B -i wlp2s0 -c <(wpa_passphrase "SSID" "passwd") -
分配IP地址
dhclient interface -
查看无线网卡地址信息,有ip地址表示网络连接成功
ifconfig interface
PPPOE (ADSL)拨号上网
-
安装拨号软件
dnf install rp-pppoe* ppp* -
设定
pppoe-setup -
拨号上网
pppoe-stoppppoe-start
安装中文输入法
-
安装 fcitx
dnf install fcitx-im fcitx-configtool fcitx-googlepinyin -
配置
$ nano ~/.xprofile # or ~/.bashrc export GTK_MODULE=fcitx export QT_IM_MODULE=fcitx export XMODIFIERS="@im=fcitx" -
fcitx 没图标:重装fcitx,在fcitx配置里关掉Kimpanel
关闭触摸板
$ dnf install xorg-x11-apps
synclient TouchpadOff=1 # 关闭
synclient TouchpadOff=0 # 开启
用 MTP 挂载手机
-
安装jmtpfs
dnf install jmtpfs -
查看手机 “busnum”和“devnum”
jmptfs -l -
建立挂载点
mkdir /media/dir -
挂载手机
jmtpfs -device=busnum,devnum /media/dir/
查找依赖
$ yum whatprovide package
$ dnf provides package
默认字体
CentOS 默认字体目录 /lib/kbd/consolefonts
纯命令行是不能使用系统之外的字体的。
CentOS Minimal + Xfce
base 源与 epel 源,使用用阿里镜像: https://developer.aliyun.com/mirror/
-
安装Xfce4,先安装 Xfce 可以保证不安装多余的包
dnf group listdnf groupinstall Xfce -
安装 X Window system
dnf groupinstall "X Window system" -
验证
systemctl isolate graphical.target -
设置
# 设置成命令模式systemctl set-default multi-user.target # 设置成图形模式systemctl set-default graphical.target -
安装中文字体和中文输入法楷体字体
dnf install cjkuni-ukai-fonts -
输入法需要安装如下包:
- ibus, 这个包里有ibus-daemon这个平台服务器程序和ibus这个配置助手。
- ibus-libpinyin, 这个是ibus平台下具体的拼音输入法。
- im-chooser,这个是输入法平台选择助手程序。
- 执行im-chooser,选择输入法平台和输入法。重新登录系统。
-
xfce 主题
- 网站:xfce-look.org
- 主题目录:
/usr/share/themes或~/.themes - 图标鼠标目录:
/usr/share/icons或~/.icons - 壁纸:
/usr/share/background,/usr/share/wallpapers - Plank
SELinux
SELinux 初探
從進入了 CentOS 5.x 之後的 CentOS 版本中 (當然包括 CentOS 7),SELinux 已經是個非常完備的核心模組了!尤其 CentOS 提供了很多管理 SELinux 的指令與機制, 因此在整體架構上面是單純且容易操作管理的!所以,在沒有自行開發網路服務軟體以及使用其他第三方協力軟體的情況下, 也就是全部使用 CentOS 官方提供的軟體來使用我們伺服器的情況下,建議大家不要關閉 SELinux 了喔! 讓我們來仔細的玩玩這傢伙吧!
什麼是 SELinux
什麼是 SELinux 呢?其實他是『 Security Enhanced Linux 』的縮寫,字面上的意義就是安全強化的 Linux 之意!那麼所謂的『安全強化』是強化哪個部分? 是網路資安還是權限管理?底下就讓我們來談談吧!
當初設計的目標:避免資源的誤用
SELinux 是由美國國家安全局 (NSA) 開發的,當初開發這玩意兒的目的是因為很多企業界發現, 通常系統出現問題的原因大部分都在於『內部員工的資源誤用』所導致的,實際由外部發動的攻擊反而沒有這麼嚴重。 那麼什麼是『員工資源誤用』呢?舉例來說,如果有個不是很懂系統的系統管理員為了自己設定的方便,將網頁所在目錄 /var/www/html/ 的權限設定為 drwxrwxrwx 時,你覺得會有什麼事情發生?
現在我們知道所有的系統資源都是透過程序來進行存取的,那麼 /var/www/html/ 如果設定為 777 , 代表所有程序均可對該目錄存取,萬一你真的有啟動 WWW 伺服器軟體,那麼該軟體所觸發的程序將可以寫入該目錄, 而該程序卻是對整個 Internet 提供服務的!只要有心人接觸到這支程序,而且該程序剛好又有提供使用者進行寫入的功能, 那麼外部的人很可能就會對你的系統寫入些莫名其妙的東西!那可真是不得了!一個小小的 777 問題可是大大的!
為了控管這方面的權限與程序的問題,所以美國國家安全局就著手處理作業系統這方面的控管。 由於 Linux 是自由軟體,程式碼都是公開的,因此她們便使用 Linux 來作為研究的目標, 最後更將研究的結果整合到 Linux 核心裡面去,那就是 SELinux 啦!所以說, SELinux 是整合到核心的一個模組喔! 更多的 SELinux 相關說明可以參考:http://www.nsa.gov/research/selinux/
這也就是說:其實 SELinux 是在進行程序、檔案等細部權限設定依據的一個核心模組! 由於啟動網路服務的也是程序,因此剛好也能夠控制網路服務能否存取系統資源的一道關卡! 所以,在講到 SELinux 對系統的存取控制之前,我們得先來回顧一下之前談到的系統檔案權限與使用者之間的關係。 因為先談完這個你才會知道為何需要 SELinux 的啦!
傳統的檔案權限與帳號關係:自主式存取控制, DAC
我們通过Linux 帳號管理與 ACL 權限設定的內容,知道系統的帳號主要分為系統管理員 (root) 與一般用戶,而這兩種身份能否使用系統上面的檔案資源則與 rwx 的權限設定有關。 不過你要注意的是,各種權限設定對 root 是無效的。因此,當某個程序想要對檔案進行存取時, 系統就會根據該程序的擁有者/群組,並比對檔案的權限,若通過權限檢查,就可以存取該檔案了。
這種存取檔案系統的方式被稱為『自主式存取控制 (Discretionary Access Control, DAC)』,基本上,就是依據程序的擁有者與檔案資源的 rwx 權限來決定有無存取的能力。 不過這種 DAC 的存取控制有幾個困擾,那就是:
- root 具有最高的權限:如果不小心某支程序被有心人士取得, 且該程序屬於 root 的權限,那麼這支程序就可以在系統上進行任何資源的存取!真是要命!
- 使用者可以取得程序來變更檔案資源的存取權限:如果你不小心將某個目錄的權限設定為 777 ,由於對任何人的權限會變成 rwx ,因此該目錄就會被任何人所任意存取!
這些問題是非常嚴重的!尤其是當你的系統是被某些漫不經心的系統管理員所掌控時!他們甚至覺得目錄權限調為 777 也沒有什麼了不起的危險哩…
以政策規則訂定特定程序讀取特定檔案:委任式存取控制, MAC
現在我們知道 DAC 的困擾就是當使用者取得程序後,他可以藉由這支程序與自己預設的權限來處理他自己的檔案資源。 萬一這個使用者對 Linux 系統不熟,那就很可能會有資源誤用的問題產生。為了避免 DAC 容易發生的問題,因此 SELinux 導入了委任式存取控制 (Mandatory Access Control, MAC) 的方法!
委任式存取控制 (MAC) 有趣啦!他可以針對特定的程序與特定的檔案資源來進行權限的控管! 也就是說,即使你是 root ,那麼在使用不同的程序時,你所能取得的權限並不一定是 root , 而得要看當時該程序的設定而定。如此一來,我們針對控制的『主體』變成了『程序』而不是使用者喔! 此外,這個主體程序也不能任意使用系統檔案資源,因為每個檔案資源也有針對該主體程序設定可取用的權限! 如此一來,控制項目就細的多了!但整個系統程序那麼多、檔案那麼多,一項一項控制可就沒完沒了! 所以 SELinux 也提供一些預設的政策 (Policy) ,並在該政策內提供多個規則 (rule) ,讓你可以選擇是否啟用該控制規則!
在委任式存取控制的設定下,我們的程序能夠活動的空間就變小了!舉例來說, WWW 伺服器軟體的達成程序為 httpd 這支程式, 而預設情況下, httpd 僅能在 /var/www/ 這個目錄底下存取檔案,如果 httpd 這個程序想要到其他目錄去存取資料時, 除了規則設定要開放外,目標目錄也得要設定成 httpd 可讀取的模式 (type) 才行喔!限制非常多! 所以,即使不小心 httpd 被 cracker 取得了控制權,他也無權瀏覽 /etc/shadow 等重要的設定檔喔!
簡單的來說,針對 Apache 這個 WWW 網路服務使用 DAC 或 MAC 的結果來說,兩者間的關係可以使用下圖來說明。 底下這個圖示取自 Red Hat 訓練教材,真的是很不錯~所以被鳥哥借用來說明一下!
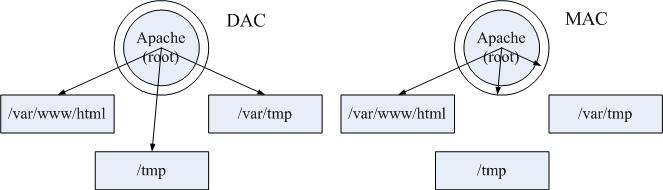
左圖是沒有 SELinux 的 DAC 存取結果,apache 這隻 root 所主導的程序,可以在這三個目錄內作任何檔案的新建與修改~ 相當麻煩~右邊則是加上 SELinux 的 MAC 管理的結果,SELinux 僅會針對 Apache 這個『 process 』放行部份的目錄, 其他的非正規目錄就不會放行給 Apache 使用!因此不管你是誰,就是不能穿透 MAC 的框框!這樣有比較了解乎?
SELinux 的運作模式
再次的重複說明一下,SELinux 是透過 MAC 的方式來控管程序,他控制的主體是程序, 而目標則是該程序能否讀取的『檔案資源』!所以先來說明一下這些咚咚的相關性啦!
-
主體 (Subject): SELinux 主要想要管理的就是程序,因此你可以將『主體』跟本章談到的 process 劃上等號;
-
目標 (Object): 主體程序能否存取的『目標資源』一般就是檔案系統。因此這個目標項目可以等檔案系統劃上等號;
-
政策 (Policy):
由於程序與檔案數量龐大,因此 SELinux 會依據某些服務來制訂基本的存取安全性政策。這些政策內還會有詳細的規則 (rule) 來指定不同的服務開放某些資源的存取與否。在目前的 CentOS 7.x 裡面僅有提供三個主要的政策,分別是:
- targeted:針對網路服務限制較多,針對本機限制較少,是預設的政策;
- minimum:由 target 修訂而來,僅針對選擇的程序來保護!
- mls:完整的 SELinux 限制,限制方面較為嚴格。
建議使用預設的 targeted 政策即可。
-
安全性本文 (security context): 我們剛剛談到了主體、目標與政策面,但是主體能不能存取目標除了政策指定之外,主體與目標的安全性本文必須一致才能夠順利存取。 這個安全性本文 (security context) 有點類似檔案系統的 rwx 啦!安全性本文的內容與設定是非常重要的! 如果設定錯誤,你的某些服務(主體程序)就無法存取檔案系統(目標資源),當然就會一直出現『權限不符』的錯誤訊息了!
由於 SELinux 重點在保護程序讀取檔案系統的權限,因此我們將上述的幾個說明搭配起來,繪製成底下的流程圖,比較好理解:
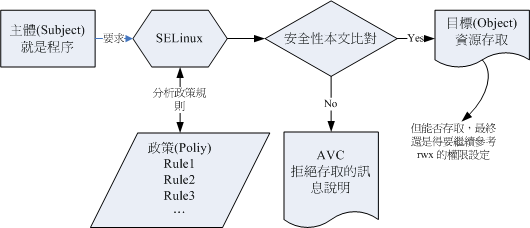
上圖的重點在『主體』如何取得『目標』的資源存取權限! 由上圖我們可以發現,(1)主體程序必須要通過 SELinux 政策內的規則放行後,就可以與目標資源進行安全性本文的比對, (2)若比對失敗則無法存取目標,若比對成功則可以開始存取目標。問題是,最終能否存取目標還是與檔案系統的 rwx 權限設定有關喔!如此一來,加入了 SELinux 之後,出現權限不符的情況時,你就得要一步一步的分析可能的問題了!
安全性本文 (Security Context)
CentOS 7.x 的 target 政策已經幫我們制訂好非常多的規則了,因此你只要知道如何開啟/關閉某項規則的放行與否即可。 那個安全性本文比較麻煩!因為你可能需要自行設定檔案的安全性本文呢!為何需要自行設定啊? 舉例來說,你不也常常進行檔案的 rwx 的重新設定嗎?這個安全性本文你就將他想成 SELinux 內必備的 rwx 就是了!這樣比較好理解啦。
安全性本文存在於主體程序中與目標檔案資源中。程序在記憶體內,所以安全性本文可以存入是沒問題。 那檔案的安全性本文是記錄在哪裡呢?事實上,安全性本文是放置到檔案的 inode 內的,因此主體程序想要讀取目標檔案資源時,同樣需要讀取 inode , 在 inode 內就可以比對安全性本文以及 rwx 等權限值是否正確,而給予適當的讀取權限依據。
那麼安全性本文到底是什麼樣的存在呢?我們先來看看 /root 底下的檔案的安全性本文好了。 觀察安全性本文可使用『 ls -Z 』去觀察如下:(注意:你必須已經啟動了 SELinux 才行!若尚未啟動,這部份請稍微看過一遍即可。底下會介紹如何啟動 SELinux 喔!)
# 先來觀察一下 root 家目錄底下的『檔案的 SELinux 相關資訊』
[root@study ~]# ls -Z
-rw-------. root root system_u:object_r:admin_home_t:s0 anaconda-ks.cfg
-rw-r--r--. root root system_u:object_r:admin_home_t:s0 initial-setup-ks.cfg
-rw-r--r--. root root unconfined_u:object_r:admin_home_t:s0 regular_express.txt
# 上述特殊字體的部分,就是安全性本文的內容!鳥哥僅列出數個預設的檔案而已,
# 本書學習過程中所寫下的檔案則沒有列在上頭喔!
如上所示,安全性本文主要用冒號分為三個欄位,這三個欄位的意義為:
Identify:role:type
身份識別:角色:類型
這三個欄位的意義仔細的說明一下吧:
-
身份識別 (Identify):
相當於帳號方面的身份識別!主要的身份識別常見有底下幾種常見的類型:
-
unconfined_u:不受限的用戶,也就是說,該檔案來自於不受限的程序所產生的!一般來說,我們使用可登入帳號來取得 bash 之後, 預設的 bash 環境是不受 SELinux 管制的~因為 bash 並不是什麼特別的網路服務!因此,在這個不受 SELinux 所限制的 bash 程序所產生的檔案, 其身份識別大多就是 unconfined_u 這個『不受限』用戶囉!
-
system_u:系統用戶,大部分就是系統自己產生的檔案囉!
基本上,如果是系統或軟體本身所提供的檔案,大多就是 system_u 這個身份名稱,而如果是我們用戶透過 bash 自己建立的檔案,大多則是不受限的 unconfined_u 身份~如果是網路服務所產生的檔案,或者是系統服務運作過程產生的檔案,則大部分的識別就會是 system_u 囉!
因為鳥哥這邊教大家使用文字界面來產生許多的資料,因此你看上面的三個檔案中,系統安裝主動產生的 anaconda-ks.cfs 及 initial-setup-ks.cfg 就會是 system_u,而我們自己從網路上面抓下來的 regular_express.txt 就會是 unconfined_u 這個識別啊!
-
-
角色 (Role):
透過角色欄位,我們可以知道這個資料是屬於程序、檔案資源還是代表使用者。一般的角色有:
-
object_r:代表的是檔案或目錄等檔案資源,這應該是最常見的囉;
-
system_r:代表的就是程序啦!不過,一般使用者也會被指定成為 system_r 喔!
你也會發現角色的欄位最後面使用『 _r 』來結尾!因為是 role 的意思嘛!
-
-
類型 (Type) (最重要!):
在預設的 targeted 政策中, Identify 與 Role 欄位基本上是不重要的!重要的在於這個類型 (type) 欄位! 基本上,一個主體程序能不能讀取到這個檔案資源,與類型欄位有關!而類型欄位在檔案與程序的定義不太相同,分別是:
-
type:在檔案資源 (Object) 上面稱為類型 (Type);
-
domain:在主體程序 (Subject) 則稱為領域 (domain) 了!
domain 需要與 type 搭配,則該程序才能夠順利的讀取檔案資源啦!
-
程序與檔案 SELinux type 欄位的相關性
那麼這三個欄位如何利用呢?首先我們來瞧瞧主體程序在這三個欄位的意義為何!透過身份識別與角色欄位的定義, 我們可以約略知道某個程序所代表的意義喔!先來動手瞧一瞧目前系統中的程序在 SELinux 底下的安全本文為何?
# 再來觀察一下系統『程序的 SELinux 相關資訊』
[root@study ~]# ps -eZ
LABEL PID TTY TIME CMD
system_u:system_r:init_t:s0 1 ? 00:00:03 systemd
system_u:system_r:kernel_t:s0 2 ? 00:00:00 kthreadd
system_u:system_r:kernel_t:s0 3 ? 00:00:00 ksoftirqd/0
.....(中間省略).....
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 31513 ? 00:00:00 sshd
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 31535 pts/0 00:00:00 bash
# 基本上程序主要就分為兩大類,一種是系統有受限的 system_u:system_r,另一種則可能是用戶自己的,
# 比較不受限的程序 (通常是本機用戶自己執行的程式),亦即是 unconfined_u:unconfined_r 這兩種!
基本上,這些對應資料在 targeted 政策下的對應如下:
| 身份識別 | 角色 | 該對應在 targeted 的意義 |
|---|---|---|
| unconfined_u | unconfined_r | 一般可登入使用者的程序囉!比較沒有受限的程序之意!大多數都是用戶已經順利登入系統 (不論是網路還是本機登入來取得可用的 shell) 後, 所用來操作系統的程序!如 bash, X window 相關軟體等。 |
| system_u | system_r | 由於為系統帳號,因此是非交談式的系統運作程序,大多數的系統程序均是這種類型! |
但就如上所述,在預設的 target 政策下,其實最重要的欄位是類型欄位 (type), 主體與目標之間是否具有可以讀寫的權限,與程序的 domain 及檔案的 type 有關!這兩者的關係我們可以使用 crond 以及他的設定檔來說明! 亦即是 /usr/sbin/crond, /etc/crontab, /etc/cron.d 等檔案來說明。 首先,看看這幾個咚咚的安全性本文內容先:
# 1. 先看看 crond 這個『程序』的安全本文內容:
[root@study ~]# ps -eZ | grep cron
system_u:system_r:crond_t:s0-s0:c0.c1023 1338 ? 00:00:01 crond
system_u:system_r:crond_t:s0-s0:c0.c1023 1340 ? 00:00:00 atd
# 這個安全本文的類型名稱為 crond_t 格式!
# 2. 再來瞧瞧執行檔、設定檔等等的安全本文內容為何!
[root@study ~]# ll -Zd /usr/sbin/crond /etc/crontab /etc/cron.d
drwxr-xr-x. root root system_u:object_r:system_cron_spool_t:s0 /etc/cron.d
-rw-r--r--. root root system_u:object_r:system_cron_spool_t:s0 /etc/crontab
-rwxr-xr-x. root root system_u:object_r:crond_exec_t:s0 /usr/sbin/crond
當我們執行 /usr/sbin/crond 之後,這個程式變成的程序的 domain 類型會是 crond_t 這一個~而這個 crond_t 能夠讀取的設定檔則為 system_cron_spool_t 這種的類型。因此不論 /etc/crontab, /etc/cron.d 以及 /var/spool/cron 都會是相關的 SELinux 類型 (/var/spool/cron 為 user_cron_spool_t)。 文字看起來不太容易了解,我們使用圖示來說明這幾個東西的關係!
上圖的意義我們可以這樣看的:
- 首先,我們觸發一個可執行的目標檔案,那就是具有 crond_exec_t 這個類型的 /usr/sbin/crond 檔案;
- 該檔案的類型會讓這個檔案所造成的主體程序 (Subject) 具有 crond 這個領域 (domain), 我們的政策針對這個領域已經制定了許多規則,其中包括這個領域可以讀取的目標資源類型;
- 由於 crond domain 被設定為可以讀取 system_cron_spool_t 這個類型的目標檔案 (Object), 因此你的設定檔放到 /etc/cron.d/ 目錄下,就能夠被 crond 那支程序所讀取了;
- 但最終能不能讀到正確的資料,還得要看 rwx 是否符合 Linux 權限的規範!
上述的流程告訴我們幾個重點,第一個是政策內需要制訂詳細的 domain/type 相關性;第二個是若檔案的 type 設定錯誤, 那麼即使權限設定為 rwx 全開的 777 ,該主體程序也無法讀取目標檔案資源的啦!不過如此一來, 也就可以避免使用者將他的家目錄設定為 777 時所造成的權限困擾。
真的是這樣嗎?沒關係~讓我們來做個測試練習吧!就是,萬一你的 crond 設定檔的 SELinux 並不是 system_cron_spool_t 時, 該設定檔真的可以順利的被讀取運作嗎?來看看底下的範例!
# 1. 先假設你因為不熟的緣故,因此是在『root 家目錄』建立一個如下的 cron 設定:
[root@study ~]# vim checktime
10 * * * * root sleep 60s
# 2. 檢查後才發現檔案放錯目錄了,又不想要保留副本,因此使用 mv 移動到正確目錄:
[root@study ~]# mv checktime /etc/cron.d
[root@study ~]# ll /etc/cron.d/checktime
-rw-r--r--. 1 root root 27 Aug 7 18:41 /etc/cron.d/checktime
# 仔細看喔,權限是 644 ,確定沒有問題!任何程序都能夠讀取喔!
# 3. 強制重新啟動 crond ,然後偷看一下登錄檔,看看有沒有問題發生!
[root@study ~]# systemctl restart crond
[root@study ~]# tail /var/log/cron
Aug 7 18:46:01 study crond[28174]: ((null)) Unauthorized SELinux context=system_u:system_r:
system_cronjob_t:s0-s0:c0.c1023 file_context=unconfined_u:object_r:admin_home_t:s0
(/etc/cron.d/checktime)
Aug 7 18:46:01 study crond[28174]: (root) FAILED (loading cron table)
# 上面的意思是,有錯誤!因為原本的安全本文與檔案的實際安全本文無法搭配的緣故!
您瞧瞧~從上面的測試案例來看,我們的設定檔確實沒有辦法被 crond 這個服務所讀取喔!而原因在登錄檔內就有說明, 主要就是來自 SELinux 安全本文 (context) type 的不同所致喔!沒辦法讀就沒辦法讀,先放著~後面再來學怎麼處理這問題吧!
SELinux 三種模式的啟動、關閉與觀察
並非所有的 Linux distributions 都支援 SELinux 的,所以你必須要先觀察一下你的系統版本為何! 鳥哥這裡介紹的 CentOS 7.x 本身就有支援 SELinux 啦!所以你不需要自行編譯 SELinux 到你的 Linux 核心中! 目前 SELinux 依據啟動與否,共有三種模式,分別如下:
- enforcing:強制模式,代表 SELinux 運作中,且已經正確的開始限制 domain/type 了;
- permissive:寬容模式:代表 SELinux 運作中,不過僅會有警告訊息並不會實際限制 domain/type 的存取。這種模式可以運來作為 SELinux 的 debug 之用;
- disabled:關閉,SELinux 並沒有實際運作。
我們前面不是談過主體程序需要經過政策規則、安全本文比對之後,加上 rwx 的權限規範, 若一切合理才會讓程序順利的讀取檔案嗎?那麼這個 SELinux 的三種模式與上面談到的政策規則、安全本文的關係為何呢?我們還是使用圖示加上流程來讓大家理解一下:
就如上圖所示,首先,你得要知道,並不是所有的程序都會被 SELinux 所管制,因此最左邊會出現一個所謂的『有受限的程序主體』!那如何觀察有沒有受限 (confined )呢? 很簡單啊!就透過 ps -eZ 去擷取!舉例來說,我們來找一找 crond 與 bash 這兩隻程序是否有被限制吧?
[root@study ~]# ps -eZ | grep -E 'cron|bash'
system_u:system_r:crond_t:s0-s0:c0.c1023 1340 ? 00:00:00 atd
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 13888 tty2 00:00:00 bash
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 28054 pts/0 00:00:00 bash
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 28094 pts/0 00:00:00 bash
system_u:system_r:crond_t:s0-s0:c0.c1023 28174 ? 00:00:00 crond
如前所述,因為在目前 target 這個政策底下,只有第三個類型 (type) 欄位會有影響,因此我們上表僅列出第三個欄位的資料而已。 我們可以看到, crond 確實是有受限的主體程序,而 bash 因為是本機程序,因此就是不受限 (unconfined_t) 的類型!也就是說, bash 是不需要經過上圖的流程,而是直接去判斷 rwx 而已~。
了解了受限的主體程序的意義之後,再來了解一下,三種模式的運作吧!首先,如果是 Disabled 的模式,那麼 SELinux 將不會運作,當然受限的程序也不會經過 SELinux , 也是直接去判斷 rwx 而已。那如果是寬容 (permissive) 模式呢?這種模式也是不會將主體程序抵擋 (所以箭頭是可以直接穿透的喔!),不過萬一沒有通過政策規則,或者是安全本文的比對時, 那麼該讀寫動作將會被紀錄起來 (log),可作為未來檢查問題的判斷依據。
至於最終那個 Enforcing 模式,就是實際將受限主體進入規則比對、安全本文比對的流程,若失敗,就直接抵擋主體程序的讀寫行為,並且將他記錄下來。 如果通通沒問題,這才進入到 rwx 權限的判斷喔!這樣可以理解三種模式的行為了嗎?
那你怎麼知道目前的 SELinux 模式呢?就透過 getenforce 吧!
[root@study ~]# getenforce
Enforcing <==諾!就顯示出目前的模式為 Enforcing 囉!
另外,我們又如何知道 SELinux 的政策 (Policy) 為何呢?這時可以使用 sestatus 來觀察:
[root@study ~]# sestatus [-vb]
選項與參數:
-v :檢查列於 /etc/sestatus.conf 內的檔案與程序的安全性本文內容;
-b :將目前政策的規則布林值列出,亦即某些規則 (rule) 是否要啟動 (0/1) 之意;
範例一:列出目前的 SELinux 使用哪個政策 (Policy)?
[root@study ~]# sestatus
SELinux status: enabled <==是否啟動 SELinux
SELinuxfs mount: /sys/fs/selinux <==SELinux 的相關檔案資料掛載點
SELinux root directory: /etc/selinux <==SELinux 的根目錄所在
Loaded policy name: targeted <==目前的政策為何?
Current mode: enforcing <==目前的模式
Mode from config file: enforcing <==目前設定檔內規範的 SELinux 模式
Policy MLS status: enabled <==是否含有 MLS 的模式機制
Policy deny_unknown status: allowed <==是否預設抵擋未知的主體程序
Max kernel policy version: 28
如上所示,目前是啟動的,而且是 Enforcing 模式,而由設定檔查詢得知亦為 Enforcing 模式。 此外,目前的預設政策為 targeted 這一個。你應該要有疑問的是, SELinux 的設定檔是哪個檔案啊? 其實就是 /etc/selinux/config 這個檔案喔!我們來看看內容:
[root@study ~]# vim /etc/selinux/config
SELINUX=enforcing <==調整 enforcing|disabled|permissive
SELINUXTYPE=targeted <==目前僅有 targeted, mls, minimum 三種政策
若有需要修改預設政策的話,就直接改 SELINUX=enforcing 那一行即可喔!
SELinux 的啟動與關閉
上面是預設的政策與啟動的模式!你要注意的是,如果改變了政策則需要重新開機;如果由 enforcing 或 permissive 改成 disabled ,或由 disabled 改成其他兩個,那也必須要重新開機。這是因為 SELinux 是整合到核心裡面去的, 你只可以在 SELinux 運作下切換成為強制 (enforcing) 或寬容 (permissive) 模式,不能夠直接關閉 SELinux 的! 如果剛剛你發現 getenforce 出現 disabled 時,請到上述檔案修改成為 enforcing 然後重新開機吧!
不過你要注意的是,如果從 disable 轉到啟動 SELinux 的模式時, 由於系統必須要針對檔案寫入安全性本文的資訊,因此開機過程會花費不少時間在等待重新寫入 SELinux 安全性本文 (有時也稱為 SELinux Label) ,而且在寫完之後還得要再次的重新開機一次喔!你必須要等待粉長一段時間! 等到下次開機成功後,再使用 getenforce 或 sestatus 來觀察看看有否成功的啟動到 Enforcing 的模式囉!
如果你已經在 Enforcing 的模式,但是可能由於一些設定的問題導致 SELinux 讓某些服務無法正常的運作, 此時你可以將 Enforcing 的模式改為寬容 (permissive) 的模式,讓 SELinux 只會警告無法順利連線的訊息, 而不是直接抵擋主體程序的讀取權限。讓 SELinux 模式在 enforcing 與 permissive 之間切換的方法為:
[root@study ~]# setenforce [0|1]
選項與參數:
0 :轉成 permissive 寬容模式;
1 :轉成 Enforcing 強制模式
範例一:將 SELinux 在 Enforcing 與 permissive 之間切換與觀察
[root@study ~]# setenforce 0
[root@study ~]# getenforce
Permissive
[root@study ~]# setenforce 1
[root@study ~]# getenforce
Enforcing
不過請注意, setenforce 無法在 Disabled 的模式底下進行模式的切換喔!
Tips:在某些特殊的情況底下,你從 Disabled 切換成 Enforcing 之後,竟然有一堆服務無法順利啟動,都會跟你說在 /lib/xxx 裡面的資料沒有權限讀取,所以啟動失敗。這大多是由於在重新寫入 SELinux type (Relabel) 出錯之故,使用 Permissive 就沒有這個錯誤。那如何處理呢?最簡單的方法就是在 Permissive 的狀態下,使用『 restorecon -Rv / 』重新還原所有 SELinux 的類型,就能夠處理這個錯誤!
SELinux 政策內的規則管理
我們知道 SELinux 的三種模式是會影響到主體程序的放行與否。 如果是進入 Enforcing 模式,那麼接著下來會影響到主體程序的,當然就是第二關:『 target 政策內的各項規則 (rules) 』了! 好了,那麼我們怎麼知道目前這個政策裡面到底有多少會影響到主體程序的規則呢?很簡單,就透過 getsebool 來瞧一瞧即可。
- SELinux 各個規則的布林值查詢 getsebool
如果想要查詢系統上面全部規則的啟動與否 (on/off,亦即布林值),很簡單的透過 sestatus -b 或 getsebool -a 均可!
[root@study ~]# getsebool [-a] [規則的名稱]
選項與參數:
-a :列出目前系統上面的所有 SELinux 規則的布林值為開啟或關閉值
範例一:查詢本系統內所有的布林值設定狀況
[root@study ~]# getsebool -a
abrt_anon_write --> off
abrt_handle_event --> off
....(中間省略)....
cron_can_relabel --> off # 這個跟 cornd 比較有關!
cron_userdomain_transition --> on
....(中間省略)....
httpd_enable_homedirs --> off # 這當然就是跟網頁,亦即 http 有關的囉!
....(底下省略)....
# 這麼多的 SELinux 規則喔!每個規則後面都列出現在是允許放行還是不許放行的布林值喔!
- SELinux 各個規則規範的主體程序能夠讀取的檔案 SELinux type 查詢 seinfo, sesearch
我們現在知道有這麼多的 SELinux 規則,但是每個規則內到底是在限制什麼東西?如果你想要知道的話,那就得要使用 seinfo 等工具! 這些工具並沒有在我們安裝時就安裝了,因此請拿出原版光碟,放到光碟機,鳥哥假設你將原版光碟掛載到 /mnt 底下,那麼接下來這麼作, 先安裝好我們所需要的軟體才行!
[root@study ~]# yum install /mnt/Packages/setools-console-*
很快的安裝完畢之後,我們就可以來使用 seinfo, sesearch 等指令了!
[root@study ~]# seinfo [-trub]
選項與參數:
--all :列出 SELinux 的狀態、規則布林值、身份識別、角色、類別等所有資訊
-u :列出 SELinux 的所有身份識別 (user) 種類
-r :列出 SELinux 的所有角色 (role) 種類
-t :列出 SELinux 的所有類別 (type) 種類
-b :列出所有規則的種類 (布林值)
範例一:列出 SELinux 在此政策下的統計狀態
[root@study ~]# seinfo
Statistics for policy file: /sys/fs/selinux/policy
Policy Version & Type: v.28 (binary, mls)
Classes: 83 Permissions: 255
Sensitivities: 1 Categories: 1024
Types: 4620 Attributes: 357
Users: 8 Roles: 14
Booleans: 295 Cond. Expr.: 346
Allow: 102249 Neverallow: 0
Auditallow: 160 Dontaudit: 8413
Type_trans: 16863 Type_change: 74
Type_member: 35 Role allow: 30
Role_trans: 412 Range_trans: 5439
....(底下省略)....
# 從上面我們可以看到這個政策是 targeted ,此政策的安全本文類別有 4620 個;
# 而各種 SELinux 的規則 (Booleans) 共制訂了 295 條!
我們前面簡單的談到了幾個身份識別 (user) 以及角色 (role) 而已,如果你想要查詢目前所有的身份識別與角色,就使用『 seinfo -u 』及『 seinfo -r 』就可以知道了!至於簡單的統計資料,就直接輸入 seinfo 即可!但是上面還是沒有談到規則相關的東西耶~ 沒關係~一個一個來~我們在 16.5.1 的最後面談到 /etc/cron.d/checktime 的 SELinux type 類型不太對~那我們也知道 crond 這個程序的 type 是 crond_t , 能不能找一下 crond_t 能夠讀取的檔案 SELinux type 有哪些呢?
[root@study ~]# sesearch [-A] [-s 主體類別] [-t 目標類別] [-b 布林值]
選項與參數:
-A :列出後面資料中,允許『讀取或放行』的相關資料
-t :後面還要接類別,例如 -t httpd_t
-b :後面還要接SELinux的規則,例如 -b httpd_enable_ftp_server
範例一:找出 crond_t 這個主體程序能夠讀取的檔案 SELinux type
[root@study ~]# sesearch -A -s crond_t | grep spool
allow crond_t system_cron_spool_t : file { ioctl read write create getattr ..
allow crond_t system_cron_spool_t : dir { ioctl read getattr lock search op..
allow crond_t user_cron_spool_t : file { ioctl read write create getattr se..
allow crond_t user_cron_spool_t : dir { ioctl read write getattr lock add_n..
allow crond_t user_cron_spool_t : lnk_file { read getattr } ;
# allow 後面接主體程序以及檔案的 SELinux type,上面的資料是擷取出來的,
# 意思是說,crond_t 可以讀取 system_cron_spool_t 的檔案/目錄類型~等等!
範例二:找出 crond_t 是否能夠讀取 /etc/cron.d/checktime 這個我們自訂的設定檔?
[root@study ~]# ll -Z /etc/cron.d/checktime
-rw-r--r--. root root unconfined_u:object_r:admin_home_t:s0 /etc/cron.d/checktime
# 兩個重點,一個是 SELinux type 為 admin_home_t,一個是檔案 (file)
[root@study ~]# sesearch -A -s crond_t | grep admin_home_t
allow domain admin_home_t : dir { getattr search open } ;
allow domain admin_home_t : lnk_file { read getattr } ;
allow crond_t admin_home_t : dir { ioctl read getattr lock search open } ;
allow crond_t admin_home_t : lnk_file { read getattr } ;
# 仔細看!看仔細~雖然有 crond_t admin_home_t 存在,但是這是總體的資訊,
# 並沒有針對某些規則的尋找~所以還是不確定 checktime 能否被讀取。但是,基本上就是 SELinux
# type 出問題~因此才會無法讀取的!
所以,現在我們知道 /etc/cron.d/checktime 這個我們自己複製過去的檔案會沒有辦法被讀取的原因,就是因為 SELinux type 錯誤啦! 根本就無法被讀取~好~那現在我們來查一查,那 getsebool -a 裡面看到的 httpd_enable_homedirs 到底是什麼?又是規範了哪些主體程序能夠讀取的 SELinux type 呢?
[root@study ~]# semanage boolean -l | grep httpd_enable_homedirs
SELinux boolean State Default Description
httpd_enable_homedirs (off , off) Allow httpd to enable homedirs
# httpd_enable_homedirs 的功能是允許 httpd 程序去讀取使用者家目錄的意思~
[root@study ~]# sesearch -A -b httpd_enable_homedirs
範例三:列出 httpd_enable_homedirs 這個規則當中,主體程序能夠讀取的檔案 SELinux type
Found 43 semantic av rules:
allow httpd_t home_root_t : dir { ioctl read getattr lock search open } ;
allow httpd_t home_root_t : lnk_file { read getattr } ;
allow httpd_t user_home_type : dir { getattr search open } ;
allow httpd_t user_home_type : lnk_file { read getattr } ;
....(後面省略)....
# 從上面的資料才可以理解,在這個規則中,主要是放行 httpd_t 能否讀取使用者家目錄的檔案!
# 所以,如果這個規則沒有啟動,基本上, httpd_t 這種程序就無法讀取使用者家目錄下的檔案!
- 修改 SELinux 規則的布林值 setsebool
那麼如果查詢到某個 SELinux rule,並且以 sesearch 知道該規則的用途後,想要關閉或啟動他,又該如何處置?
[root@study ~]# setsebool [-P] 『規則名稱』 [0|1]
選項與參數:
-P :直接將設定值寫入設定檔,該設定資料未來會生效的!
範例一:查詢 httpd_enable_homedirs 這個規則的狀態,並且修改這個規則成為不同的布林值
[root@study ~]# getsebool httpd_enable_homedirs
httpd_enable_homedirs --> off <==結果是 off ,依題意給他啟動看看!
[root@study ~]# setsebool -P httpd_enable_homedirs 1 # 會跑很久很久!請耐心等待!
[root@study ~]# getsebool httpd_enable_homedirs
httpd_enable_homedirs --> on
這個 setsebool 最好記得一定要加上 -P 的選項!因為這樣才能將此設定寫入設定檔! 這是非常棒的工具組!你一定要知道如何使用 getsebool 與 setsebool 才行!
SELinux 安全本文的修改
現在我們知道 SELinux 對受限的主體程序有沒有影響,第一關考慮 SELinux 的三種類型,第二關考慮 SELinux 的政策規則是否放行,第三關則是開始比對 SELinux type 啦!從剛剛我們也知道可以透過 sesearch 來找到主體程序與檔案的 SELinux type 關係! 好,現在總算要來修改檔案的 SELinux type,以讓主體程序能夠讀到正確的檔案啊!這時就得要幾個重要的小東西了~來瞧瞧~
使用 chcon 手動修改檔案的 SELinux type
[root@study ~]# chcon [-R] [-t type] [-u user] [-r role] 檔案
[root@study ~]# chcon [-R] --reference=範例檔 檔案
選項與參數:
-R :連同該目錄下的次目錄也同時修改;
-t :後面接安全性本文的類型欄位!例如 httpd_sys_content_t ;
-u :後面接身份識別,例如 system_u; (不重要)
-r :後面接角色,例如 system_r; (不重要)
-v :若有變化成功,請將變動的結果列出來
--reference=範例檔:拿某個檔案當範例來修改後續接的檔案的類型!
範例一:查詢一下 /etc/hosts 的 SELinux type,並將該類型套用到 /etc/cron.d/checktime 上
[root@study ~]# ll -Z /etc/hosts
-rw-r--r--. root root system_u:object_r:net_conf_t:s0 /etc/hosts
[root@study ~]# chcon -v -t net_conf_t /etc/cron.d/checktime
changing security context of ‘/etc/cron.d/checktime’
[root@study ~]# ll -Z /etc/cron.d/checktime
-rw-r--r--. root root unconfined_u:object_r:net_conf_t:s0 /etc/cron.d/checktime
範例二:直接以 /etc/shadow SELinux type 套用到 /etc/cron.d/checktime 上!
[root@study ~]# chcon -v --reference=/etc/shadow /etc/cron.d/checktime
[root@study ~]# ll -Z /etc/shadow /etc/cron.d/checktime
-rw-r--r--. root root system_u:object_r:shadow_t:s0 /etc/cron.d/checktime
----------. root root system_u:object_r:shadow_t:s0 /etc/shadow
上面的練習『都沒有正確的解答!』因為正確的 SELinux type 應該就是要以 /etc/cron.d/ 底下的檔案為標準來處理才對啊~ 好了~既然如此~能不能讓 SELinux 自己解決預設目錄下的 SELinux type 呢?可以!就用 restorecon 吧!
使用 restorecon 讓檔案恢復正確的 SELinux type
[root@study ~]# restorecon [-Rv] 檔案或目錄
選項與參數:
-R :連同次目錄一起修改;
-v :將過程顯示到螢幕上
範例三:將 /etc/cron.d/ 底下的檔案通通恢復成預設的 SELinux type!
[root@study ~]# restorecon -Rv /etc/cron.d
restorecon reset /etc/cron.d/checktime context system_u:object_r:shadow_t:s0->
system_u:object_r:system_cron_spool_t:s0
# 上面這兩行其實是同一行喔!表示將 checktime 由 shadow_t 改為 system_cron_spool_t
範例四:重新啟動 crond 看看有沒有正確啟動 checktime 囉!?
[root@study ~]# systemctl restart crond
[root@study ~]# tail /var/log/cron
# 再去瞧瞧這個 /var/log/cron 的內容,應該就沒有錯誤訊息了
其實,鳥哥幾乎已經忘了 chcon 這個指令了!因為 restorecon 主動的回復預設的 SELinux type 要簡單很多!而且可以一口氣恢復整個目錄下的檔案! 所以,鳥哥建議你幾乎只要記得 restorecon 搭配 -Rv 同時加上某個目錄這樣的指令串即可~修改 SELinux 的 type 就變得非常的輕鬆囉!
semanage 預設目錄的安全性本文查詢與修改
你應該要覺得奇怪,為什麼 restorecon 可以『恢復』原本的 SELinux type 呢?那肯定就是有個地方在紀錄每個檔案/目錄的 SELinux 預設類型囉? 沒錯!是這樣~那要如何 (1)查詢預設的 SELinux type 以及 (2)如何增加/修改/刪除預設的 SELinux type 呢?很簡單~透過 semanage 即可!他是這樣使用的:
[root@study ~]# semanage {login|user|port|interface|fcontext|translation} -l
[root@study ~]# semanage fcontext -{a|d|m} [-frst] file_spec
選項與參數:
fcontext :主要用在安全性本文方面的用途, -l 為查詢的意思;
-a :增加的意思,你可以增加一些目錄的預設安全性本文類型設定;
-m :修改的意思;
-d :刪除的意思。
範例一:查詢一下 /etc /etc/cron.d 的預設 SELinux type 為何?
[root@study ~]# semanage fcontext -l | grep -E '^/etc |^/etc/cron'
SELinux fcontext type Context
/etc all files system_u:object_r:etc_t:s0
/etc/cron\.d(/.*)? all files system_u:object_r:system_cron_spool_t:s0
看到上面輸出的最後一行,那也是為啥我們直接使用 vim 去 /etc/cron.d 底下建立新檔案時,預設的 SELinux type 就是正確的! 同時,我們也會知道使用 restorecon 回復正確的 SELinux type 時,系統會去判斷預設的類型為何的依據。現在讓我們來想一想, 如果 (當然是假的!不可能這麼幹) 我們要建立一個 /srv/mycron 的目錄,這個目錄預設也是需要變成 system_cron_spool_t 時, 我們應該要如何處理呢?基本上可以這樣作:
# 1. 先建立 /srv/mycron 同時在內部放入設定檔,同時觀察 SELinux type
[root@study ~]# mkdir /srv/mycron
[root@study ~]# cp /etc/cron.d/checktime /srv/mycron
[root@study ~]# ll -dZ /srv/mycron /srv/mycron/checktime
drwxr-xr-x. root root unconfined_u:object_r:var_t:s0 /srv/mycron
-rw-r--r--. root root unconfined_u:object_r:var_t:s0 /srv/mycron/checktime
# 2. 觀察一下上層 /srv 的 SELinux type
[root@study ~]# semanage fcontext -l | grep '^/srv'
SELinux fcontext type Context
/srv all files system_u:object_r:var_t:s0
# 怪不得 mycron 會是 var_t 囉!
# 3. 將 mycron 預設值改為 system_cron_spool_t 囉!
[root@study ~]# semanage fcontext -a -t system_cron_spool_t "/srv/mycron(/.*)?"
[root@study ~]# semanage fcontext -l | grep '^/srv/mycron'
SELinux fcontext type Context
/srv/mycron(/.*)? all files system_u:object_r:system_cron_spool_t:s0
# 4. 恢復 /srv/mycron 以及子目錄相關的 SELinux type 喔!
[root@study ~]# restorecon -Rv /srv/mycron
[root@study ~]# ll -dZ /srv/mycron /srv/mycron/*
drwxr-xr-x. root root unconfined_u:object_r:system_cron_spool_t:s0 /srv/mycron
-rw-r--r--. root root unconfined_u:object_r:system_cron_spool_t:s0 /srv/mycron/checktime
# 有了預設值,未來就不會不小心被亂改了!這樣比較妥當些~
semanage 的功能很多,不過鳥哥主要用到的僅有 fcontext 這個項目的動作而已。如上所示, 你可以使用 semanage 來查詢所有的目錄預設值,也能夠使用他來增加預設值的設定!如果您學會這些基礎的工具, 那麼 SELinux 對你來說,也不是什麼太難的咚咚囉!
一個網路服務案例及登錄檔協助
本章在 SELinux 小節當中談到的各個指令中,尤其是 setsebool, chcon, restorecon 等,都是為了當你的某些網路服務無法正常提供相關功能時, 才需要進行修改的一些指令動作。但是,我們怎麼知道哪個時候才需要進行這些指令的修改啊?我們怎麼知道系統因為 SELinux 的問題導致網路服務不對勁啊?如果都要靠用戶端連線失敗才來哭訴,那也太沒有效率了!所以,我們的 CentOS 7.x 有提供幾支偵測的服務在登錄 SELinux 產生的錯誤喔!那就是 auditd 與 setroubleshootd。
- setroubleshoot –> 錯誤訊息寫入 /var/log/messages
幾乎所有 SELinux 相關的程式都會以 se 為開頭,這個服務也是以 se 為開頭!而 troubleshoot 大家都知道是錯誤克服,因此這個 setroubleshoot 自然就得要啟動他啦!這個服務會將關於 SELinux 的錯誤訊息與克服方法記錄到 /var/log/messages 與 /var/log/setroubleshoot/* 裡頭,所以你一定得要啟動這個服務才好。啟動這個服務之前當然就是得要安裝它啦! 這玩意兒總共需要兩個軟體,分別是 setroublshoot 與 setroubleshoot-server,如果你沒有安裝,請自行使用 yum 安裝吧!
此外,原本的 SELinux 資訊本來是以兩個服務來記錄的,分別是 auditd 與 setroubleshootd。既然是同樣的資訊,因此 CentOS 6.x (含 7.x) 以後將兩者整合在 auditd 當中啦!所以,並沒有 setroubleshootd 的服務存在了喔!因此,當你安裝好了 setroubleshoot-server 之後,請記得要重新啟動 auditd,否則 setroubleshootd 的功能不會被啟動的。
Tips:事實上,CentOS 7.x 對 setroubleshootd 的運作方式是: (1)先由 auditd 去呼叫 audispd 服務, (2)然後 audispd 服務去啟動 sedispatch 程式, (3)sedispatch 再將原本的 auditd 訊息轉成 setroubleshootd 的訊息,進一步儲存下來的!
[root@study ~]# rpm -qa | grep setroubleshoot
setroubleshoot-plugins-3.0.59-1.el7.noarch
setroubleshoot-3.2.17-3.el7.x86_64
setroubleshoot-server-3.2.17-3.el7.x86_64
在預設的情況下,這個 setroubleshoot 應該都是會安裝的!是否正確安裝可以使用上述的表格指令去查詢。萬一沒有安裝,請使用 yum install 去安裝吧! 再說一遍,安裝完畢最好重新啟動 auditd 這個服務喔!不過,剛剛裝好且順利啟動後, setroubleshoot 還是不會有作用,為啥? 因為我們並沒有任何受限的網路服務主體程序在運作啊!所以,底下我們將使用一個簡單的 FTP 伺服器軟體為例,讓你了解到我們上頭講到的許多重點的應用!
- 實例狀況說明:透過 vsftpd 這個 FTP 伺服器來存取系統上的檔案
現在的年輕小伙子們傳資料都用 line, FB, dropbox, google 雲端磁碟等等,不過在網路早期傳送大容量的檔案,還是以 FTP 這個協定為主! 現在為了速度,經常有 p2p 的軟體提供大容量檔案的傳輸,但以鳥哥這個老人家來說,可能 FTP 傳送資料還是比較有保障… 在 CentOS 7.x 的環境下,達成 FTP 的預設伺服器軟體主要是 vsftpd 這一支喔!
詳細的 FTP 協定我們在伺服器篇再來談,這裡只是簡單的利用 vsftpd 這個軟體與 FTP 的協定來講解 SELinux 的問題與錯誤克服而已。 不過既然要使用到 FTP 協定,一些簡單的知識還是得要存在才好!否則等一下我們沒有辦法了解為啥要這麼做! 首先,你得要知道,用戶端需要使用『FTP 帳號登入 FTP 伺服器』才行!而有一個稱為『匿名 (anonymous) 』的帳號可以登入系統! 但是這個匿名的帳號登入後,只能存取某一個特定的目錄,而無法脫離該目錄~!
在 vsftpd 中,一般用戶與匿名者的家目錄說明如下:
- 匿名者:如果使用瀏覽器來連線到 FTP 伺服器的話,那預設就是使用匿名者登入系統。而匿名者的家目錄預設是在 /var/ftp 當中! 同時,匿名者在家目錄下只能下載資料,不能上傳資料到 FTP 伺服器。同時,匿名者無法離開 FTP 伺服器的 /var/ftp 目錄喔!
- 一般 FTP 帳號:在預設的情況下,所有 UID 大於 1000 的帳號,都可以使用 FTP 來登入系統! 而登入系統之後,所有的帳號都能夠取得自己家目錄底下的檔案資料!當然預設是可以上傳、下載檔案的!
為了避免跟之前章節的用戶產生誤解的情況,這裡我們先建立一個名為 ftptest 的帳號,且帳號密碼為 myftp123, 先來建立一下吧!
[root@study ~]# useradd -s /sbin/nologin ftptest
[root@study ~]# echo "myftp123" | passwd --stdin ftptest
接下來當然就是安裝 vsftpd 這隻伺服器軟體,同時啟動這隻服務,另外,我們也希望未來開機都能夠啟動這隻服務! 因此需要這樣做 (鳥哥假設你的 CentOS 7.x 的原版光碟已經掛載於 /mnt 了喔!):
[root@study ~]# yum install /mnt/Packages/vsftpd-3*
[root@study ~]# systemctl start vsftpd
[root@study ~]# systemctl enable vsftpd
[root@study ~]# netstat -tlnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1326/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2349/master
tcp6 0 0 :::21 :::* LISTEN 6256/vsftpd
tcp6 0 0 :::22 :::* LISTEN 1326/sshd
tcp6 0 0 ::1:25 :::* LISTEN 2349/master
# 要注意看,上面的特殊字體那行有出現,才代表 vsftpd 這隻服務有啟動喔!!
- 匿名者無法下載的問題
現在讓我們來模擬一些 FTP 的常用狀態!假設你想要將 /etc/securetty 以及主要的 /etc/sysctl.conf 放置給所有人下載, 那麼你可能會這樣做!
[root@study ~]# cp -a /etc/securetty /etc/sysctl.conf /var/ftp/pub
[root@study ~]# ll /var/ftp/pub
-rw-------. 1 root root 221 Oct 29 2014 securetty # 先假設你沒有看到這個問題!
-rw-r--r--. 1 root root 225 Mar 6 11:05 sysctl.conf
一般來說,預設要給用戶下載的 FTP 檔案會放置到上面表格當中的 /var/ftp/pub 目錄喔!現在讓我們使用簡單的終端機瀏覽器 curl 來觀察看看! 看你能不能查詢到上述兩個檔案的內容呢?
# 1. 先看看 FTP 根目錄底下有什麼檔案存在?
[root@study ~]# curl ftp://localhost
drwxr-xr-x 2 0 0 40 Aug 08 00:51 pub
# 確實有存在一個名為 pub 的檔案喔!那就是在 /var/ftp 底下的 pub 囉!
# 2. 再往下看看,能不能看到 pub 內的檔案呢?
[root@study ~]# curl ftp://localhost/pub/ # 因為是目錄,要加上 / 才好!
-rw------- 1 0 0 221 Oct 29 2014 securetty
-rw-r--r-- 1 0 0 225 Mar 06 03:05 sysctl.conf
# 3. 承上,繼續看一下 sysctl.conf 的內容好了!
[root@study ~]# curl ftp://localhost/pub/sysctl.conf
# System default settings live in /usr/lib/sysctl.d/00-system.conf.
# To override those settings, enter new settings here, or in an /etc/sysctl.d/<name>.conf file
#
# For more information, see sysctl.conf(5) and sysctl.d(5).
# 真的有看到這個檔案的內容喔!所以確定是可以讓 vsftpd 讀取到這檔案的!
# 4. 再來瞧瞧 securetty 好了!
[root@study ~]# curl ftp://localhost/pub/securetty
curl: (78) RETR response: 550
# 看不到耶!但是,基本的原因應該是權限問題喔!因為 vsftpd 預設放在 /var/ftp/pub 內的資料,
# 不論什麼 SELinux type 幾乎都可以被讀取的才對喔!所以要這樣處理!
# 5. 修訂權限之後再一次觀察 securetty 看看!
[root@study ~]# chmod a+r /var/ftp/pub/securetty
[root@study ~]# curl ftp://localhost/pub/securetty
# 此時你就可以看到實際的檔案內容囉!
# 6. 修訂 SELinux type 的內容 (非必備)
[root@study ~]# restorecon -Rv /var/ftp
上面這個例子在告訴你,要先從權限的角度來瞧一瞧,如果無法被讀取,可能就是因為沒有 r 或沒有 rx 囉!並不一定是由 SELinux 引起的! 了解乎?好~再來瞧瞧如果是一般帳號呢?如何登入?
- 無法從家目錄下載檔案的問題分析與解決
我們前面建立了 ftptest 帳號,那如何使用文字界面來登入呢?就使用如下的方式來處理。同時請注意,因為文字型的 FTP 用戶端軟體, 預設會將用戶丟到根目錄而不是家目錄,因此,你的 URL 可能需要修訂一下如下!
# 0. 為了讓 curl 這個文字瀏覽器可以傳輸資料,我們先建立一些資料在 ftptest 家目錄
[root@study ~]# echo "testing" > ~ftptest/test.txt
[root@study ~]# cp -a /etc/hosts /etc/sysctl.conf ~ftptest/
[root@study ~]# ll ~ftptest/
-rw-r--r--. 1 root root 158 Jun 7 2013 hosts
-rw-r--r--. 1 root root 225 Mar 6 11:05 sysctl.conf
-rw-r--r--. 1 root root 8 Aug 9 01:05 test.txt
# 1. 一般帳號直接登入 FTP 伺服器,同時變換目錄到家目錄去!
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/
-rw-r--r-- 1 0 0 158 Jun 07 2013 hosts
-rw-r--r-- 1 0 0 225 Mar 06 03:05 sysctl.conf
-rw-r--r-- 1 0 0 8 Aug 08 17:05 test.txt
# 真的有資料~看檔案最左邊的權限也是沒問題,所以,來讀一下 test.txt 的內容看看
# 2. 開始下載 test.txt, sysctl.conf 等有權限可以閱讀的檔案看看!
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/test.txt
curl: (78) RETR response: 550
# 竟然說沒有權限!明明我們的 rwx 是正常沒問題!那是否有可能是 SELinux 造成的?
# 3. 先將 SELinux 從 Enforce 轉成 Permissive 看看情況!同時觀察登錄檔
[root@study ~]# setenforce 0
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/test.txt
testing
[root@study ~]# setenforce 1 # 確定問題後,一定要轉成 Enforcing 啊!
# 確定有資料內容!所以,確定就是 SELinux 造成無法讀取的問題~那怎辦?要改規則?還是改 type?
# 因為都不知道,所以,就檢查一下登錄檔看看有沒有相關的資訊可以提供給我們處理!
[root@study ~]# vim /var/log/messages
Aug 9 02:55:58 station3-39 setroubleshoot: SELinux is preventing /usr/sbin/vsftpd
from lock access on the file /home/ftptest/test.txt. For complete SELinux messages.
run sealert -l 3a57aad3-a128-461b-966a-5bb2b0ffa0f9
Aug 9 02:55:58 station3-39 python: SELinux is preventing /usr/sbin/vsftpd from
lock access on the file /home/ftptest/test.txt.
***** Plugin catchall_boolean (47.5 confidence) suggests ******************
If you want to allow ftp to home dir
Then you must tell SELinux about this by enabling the 'ftp_home_dir' boolean.
You can read 'None' man page for more details.
Do
setsebool -P ftp_home_dir 1
***** Plugin catchall_boolean (47.5 confidence) suggests ******************
If you want to allow ftpd to full access
Then you must tell SELinux about this by enabling the 'ftpd_full_access' boolean.
You can read 'None' man page for more details.
Do
setsebool -P ftpd_full_access 1
***** Plugin catchall (6.38 confidence) suggests **************************
.....(底下省略).....
# 基本上,你會看到有個特殊字體的部份,就是 sealert 那一行。雖然底下已經列出可能的解決方案了,
# 就是一堆底線那些東西。至少就有三個解決方案 (最後一個沒列出來),哪種才是正確的?
# 為了了解正確的解決方案,我們還是還執行一下 sealert 那行吧!看看情況再說!
# 4. 透過 sealert 的解決方案來處理問題
[root@study ~]# sealert -l 3a57aad3-a128-461b-966a-5bb2b0ffa0f9
SELinux is preventing /usr/sbin/vsftpd from lock access on the file /home/ftptest/test.txt.
# 底下說有 47.5% 的機率是由於這個原因所發生,並且可以使用 setsebool 去解決的意思!
***** Plugin catchall_boolean (47.5 confidence) suggests ******************
If you want to allow ftp to home dir
Then you must tell SELinux about this by enabling the 'ftp_home_dir' boolean.
You can read 'None' man page for more details.
Do
setsebool -P ftp_home_dir 1
# 底下說也是有 47.5% 的機率是由此產生的!
***** Plugin catchall_boolean (47.5 confidence) suggests ******************
If you want to allow ftpd to full access
Then you must tell SELinux about this by enabling the 'ftpd_full_access' boolean.
You can read 'None' man page for more details.
Do
setsebool -P ftpd_full_access 1
# 底下說,僅有 6.38% 的可信度是由這個情況產生的!
***** Plugin catchall (6.38 confidence) suggests **************************
If you believe that vsftpd should be allowed lock access on the test.txt file by default.
Then you should report this as a bug.
You can generate a local policy module to allow this access.
Do
allow this access for now by executing:
# grep vsftpd /var/log/audit/audit.log | audit2allow -M mypol
# semodule -i mypol.pp
# 底下就重要了!是整個問題發生的主因~最好還是稍微瞧一瞧!
Additional Information:
Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023
Target Context unconfined_u:object_r:user_home_t:s0
Target Objects /home/ftptest/test.txt [ file ]
Source vsftpd
Source Path /usr/sbin/vsftpd
Port <Unknown>
Host station3-39.gocloud.vm
Source RPM Packages vsftpd-3.0.2-9.el7.x86_64
Target RPM Packages
Policy RPM selinux-policy-3.13.1-23.el7.noarch
Selinux Enabled True
Policy Type targeted
Enforcing Mode Permissive
Host Name station3-39.gocloud.vm
Platform Linux station3-39.gocloud.vm 3.10.0-229.el7.x86_64
#1 SMP Fri Mar 6 11:36:42 UTC 2015 x86_64 x86_64
Alert Count 3
First Seen 2015-08-09 01:00:12 CST
Last Seen 2015-08-09 02:55:57 CST
Local ID 3a57aad3-a128-461b-966a-5bb2b0ffa0f9
Raw Audit Messages
type=AVC msg=audit(1439060157.358:635): avc: denied { lock } for pid=5029 comm="vsftpd"
path="/home/ftptest/test.txt" dev="dm-2" ino=141 scontext=system_u:system_r:ftpd_t:s0-s0:
c0.c1023 tcontext=unconfined_u:object_r:user_home_t:s0 tclass=file
type=SYSCALL msg=audit(1439060157.358:635): arch=x86_64 syscall=fcntl success=yes exit=0
a0=4 a1=7 a2=7fffceb8cbb0 a3=0 items=0 ppid=5024 pid=5029 auid=4294967295 uid=1001 gid=1001
euid=1001 suid=1001 fsuid=1001 egid=1001 sgid=1001 fsgid=1001 tty=(none) ses=4294967295
comm=vsftpd exe=/usr/sbin/vsftpd subj=system_u:system_r:ftpd_t:s0-s0:c0.c1023 key=(null)
Hash: vsftpd,ftpd_t,user_home_t,file,lock
經過上面的測試,現在我們知道主要的問題發生在 SELinux 的 type 不是 vsftpd_t 所能讀取的原因~ 經過仔細觀察 test.txt 檔案的類型,我們知道他原本就是家目錄,因此是 user_home_t 也沒啥了不起的啊!是正確的~ 因此,分析兩個比較可信 (47.5%) 的解決方案後,可能是與 ftp_home_dir 比較有關啊!所以,我們應該不需要修改 SELinux type, 修改的應該是 SELinux rules 才對!所以,這樣做看看:
# 1. 先確認一下 SELinux 的模式,然後再瞧一瞧能否下載 test.txt,最終使用處理方式來解決~
[root@study ~]# getenforce
Enforcing
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/test.txt
curl: (78) RETR response: 550
# 確定還是無法讀取的喔!
[root@study ~]# setsebool -P ftp_home_dir 1
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/test.txt
testing
# OK!太讚了!處理完畢!現在使用者可以在自己的家目錄上傳/下載檔案了!
# 2. 開始下載其他檔案試看看囉!
[root@study ~]# curl ftp://ftptest:myftp123@localhost/~/sysctl.conf
# System default settings live in /usr/lib/sysctl.d/00-system.conf.
# To override those settings, enter new settings here, or in an /etc/sysctl.d/<name>.conf file
#
# For more information, see sysctl.conf(5) and sysctl.d(5).
沒問題喔!透過修改 SELinux rule 的布林值,現在我們就可以使用一般帳號在 FTP 服務來上傳/下載資料囉!非常愉快吧! 那萬一我們還有其他的目錄也想要透過 FTP 來提供這個 ftptest 用戶上傳與下載呢?往下瞧瞧~
- 一般帳號用戶從非正規目錄上傳/下載檔案
假設我們還想要提供 /srv/gogogo 這個目錄給 ftptest 用戶使用,那又該如何處理呢?假設我們都沒有考慮 SELinux , 那就是這樣的情況:
# 1. 先處理好所需要的目錄資料
[root@study ~]# mkdir /srv/gogogo
[root@study ~]# chgrp ftptest /srv/gogogo
[root@study ~]# echo "test" > /srv/gogogo/test.txt
# 2. 開始直接使用 ftp 觀察一下資料!
[root@study ~]# curl ftp://ftptest:myftp123@localhost//srv/gogogo/test.txt
curl: (78) RETR response: 550
# 有問題喔!來瞧瞧登錄檔怎麼說!
[root@study ~]# grep sealert /var/log/messages | tail
Aug 9 04:23:12 station3-39 setroubleshoot: SELinux is preventing /usr/sbin/vsftpd from
read access on the file test.txt. For complete SELinux messages. run sealert -l
08d3c0a2-5160-49ab-b199-47a51a5fc8dd
[root@study ~]# sealert -l 08d3c0a2-5160-49ab-b199-47a51a5fc8dd
SELinux is preventing /usr/sbin/vsftpd from read access on the file test.txt.
# 雖然這個可信度比較高~不過,因為會全部放行 FTP ,所以不太考慮!
***** Plugin catchall_boolean (57.6 confidence) suggests ******************
If you want to allow ftpd to full access
Then you must tell SELinux about this by enabling the 'ftpd_full_access' boolean.
You can read 'None' man page for more details.
Do
setsebool -P ftpd_full_access 1
# 因為是非正規目錄的使用,所以這邊加上預設 SELinux type 恐怕會是比較正確的選擇!
***** Plugin catchall_labels (36.2 confidence) suggests *******************
If you want to allow vsftpd to have read access on the test.txt file
Then you need to change the label on test.txt
Do
# semanage fcontext -a -t FILE_TYPE 'test.txt'
where FILE_TYPE is one of the following: NetworkManager_tmp_t, abrt_helper_exec_t, abrt_tmp_t,
abrt_upload_watch_tmp_t, abrt_var_cache_t, abrt_var_run_t, admin_crontab_tmp_t, afs_cache_t,
alsa_home_t, alsa_tmp_t, amanda_tmp_t, antivirus_home_t, antivirus_tmp_t, apcupsd_tmp_t, ...
Then execute:
restorecon -v 'test.txt'
***** Plugin catchall (7.64 confidence) suggests **************************
If you believe that vsftpd should be allowed read access on the test.txt file by default.
Then you should report this as a bug.
You can generate a local policy module to allow this access.
Do
allow this access for now by executing:
# grep vsftpd /var/log/audit/audit.log | audit2allow -M mypol
# semodule -i mypol.pp
Additional Information:
Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023
Target Context unconfined_u:object_r:var_t:s0
Target Objects test.txt [ file ]
Source vsftpd
.....(底下省略).....
因為是非正規目錄啊,所以感覺上似乎與 semanage 那一行的解決方案比較相關~接下來就是要找到 FTP 的 SELinux type 來解決囉! 所以,讓我們查一下 FTP 相關的資料囉!
# 3. 先查看一下 /var/ftp 這個地方的 SELinux type 吧!
[root@study ~]# ll -Zd /var/ftp
drwxr-xr-x. root root system_u:object_r:public_content_t:s0 /var/ftp
# 4. 以 sealert 建議的方法來處理好 SELinux type 囉!
[root@study ~]# semanage fcontext -a -t public_content_t "/srv/gogogo(/.*)?"
[root@study ~]# restorecon -Rv /srv/gogogo
[root@study ~]# curl ftp://ftptest:myftp123@localhost//srv/gogogo/test.txt
test
# 喔耶!終於再次搞定喔!
在這個範例中,我們是修改了 SELinux type 喔!與前一個修改 SELinux rule 不太一樣!要理解理解喔!
- 無法變更 FTP 連線埠口問題分析與解決
在某些情況下,可能你的伺服器軟體需要開放在非正規的埠口,舉例來說,如果因為某些政策問題,導致 FTP 啟動的正常的 21 號埠口無法使用, 因此你想要啟用在 555 號埠口時,該如何處理呢?基本上,既然 SELinux 的主體程序大多是被受限的網路服務,沒道理不限制放行的埠口啊! 所以,很可能會出問題~那就得要想想辦法才行!
# 1. 先處理 vsftpd 的設定檔,加入換 port 的參數才行!
[root@study ~]# vim /etc/vsftpd/vsftpd.conf
# 請按下大寫的 G 跑到最後一行,然後新增加底下這行設定!前面不可以留白!
listen_port=555
# 2. 重新啟動 vsftpd 並且觀察登錄檔的變化!
[root@study ~]# systemctl restart vsftpd
[root@study ~]# grep sealert /var/log/messages
Aug 9 06:34:46 station3-39 setroubleshoot: SELinux is preventing /usr/sbin/vsftpd from
name_bind access on the tcp_socket port 555. For complete SELinux messages. run
sealert -l 288118e7-c386-4086-9fed-2fe78865c704
[root@study ~]# sealert -l 288118e7-c386-4086-9fed-2fe78865c704
SELinux is preventing /usr/sbin/vsftpd from name_bind access on the tcp_socket port 555.
***** Plugin bind_ports (92.2 confidence) suggests ************************
If you want to allow /usr/sbin/vsftpd to bind to network port 555
Then you need to modify the port type.
Do
# semanage port -a -t PORT_TYPE -p tcp 555
where PORT_TYPE is one of the following: certmaster_port_t, cluster_port_t,
ephemeral_port_t, ftp_data_port_t, ftp_port_t, hadoop_datanode_port_t, hplip_port_t,
port_t, postgrey_port_t, unreserved_port_t.
.....(後面省略).....
# 看一下信任度,高達 92.2% 耶!幾乎就是這傢伙~因此不必再看~就是他了!比較重要的是,
# 解決方案裡面,那個 PORT_TYPE 有很多選擇~但我們是要開啟 FTP 埠口嘛!所以,
# 就由後續資料找到 ftp_port_t 那個項目囉!帶入實驗看看!
# 3. 實際帶入 SELinux 埠口修訂後,在重新啟動 vsftpd 看看
[root@study ~]# semanage port -a -t ftp_port_t -p tcp 555
[root@study ~]# systemctl restart vsftpd
[root@study ~]# netstat -tlnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1167/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1598/master
tcp6 0 0 :::555 :::* LISTEN 8436/vsftpd
tcp6 0 0 :::22 :::* LISTEN 1167/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1598/master
# 4. 實驗看看這個 port 能不能用?
[root@study ~]# curl ftp://localhost:555/pub/
-rw-r--r-- 1 0 0 221 Oct 29 2014 securetty
-rw-r--r-- 1 0 0 225 Mar 06 03:05 sysctl.conf
透過上面的幾個小練習,你會知道在正規或非正規的環境下,如何處理你的 SELinux 問題哩!仔細研究看看囉!
Swap
【譯】替 swap 辯護:常見的誤解
這篇翻譯自 Chris Down 的博文 In defence of swap: common misconceptions 。
翻譯這篇文章是因爲經常看到朋友們(包括有經驗的程序員和 Linux 管理員)對 swap 和 swappiness 有諸多誤解,而這篇文章正好澄清了這些誤解,也講清楚了 Linux 中這兩者的本質。值得一提的是本文討論的 swap 針對 Linux 內核,在別的系統包括 macOS/WinNT 或者 Unix 系統中的交換文件可能有不同一樣的行爲, 需要不同的調優方式。比如在 FreeBSD handbook 中明確建議了 swap 分區通常應該是兩倍物理內存大小,這一點建議對 FreeBSD 系內核的內存管理可能非常合理, 而不一定適合 Linux 內核,FreeBSD 和 Linux 有不同的內存管理方式尤其是 swap 和 page cache 和 buffer cache 的處理方式有諸多不同。
經常有朋友看到系統卡頓之後看系統內存使用狀況觀察到大量 swap 佔用,於是覺得卡頓是來源於 swap 。就像文中所述,相關不蘊含因果,產生內存顛簸之後的確會造成大量 swap 佔用,也會造成系統卡頓, 但是 swap 不是導致卡頓的原因,關掉 swap 或者調低 swappiness 並不能阻止卡頓,只會將 swap 造成的 I/O 轉化爲加載文件緩存造成的 I/O 。
以下是原文翻譯:
太長不看:
- 對維持系統的正常功能而言,有 swap 是相對挺重要的一部分。沒有它的話會更難做到合理的內存管理。
- swap 的目的通常並不是用作緊急內存,它的目的在於讓內存回收能更平等和高效。 事實上把它當作「緊急內存」來用的想法通常是有害的。
- 禁用 swap 在內存壓力下並不能避免磁盤I/O造成的性能問題,這麼做只是讓磁盤I/O顛簸的範圍從 匿名頁面轉化到文件頁面。這不僅更低效,因爲系統能回收的頁面的選擇範圍更有限了, 而且這種做法還可能是加重了內存壓力的原因之一。
- 內核 4.0 版本之前的交換進程(swapper)有一些問題,導致很多人對 swap 有負面印象, 因爲它太急於(overeagerness)把頁面交換出去。在 4.0 之後的內核上這種情況已經改善了很多。
- 在 SSD 上,交換出匿名頁面的開銷和回收文件頁面的開銷基本上在性能/延遲方面沒有區別。 在老式的磁盤上,讀取交換文件因爲屬於隨機訪問讀取所以會更慢,於是設置較低的
vm.swappiness可能比較合理(繼續讀下面關於vm.swappiness的描述)。 - 禁用 swap 並不能避免在接近 OOM 狀態下最終表現出的症狀,儘管的確有 swap 的情況下這種症狀持續的時間可能會延長。在系統調用 OOM 殺手的時候無論有沒有啓用 swap ,或者更早/更晚開始調用 OOM 殺手,結果都是一樣的:整個系統留在了一種不可預知的狀態下。 有 swap 也不能避免這一點。
- 可以用 cgroup v2 的
memory.low相關機制來改善內存壓力下 swap 的行爲並且 避免發生顛簸。
我的工作的一部分是改善內核中內存管理和 cgroup v2 相關,所以我和很多工程師討論過看待內存管理的態度, 尤其是在壓力下應用程序的行爲和操作系統在底層內存管理中用的基於經驗的啓發式決策邏輯。
在這種討論中經常重複的話題是交換區(swap)。交換區的話題是非常有爭議而且很少被理解的話題,甚至包括那些在 Linux 上工作過多年的人也是如此。很多人覺得它沒什麼用甚至是有害的:它是歷史遺蹟,從內存緊缺而 磁盤讀寫是必要之惡的時代遺留到現在,爲計算機提供在當年很必要的頁面交換功能作爲內存空間。 最近幾年我還經常能以一定頻度看到這種論調,然後我和很多同事、朋友、業界同行們討論過很多次, 幫他們理解爲什麼在現代計算機系統中交換區仍是有用的概念,即便現在的電腦中物理內存已經遠多於過去。
圍繞交換區的目的還有很多誤解——很多人覺得它只是某種爲了應對緊急情況的「慢速額外內存」, 但是沒能理解在整個操作系統健康運作的時候它也能改善普通負載的性能。
我們很多人也聽說過描述內存時所用的常見說法: 「 Linux 用了太多內存 」,「 swap 應該設爲物理內存的兩倍大小 」,或者類似的說法。 雖然這些誤解要麼很容易化解,或者關於他們的討論在最近幾年已經逐漸變得瑣碎,但是關於「無用」交換區 的傳言有更深的經驗傳承的根基,而不是一兩個類比就能解釋清楚的,並且要探討這個先得對內存管理有 一些基礎認知。
本文主要目標是針對那些管理 Linux 系統並且有興趣理解「讓系統運行於低/無交換區狀態」或者「把 vm.swappiness 設爲 0 」這些做法的反論。
背景
如果沒有基本理解 Linux 內存管理的底層機制是如何運作的,就很難討論爲什麼需要交換區以及交換出頁面 對正常運行的系統爲什麼是件好事,所以我們先確保大家有討論的基礎。
內存的類型
Linux 中內存分爲好幾種類型,每種都有各自的屬性。想理解爲什麼交換區很重要的關鍵一點在於理解這些的細微區別。
比如說,有種 頁面(「整塊」的內存,通常 4K) 是用來存放電腦裏每個程序運行時各自的代碼的。 也有頁面用來保存這些程序所需要讀取的文件數據和元數據的緩存,以便加速隨後的文件讀寫。 這些內存頁面構成 頁面緩存(page cache),後文中我稱他們爲文件內存。
還有一些頁面是在代碼執行過程中做的內存分配得到的,比如說,當代碼調用 malloc 能分配到新內存區,或者使用 mmap 的 MAP_ANONYMOUS 標誌分配的內存。 這些是「匿名(anonymous)」頁面——之所以這麼稱呼它們是因爲他們沒有任何東西作後備—— 後文中我稱他們爲匿名內存。
還有其它類型的內存——共享內存、slab內存、內核棧內存、文件緩衝區(buffers),這種的—— 但是匿名內存和文件內存是最知名也最好理解的,所以後面的例子裏我會用這兩個說明, 雖然後面的說明也同樣適用於別的這些內存類型。
可回收/不可回收內存
考慮某種內存的類型時,一個非常基礎的問題是這種內存是否能被回收。 「回收(Reclaim)」在這裏是指系統可以,在不丟失數據的前提下,從物理內存中釋放這種內存的頁面。
對一些內存類型而言,是否可回收通常可以直接判斷。比如對於那些乾淨(未修改)的頁面緩存內存, 我們只是爲了性能在用它們緩存一些磁盤上現有的數據,所以我們可以直接扔掉這些頁面, 不需要做什麼特殊的操作。
對有些內存類型而言,回收是可能的,但是不是那麼直接。比如對髒(修改過)的頁面緩存內存, 我們不能直接扔掉這些頁面,因爲磁盤上還沒有寫入我們所做的修改。這種情況下,我們可以選擇拒絕回收, 或者選擇先等待我們的變更寫入磁盤之後才能扔掉這些內存。
對還有些內存類型而言,是不能回收的。比如前面提到的匿名頁面,它們只存在於內存中,沒有任何後備存儲, 所以它們必須留在內存裏。
說到交換區的本質
如果你去搜 Linux 上交換區的目的的描述,肯定會找到很多人說交換區只是在緊急時用來擴展物理內存的機制。 比如下面這段是我在 google 中輸入「什麼是 swap」 從前排結果中隨機找到的一篇:
交換區本質上是緊急內存;是爲了應對你的系統臨時所需內存多餘你現有物理內存時,專門分出一塊額外空間。 大家覺得交換區「不好」是因爲它又慢又低效,並且如果你的系統一直需要使用交換區那說明它明顯沒有足夠的內存。 [……]如果你有足夠內存覆蓋所有你需要的情況,而且你覺得肯定不會用滿內存,那麼完全可以不用交換區 安全地運行系統。
事先說明,我不想因爲這些文章的內容責怪這些文章的作者——這些內容被很多 Linux 系統管理員認爲是「常識」, 並且很可能你問他們什麼是交換區的時候他們會給你這樣的回答。但是也很不幸的是, 這種認識是使用交換區的目的的一種普遍誤解,尤其在現代系統上。
前文中我說過回收匿名頁面的內存是「不可能的」,因爲匿名內存的特點,把它們從內存中清除掉之後, 沒有別的存儲區域能作爲他們的備份——因此,要回收它們會造成數據丟失。但是,如果我們爲這種內存頁面創建 一種後備存儲呢?
嗯,這正是交換區存在的意義。交換區是一塊存儲空間,用來讓這些看起來「不可回收」的內存頁面在需要的時候 可以交換到存儲設備上。這意味着有了交換區之後,這些匿名頁面也和別的那些可回收內存一樣, 可以作爲內存回收的候選,就像乾淨文件頁面,從而允許更有效地使用物理內存。
交換區主要是爲了平等的回收機制,而不是爲了緊急情況的「額外內存」。使用交換區不會讓你的程序變慢—— 進入內存競爭的狀態才是讓程序變慢的元兇。
那麼在這種「平等的可回收機遇」的情況下,讓我們選擇回收匿名頁面的行爲在何種場景中更合理呢? 抽象地說,比如在下述不算罕見的場景中:
- 程序初始化的時候,那些長期運行的程序可能要分配和使用很多頁面。這些頁面可能在最後的關閉/清理的 時候還需要使用,但是在程序「啓動」之後(以具體的程序相關的方式)持續運行的時候不需要訪問。 對後臺服務程序來說,很多後臺程序要初始化不少依賴庫,這種情況很常見。
- 在程序的正常運行過程中,我們可能分配一些很少使用的內存。對整體系統性能而言可能比起讓這些內存頁 一直留在內存中,只有在用到的時候才按需把它們用 缺頁異常(major fault) 換入內存, 可以空出更多內存留給更重要的東西。
考察有無交換區時會發生什麼
我們來看一些在常見場景中,有無交換區時分別會如何運行。 在我的 關於 cgroup v2 的演講 中探討過「內存競爭」的指標。
在無/低內存競爭的狀態下
- 有交换区: 我們可以選擇換出那些只有在進程生存期內很小一部分時間會訪問的匿名內存, 這允許我們空出更多內存空間用來提升緩存命中率,或者做別的優化。
- 無交換區: 我們不能換出那些很少使用的匿名內存,因爲它們被鎖在了內存中。雖然這通常不會直接表現出問題, 但是在一些工作條件下這可能造成卡頓導致不平凡的性能下降,因爲匿名內存佔着空間不能給 更重要的需求使用。
譯註:關於 內存熱度 和 內存顛簸(thrash)
討論內核中內存管理的時候經常會說到內存頁的 冷熱 程度。這裏冷熱是指歷史上內存頁被訪問到的頻度, 內存管理的經驗在說,歷史上在近期頻繁訪問的 熱 內存,在未來也可能被頻繁訪問, 從而應該留在物理內存裏;反之歷史上不那麼頻繁訪問的 冷 內存,在未來也可能很少被用到, 從而可以考慮交換到磁盤或者丟棄文件緩存。
顛簸(thrash) 這個詞在文中出現多次但是似乎沒有詳細介紹,實際計算機科學專業的課程中應該有講過。 一段時間內,讓程序繼續運行所需的熱內存總量被稱作程序的工作集(workset),估算工作集大小, 換句話說判斷進程分配的內存頁中哪些屬於 熱 內存哪些屬於 冷 內存,是內核中 內存管理的最重要的工作。當分配給程序的內存大於工作集的時候,程序可以不需要等待I/O全速運行; 而當分配給程序的內存不足以放下整個工作集的時候,意味着程序每執行一小段就需要等待換頁或者等待 磁盤緩存讀入所需內存頁,產生這種情況的時候,從用戶角度來看可以觀察到程序肉眼可見的「卡頓」。 當系統中所有程序都內存不足的時候,整個系統都處於顛簸的狀態下,響應速度直接降至磁盤I/O的帶寬。 如本文所說,禁用交換區並不能防止顛簸,只是從等待換頁變成了等待文件緩存, 給程序分配超過工作集大小的內存才能防止顛簸。
在中/高內存競爭的狀態下
- 有交换区: 所有內存類型都有平等的被回收的可能性。這意味着我們回收頁面有更高的成功率—— 成功回收的意思是說被回收的那些頁面不會在近期內被缺頁異常換回內存中(顛簸)。
- 無交換區: 匿名內存因爲無處可去所以被鎖在內存中。長期內存回收的成功率變低了,因爲我們成體上 能回收的頁面總量少了。發生缺頁顛簸的危險性更高了。缺乏經驗的讀者可能覺得這某時也是好事, 因爲這能避免進行磁盤I/O,但是實際上不是如此——我們只是把交換頁面造成的磁盤I/O變成了扔掉熱緩存頁 和扔掉代碼段,這些頁面很可能馬上又要從文件中讀回來。
在臨時內存佔用高峰時
- 有交换区: 我們對內存使用激增的情況更有抵抗力,但是在嚴重的內存不足的情況下, 從開始發生內存顛簸到 OOM 殺手開始工作的時間會被延長。內存壓力造成的問題更容易觀察到, 從而可能更有效地應對,或者更有機會可控地干預。
- 無交換區: 因爲匿名內存被鎖在內存中了不能被回收,所以 OOM 殺手會被更早觸發。 發生內存顛簸的可能性更大,但是發生顛簸之後到 OOM 解決問題的時間間隔被縮短了。 基於你的程序,這可能更好或是更糟。比如說,基於隊列的程序可能更希望這種從顛簸到殺進程的轉換更快發生。 即便如此,發生 OOM 的時機通常還是太遲於是沒什麼幫助——只有在系統極度內存緊缺的情況下才會請出 OOM 殺手,如果想依賴這種行爲模式,不如換成更早殺進程的方案,因爲在這之前已經發生內存競爭了。
好吧,所以我需要系統交換區,但是我該怎麼爲每個程序微調它的行爲?
你肯定想到了我寫這篇文章一定會在哪兒插點 cgroup v2 的安利吧? ;-)
顯然,要設計一種對所有情況都有效的啓發算法會非常難,所以給內核提一些指引就很重要。 歷史上我們只能在整個系統層面做這方面微調,通過 vm.swappiness 。這有兩方面問題: vm.swappiness 的行爲很難準確控制,因爲它只是傳遞給一個更大的啓發式算法中的一個小參數; 並且它是一個系統級別的設置,沒法針對一小部分進程微調。
你可以用 mlock 把頁面鎖在內存裏,但是這要麼必須改程序代碼,或者折騰 LD_PRELOAD ,或者在運行期用調試器做一些魔法操作。對基於虛擬機的語言來說這種方案也不能 很好工作,因爲通常你沒法控制內存分配,最後得用上 mlockall ,而這個沒有辦法精確指定你實際上想鎖住的頁面。
cgroup v2 提供了一套可以每個 cgroup 微調的 memory.low ,允許我們告訴內核說當使用的內存低於一定閾值之後優先回收別的程序的內存。這可以讓我們不強硬禁止內核 換出程序的一部分內存,但是當發生內存競爭的時候讓內核優先回收別的程序的內存。在正常條件下, 內核的交換邏輯通常還是不錯的,允許它有條件地換出一部分頁面通常可以改善系統性能。在內存競爭的時候 發生交換顛簸雖然不理想,但是這更多地是單純因爲整體內存不夠了,而不是因爲交換進程(swapper)導致的問題。 在這種場景下,你通常希望在內存壓力開始積攢的時候通過自殺一些非關鍵的進程的方式來快速退出(fail fast)。
你不能依賴 OOM 殺手達成這個。 OOM 殺手只有在非常急迫的情況下纔會出動,那時系統已經處於極度不健康的 狀態了,而且很可能在這種狀態下保持了一陣子了。需要在開始考慮 OOM 殺手之前,積極地自己處理這種情況。
不過,用傳統的 Linux 內存統計數據還是挺難判斷內存壓力的。我們有一些看起來相關的系統指標,但是都 只是支離破碎的——內存用量、頁面掃描,這些——單純從這些指標很難判斷系統是處於高效的內存利用率還是 在滑向內存競爭狀態。我們在 Facebook 有個團隊,由 Johannes 牽頭,努力開發一些能評價內存壓力的新指標,希望能在今後改善目前的現狀。 如果你對這方面感興趣, 在我的 cgroup v2 的演講中介紹到一個被提議的指標 。
調優
那麼,我需要多少交換空間?
通常而言,最優內存管理所需的最小交換空間取決於程序固定在內存中而又很少訪問到的匿名頁面的數量, 以及回收這些匿名頁面換來的價值。後者大體上來說是問哪些頁面不再會因爲要保留這些很少訪問的匿名頁面而 被回收掉騰出空間。
如果你有足夠大的磁盤空間和比較新的內核版本(4.0+),越大的交換空間基本上總是越好的。 更老的內核上 kswapd , 內核中負責管理交換區的內核線程,在歷史上傾向於有越多交換空間就 急於交換越多內存出去。在最近一段時間,可用交換空間很大的時候的交換行爲已經改善了很多。 如果在運行 4.0+ 以後的內核,即便有很大的交換區在現代內核上也不會很激進地做交換。因此, 如果你有足夠的容量,現代內核上有個幾個 GB 的交換空間大小能讓你有更多選擇。
如果你的磁盤空間有限,那麼答案更多取決於你願意做的取捨,以及運行的環境。理想上應該有足夠的交換空間 能高效應對正常負載和高峰(內存)負載。我建議先用 2-3GB 或者更多的交換空間搭個測試環境, 然後監視在不同(內存)負載條件下持續一週左右的情況。只要在那一週裏沒有發生過嚴重的內存不足—— 發生了的話說明測試結果沒什麼用——在測試結束的時候大概會留有多少 MB 交換區佔用。 作爲結果說明你至少應該有那麼多可用的交換空間,再多加一些以應對負載變化。用日誌模式跑 atop 可以在 SWAPSZ 欄顯示程序的頁面被交換出去的情況,所以如果你還沒用它記錄服務器歷史日誌的話 ,這次測試中可以試試在測試機上用它記錄日誌。這也會告訴你什麼時候你的程序開始換出頁面,你可以用這個 對照事件日誌或者別的關鍵數據。
另一點值得考慮的是交換空間所在存儲設備的媒介。讀取交換區傾向於很隨機,因爲我們不能可靠預測什麼時候 什麼頁面會被再次訪問。在 SSD 上這不是什麼問題,但是在傳統磁盤上,隨機 I/O 操作會很昂貴, 因爲需要物理動作尋道。另一方面,重新加載文件緩存可能不那麼隨機,因爲單一程序在運行期的文件讀操作 一般不會太碎片化。這可能意味着在傳統磁盤上你想更多地回收文件頁面而不是換出匿名頁面,但仍舊, 你需要做測試評估在你的工作負載下如何取得平衡。
譯註:關於休眠到磁盤時的交換空間大小
原文這裏建議交換空間至少是物理內存大小,我覺得實際上不需要。休眠到磁盤的時候內核會寫回並丟棄 所有有文件作後備的可回收頁面,交換區只需要能放下那些沒有文件後備的頁面就可以了。 如果去掉文件緩存頁面之後剩下的已用物理內存總量能完整放入交換區中,就可以正常休眠。 對於桌面瀏覽器這種內存大戶,通常有很多緩存頁可以在休眠的時候丟棄。
對筆記本/桌面用戶如果想要休眠到交換區,這也需要考慮——這種情況下你的交換文件應該至少是物理內存大小。
我的 swappiness 應該如何設置?
首先很重要的一點是,要理解 vm.swappiness 是做什麼的。 vm.swappiness 是一個 sysctl 用來控制在內存回收的時候,是優先回收匿名頁面, 還是優先回收文件頁面。內存回收的時候用兩個屬性: file_prio (回收文件頁面的傾向) 和 anon_prio (回收匿名頁面的傾向)。 vm.swappiness 控制這兩個值, 因爲它是 anon_prio 的默認值,然後也是默認 200 減去它之後 file_prio 的默認值。 意味着如果我們設置 vm.swappiness = 50 那麼結果是 anon_prio 是 50, file_prio 是 150 (這裏數值本身不是很重要,重要的是兩者之間的權重比)。
譯註:關於 SSD 上的 swappiness
原文這裏說 SSD 上 swap 和 drop page cache 差不多開銷所以
vm.swappiness = 100。我覺得實際上要考慮 swap out 的時候會產生寫入操作,而 drop page cache 可能不需要寫入( 要看頁面是否是髒頁)。如果負載本身對I/O帶寬比較敏感,稍微調低 swappiness 可能對性能更好, 內核的默認值 60 是個不錯的默認值。以及桌面用戶可能對性能不那麼關心,反而更關心 SSD 的寫入壽命,雖然說 SSD 寫入壽命一般也足夠桌面用戶,不過調低 swappiness 可能也能減少一部分不必要的寫入(因爲寫回髒頁是必然會發生的,而寫 swap 可以避免)。 當然太低的 swappiness 會對性能有負面影響(因爲太多匿名頁面留在物理內存裏而降低了緩存命中率) ,這裏的權衡也需要根據具體負載做測試。另外澄清一點誤解, swap 分區還是 swap 文件對系統運行時的性能而言沒有差別。或許有人會覺得 swap 文件要經過文件系統所以會有性能損失,在譯文之前譯者說過 Linux 的內存管理子系統基本上獨立於文件系統。 實際上 Linux 上的 swapon 在設置 swap 文件作爲交換空間的時候會讀取一次文件系統元數據, 確定 swap 文件在磁盤上的地址範圍,隨後運行的過程中做交換就和文件系統無關了。關於 swap 空間是否連續的影響,因爲 swap 讀寫基本是頁面單位的隨機讀寫,所以即便連續的 swap 空間(swap 分區)也並不能改善 swap 的性能。希疏文件的地址範圍本身不連續,寫入希疏文件的空洞需要 文件系統分配磁盤空間,所以在 Linux 上交換文件不能是希疏文件。只要不是希疏文件, 連續的文件內地址範圍在磁盤上是否連續(是否有文件碎片)基本不影響能否 swapon 或者使用 swap 時的性能。
這意味着,通常來說 vm.swappiness 只是一個比例,用來衡量在你的硬件和工作負載下, 回收和換回匿名內存還是文件內存哪種更昂貴 。設定的值越低,你就是在告訴內核說換出那些不常訪問的 匿名頁面在你的硬件上開銷越昂貴;設定的值越高,你就是在告訴內核說在你的硬件上交換匿名頁和 文件緩存的開銷越接近。內存管理子系統仍然還是會根據實際想要回收的內存的訪問熱度嘗試自己決定具體是 交換出文件還是匿名頁面,只不過 swappiness 會在兩種回收方式皆可的時候,在計算開銷權重的過程中左右 是該更多地做交換還是丟棄緩存。在 SSD 上這兩種方式基本上是同等開銷,所以設成 vm.swappiness = 100 (同等比重)可能工作得不錯。在傳統磁盤上,交換頁面可能會更昂貴, 因爲通常需要隨機讀取,所以你可能想要設低一些。
現實是大部分人對他們的硬件需求沒有什麼感受,所以根據直覺調整這個值可能挺困難的 —— 你需要用不同的值做測試。你也可以花時間評估一下你的系統的內存分配情況和核心應用在大量回收內存的時候的行爲表現。
討論 vm.swappiness 的時候,一個極爲重要需要考慮的修改是(相對)近期在 2012 年左右 Satoru Moriya 對 vmscan 行爲的修改 ,它顯著改變了代碼對 vm.swappiness = 0 這個值的處理方式。
基本上來說這個補丁讓我們在 vm.swappiness = 0 的時候會極度避免掃描(進而回收)匿名頁面, 除非我們已經在經歷嚴重的內存搶佔。就如本文前面所屬,這種行爲基本上不會是你想要的, 因爲這種行爲會導致在發生內存搶佔之前無法保證內存回收的公平性,這甚至可能是最初導致發生內存搶佔的原因。 想要避免這個補丁中對掃描匿名頁面的特殊行爲的話, vm.swappiness = 1 是你能設置的最低值。
內核在這裏設置的默認值是 vm.swappiness = 60 。這個值對大部分工作負載來說都不會太壞, 但是很難有一個默認值能符合所有種類的工作負載。因此,對上面「 那麼,我需要多少交換空間? 」那段討論的一點重要擴展可以說,在測試系統中可以嘗試使用不同的 vm.swappiness ,然後監視你的程序和系統在重(內存)負載下的性能指標。在未來某天,如果我們在內核中有了合理的 缺頁檢測 ,你也將能通過 cgroup v2 的頁面缺頁 指標來以負載無關的方式決定這個。
SREcon19 Asia/Pacific - Linux Memory Management at Scale: Under the Hood
2019年07月更新:內核 4.20+ 中的內存壓力指標
前文中提到的開發中的內存缺頁檢測指標已經進入 4.20+ 以上版本的內核,可以通過 CONFIG_PSI=y 開啓。詳情參見我在 SREcon 大約 25:05 左右的討論。
結論
- 交換區是允許公平地回收內存的有用工具,但是它的目的經常被人誤解,導致它在業內這種負面聲譽。如果 你是按照原本的目的使用交換區的話——作爲增加內存回收公平性的方式——你會發現它是很有效的工具而不是阻礙。
- 禁用交換區並不能在內存競爭的時候防止磁盤I/O的問題,它只不過把匿名頁面的磁盤I/O變成了文件頁面的 磁盤I/O。這不僅更低效,因爲我們回收內存的時候能選擇的頁面範圍更小了,而且它可能是導致高度內存競爭 狀態的元兇。
- 有交換區會導致系統更慢地使用 OOM 殺手,因爲在缺少內存的情況下它提供了另一種更慢的內存, 會持續地內存顛簸——內核調用 OOM 殺手只是最後手段,會晚於所有事情已經被搞得一團糟之後。 解決方案取決於你的系統:
- 你可以預先更具每個 cgroup 的或者系統全局的內存壓力改變系統負載。這能防止我們最初進入內存競爭 的狀態,但是 Unix 的歷史中一直缺乏可靠的內存壓力檢測方式。希望不久之後在有了 缺頁檢測 這樣的性能指標之後能改善這一點。
- 你可以使用
memory.low讓內核不傾向於回收(進而交換)特定一些 cgroup 中的進程, 允許你在不禁用交換區的前提下保護關鍵後臺服務。